Gerandomiseerde verdelingen
Basis van inferentie in R

Jo Hardin
Instructor
Logica van inferentie
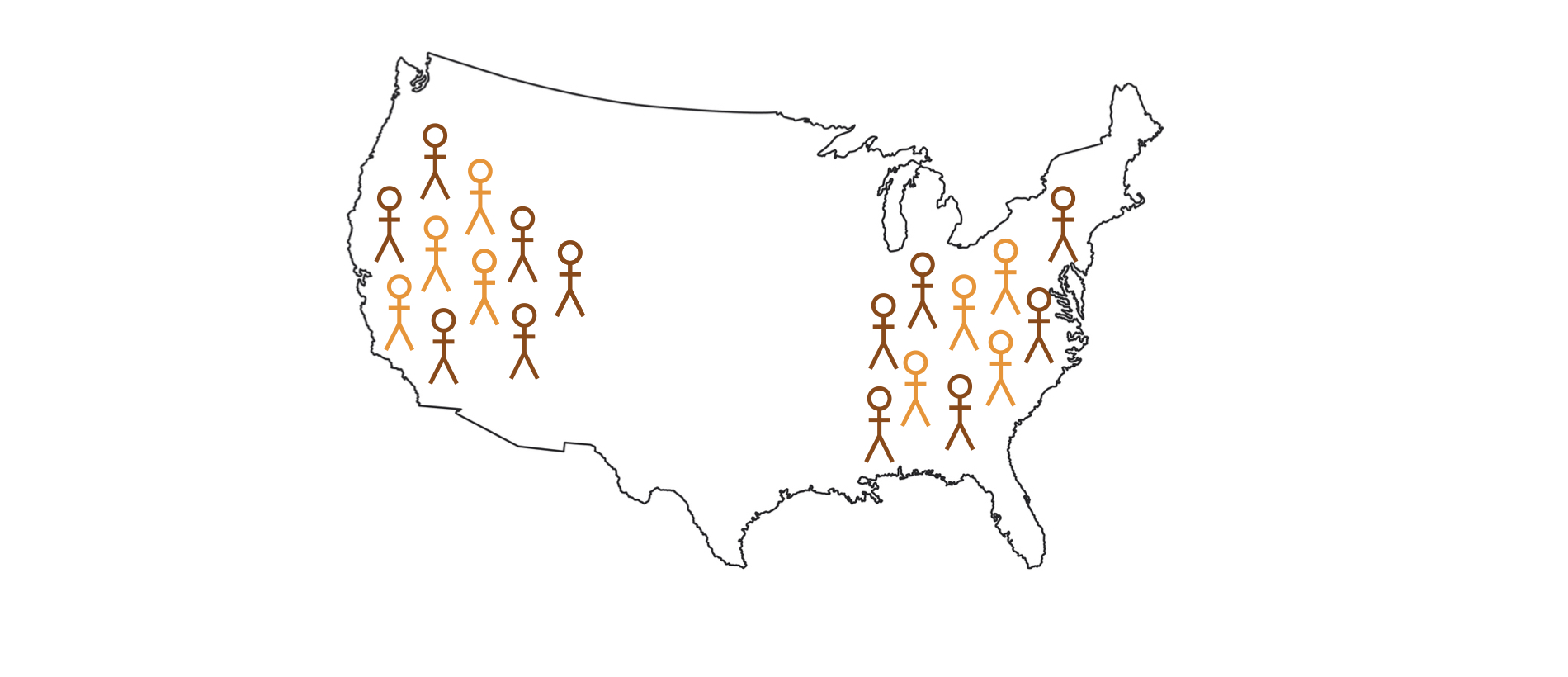
Logica van inferentie
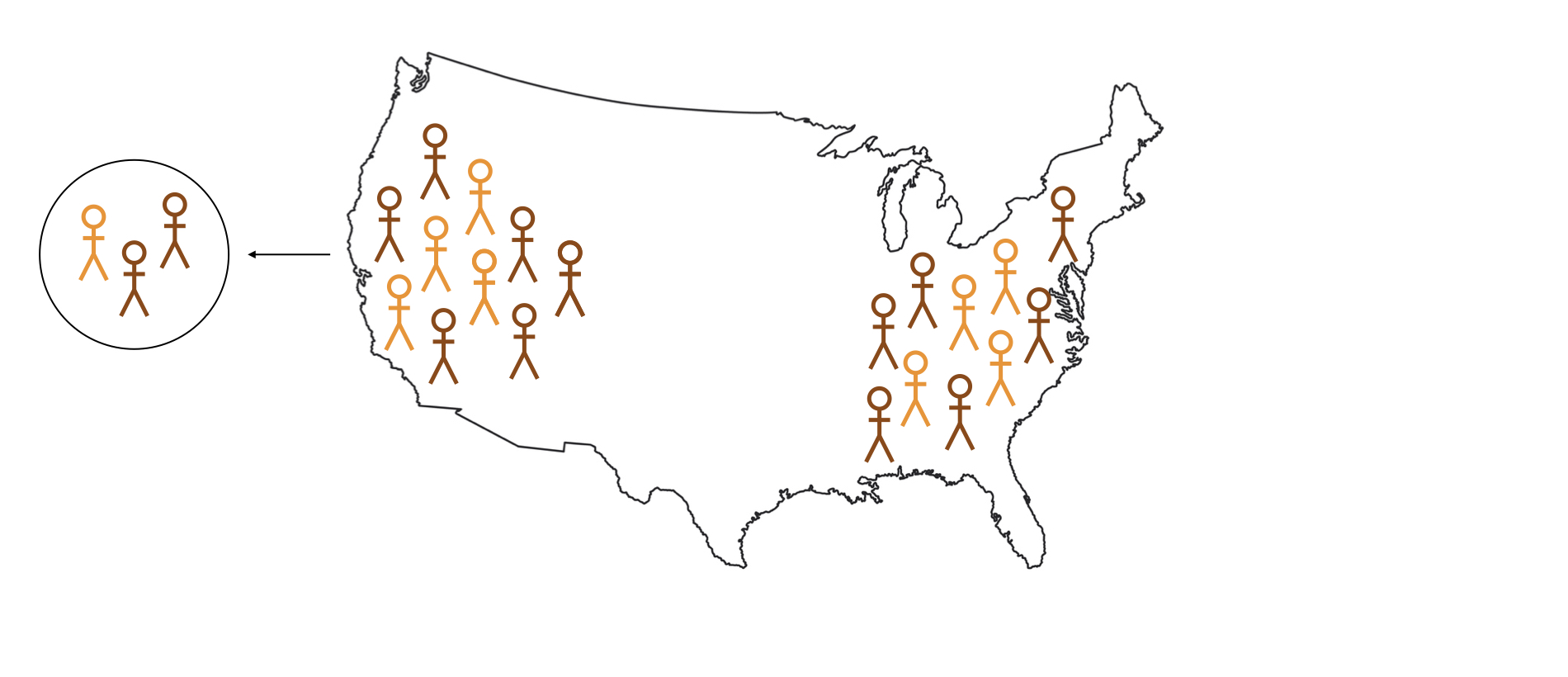
Logica van inferentie
