Basis van Natural Language Processing (NLP)
Natural Language Processing met spaCy

Azadeh Mobasher
Principal Data Scientist
Natural Language Processing (NLP)
NLP-toepassingen
Sentimentanalyse
- Computers bepalen de onderliggende subjectieve toon van een tekst

NLP-toepassingen
Named entity recognition (NER)
- Het vinden en classificeren van benoemde entiteiten in ongestructureerde tekst in vooraf gedefinieerde categorieën
- Benoemde entiteiten zijn echte objecten zoals personen of locaties

NLP-toepassingen
- Genereer mensachtige reacties op tekstinput, zoals ChatGPT

Introductie tot spaCy

Tekst lezen en verwerken met spaCy
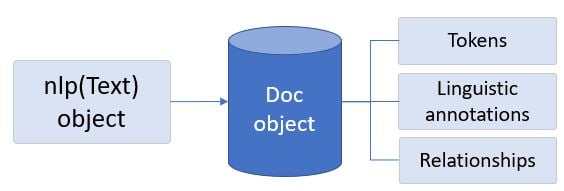
spaCy-modelen_core_web_smgeladen =nlp-objectnlpzet tekst om in eenDoc-object (container) met verwerkte tekst