Voorafgaande overtuiging
Bayesian Data Analysis in Python

Michal Oleszak
Machine Learning Engineer
Invloed van de prior
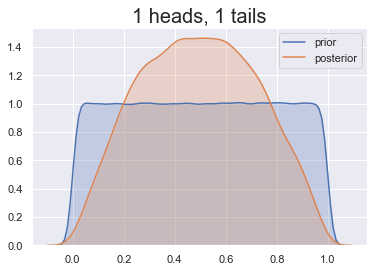
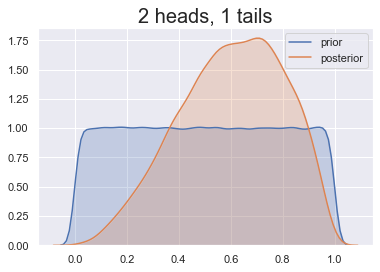
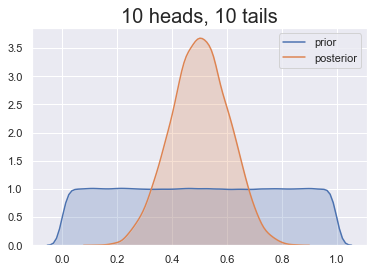
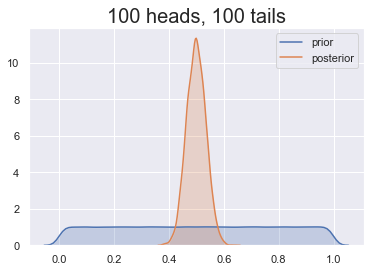
De juiste prior kiezen
Onze prior: kop is minder waarschijnlijk
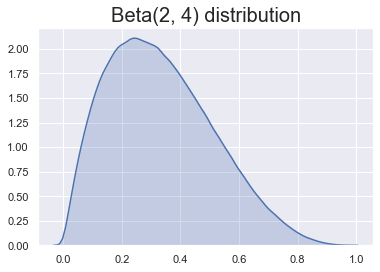
Sommige keuzes zijn beter dan andere!
Bayesian Data Analysis in Python
Michal Oleszak
Machine Learning Engineer
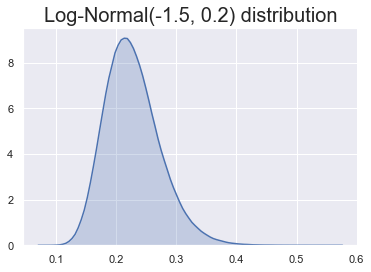
Onze prior: kop is minder waarschijnlijk
Sommige keuzes zijn beter dan andere!

