Resultaten interpreteren en modellen vergelijken
Bayesian Data Analysis in Python

Michal Oleszak
Machine Learning Engineer
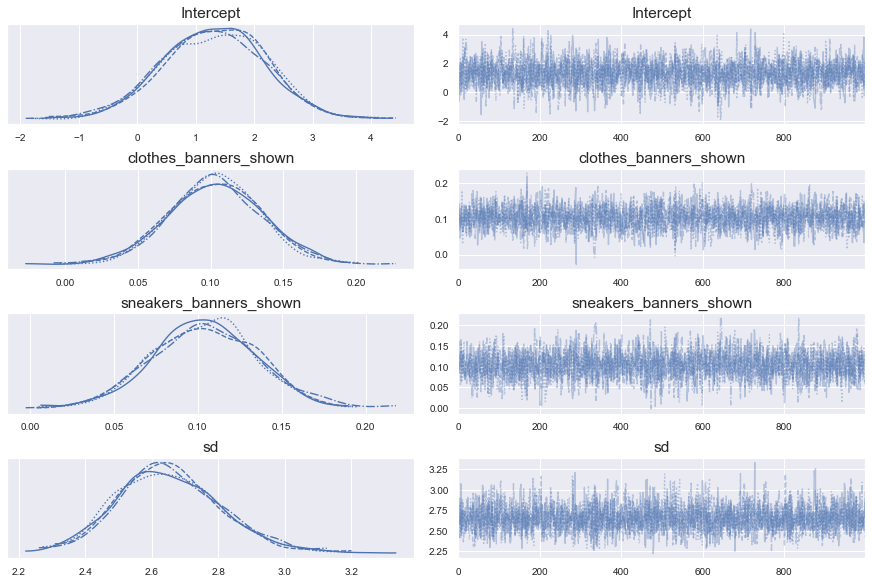
Traceplot
pm.traceplot(trace_1)
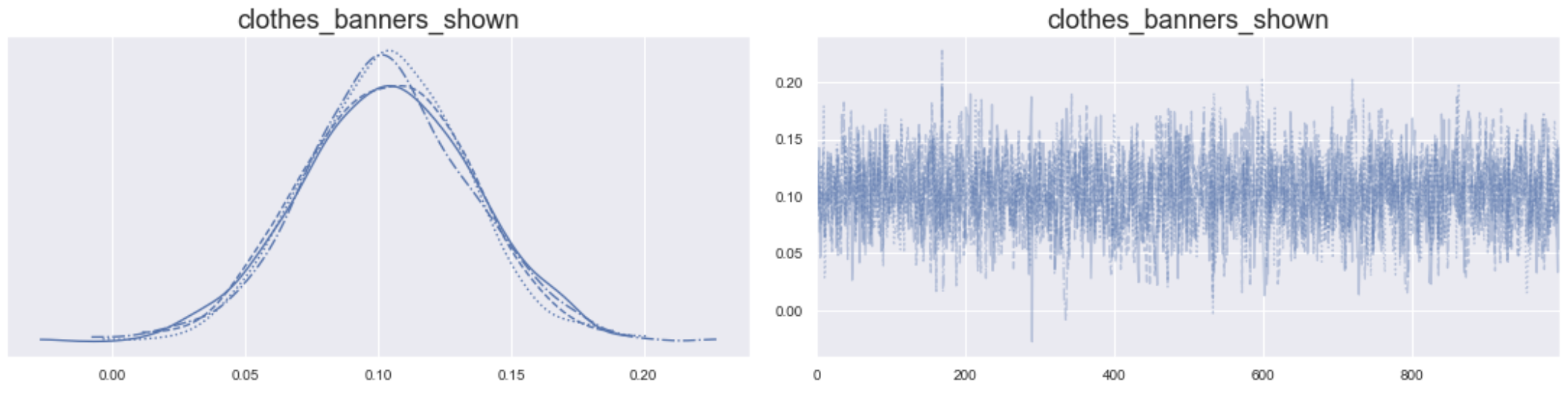
Traceplot: inzoomen op één parameter
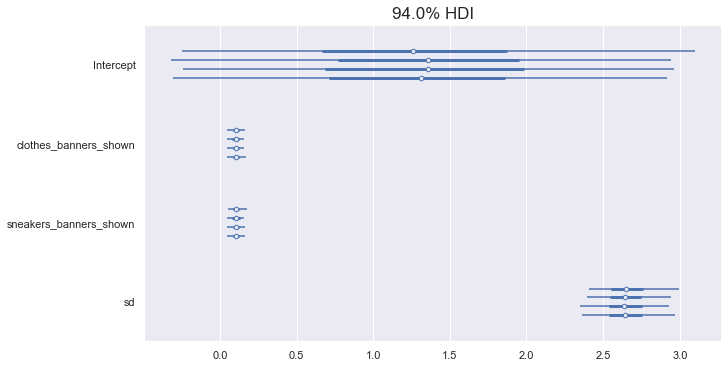
Forest plot
pm.forestplot(trace_1)
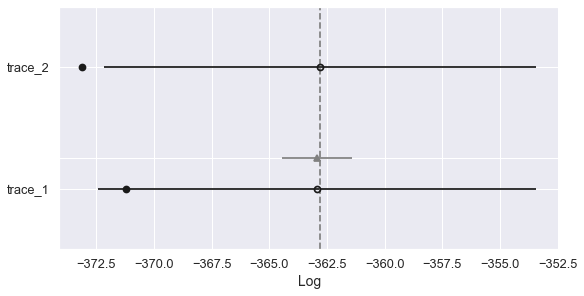
Vergelijkingsplot
pm.compareplot(comparison)