Parametrische schatting
Kwantitatief risicobeheer in Python

Jamsheed Shorish
Computational Economist
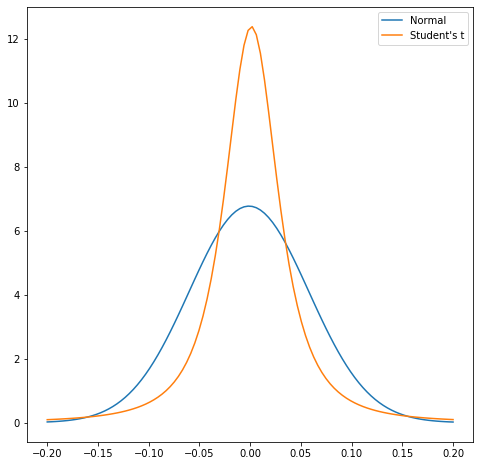
Goodness-of-fit
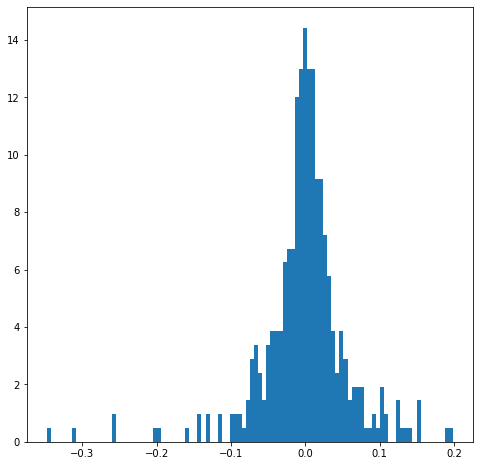
Goodness-of-fit
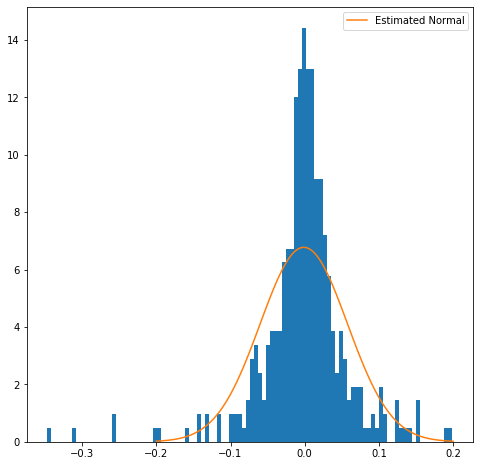
Goodness-of-fit
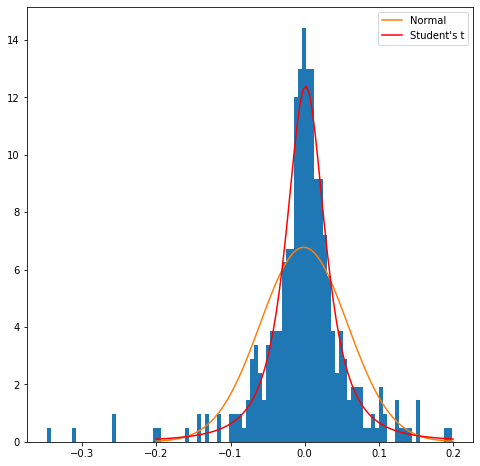
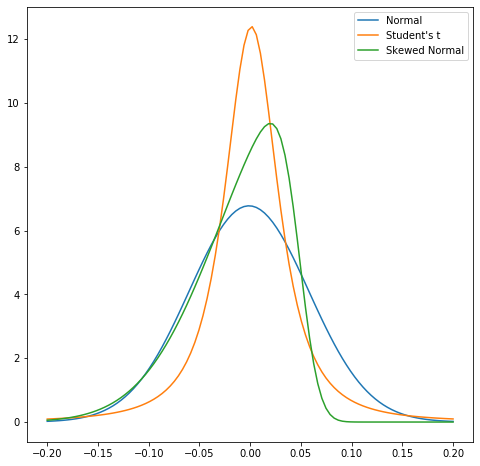
Scheefheid
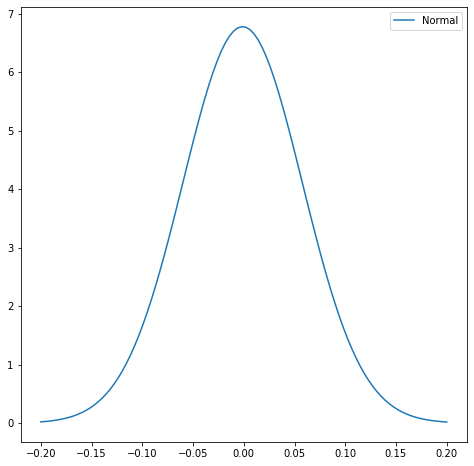
Scheefheid
Scheefheid
Kwantitatief risicobeheer in Python
Jamsheed Shorish
Computational Economist

