ARIMA-modellen
Voorspellen in R

Rob J. Hyndman
Professor of Statistics at Monash University
Netto-elektriciteitsproductie VS
autoplot(usnetelec) +
xlab("Year") +
ylab("billion kwh") +
ggtitle("US net electricity generation")
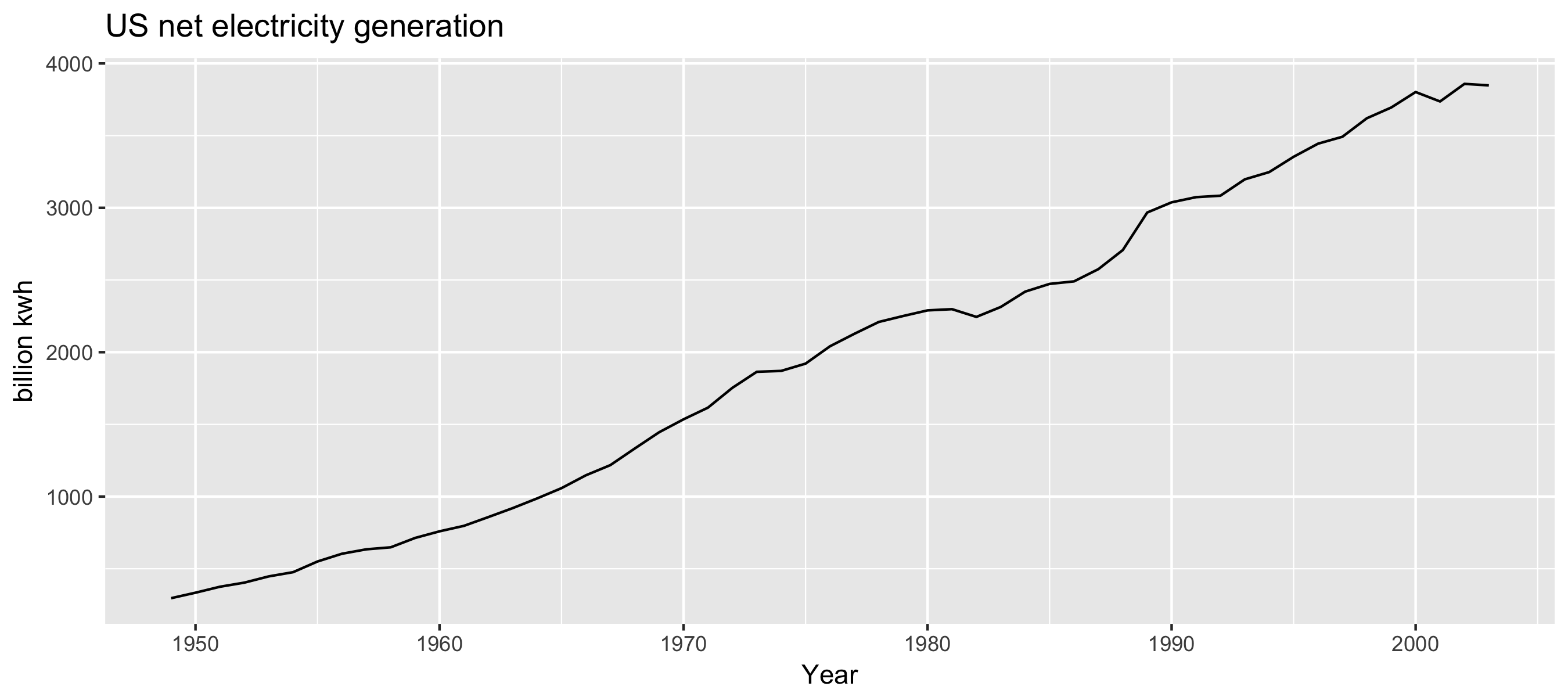
Netto-elektriciteitsproductie VS
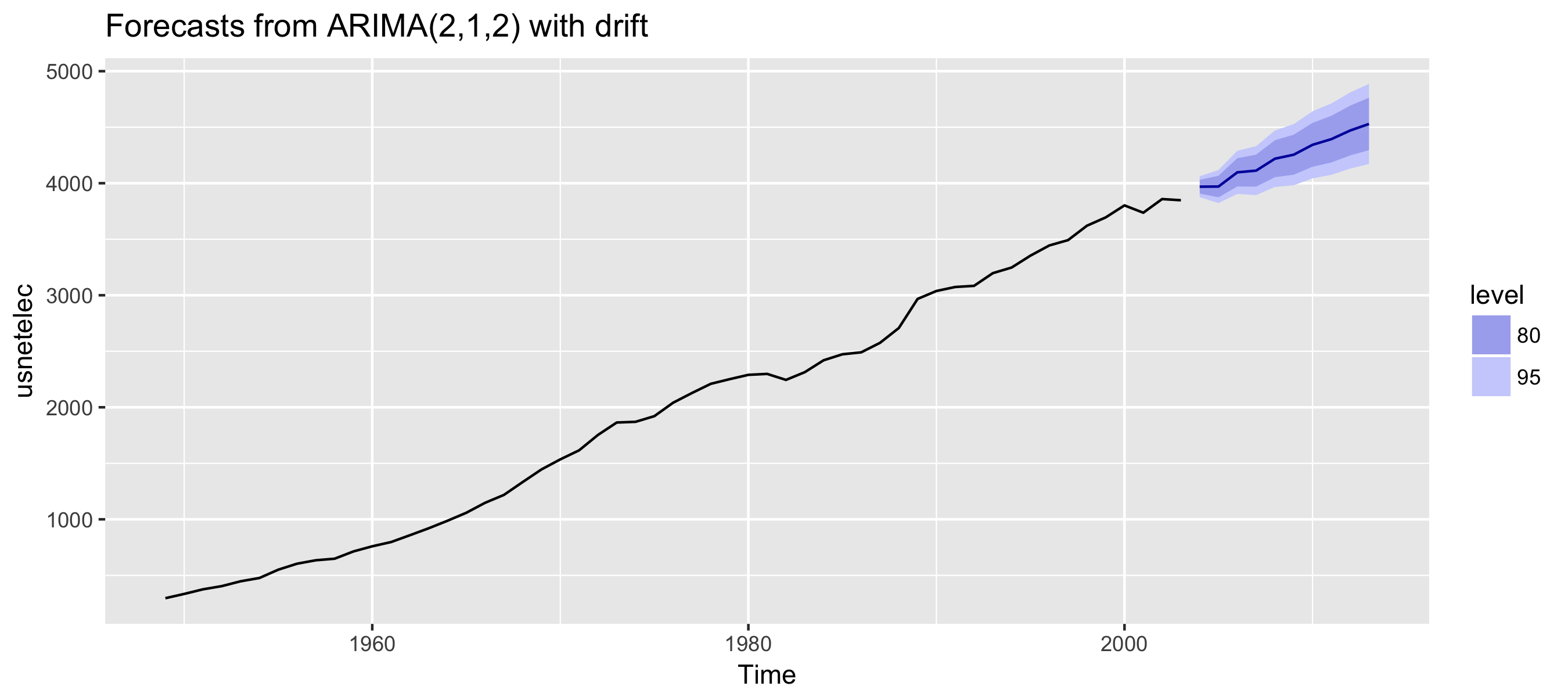
fit %>% forecast() %>% autoplot()