Regressie en forecasting
Bayesian Data Analysis in Python

Michal Oleszak
Machine Learning Engineer
Normale verdeling

Normale verdeling

Normale verdeling
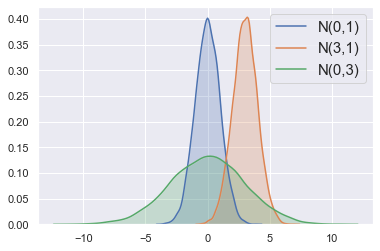
Posterior plotten
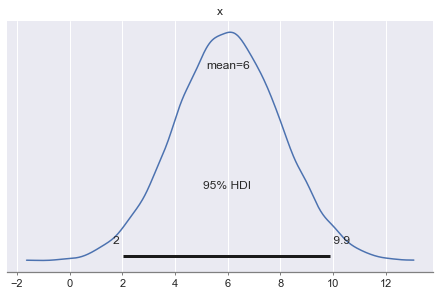
Predictieve verdeling
Hoeveel sales verwachten we bij $1000 marketinguitgaven?