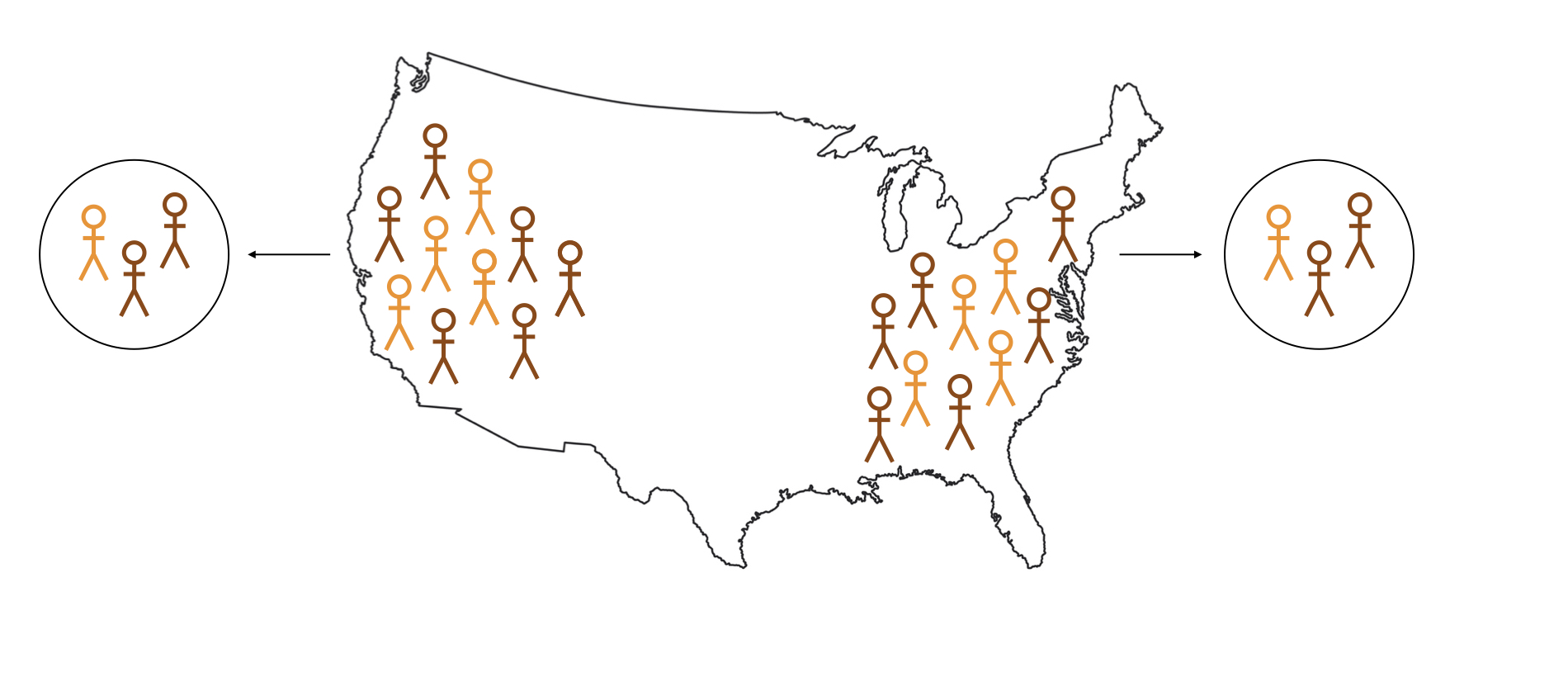
Logica van inferentie
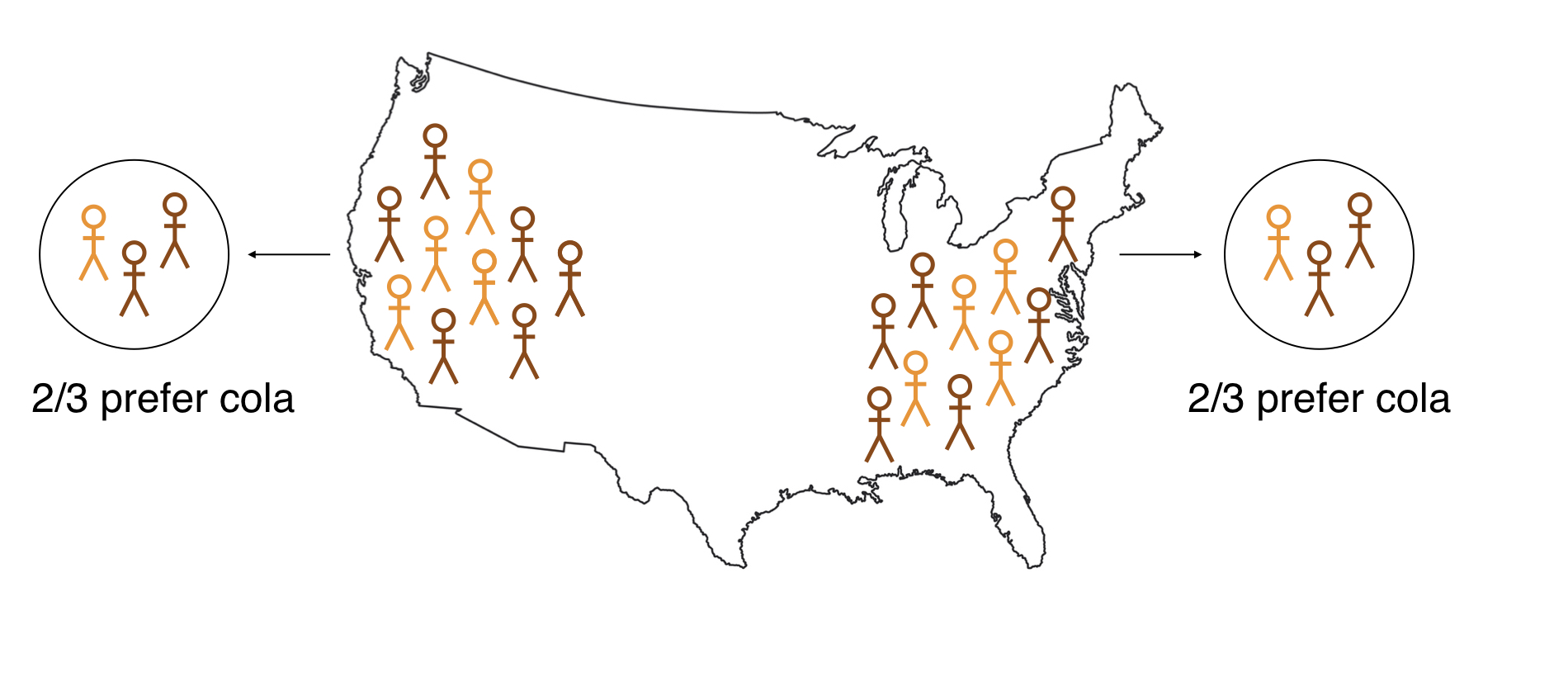
Logica van inferentie
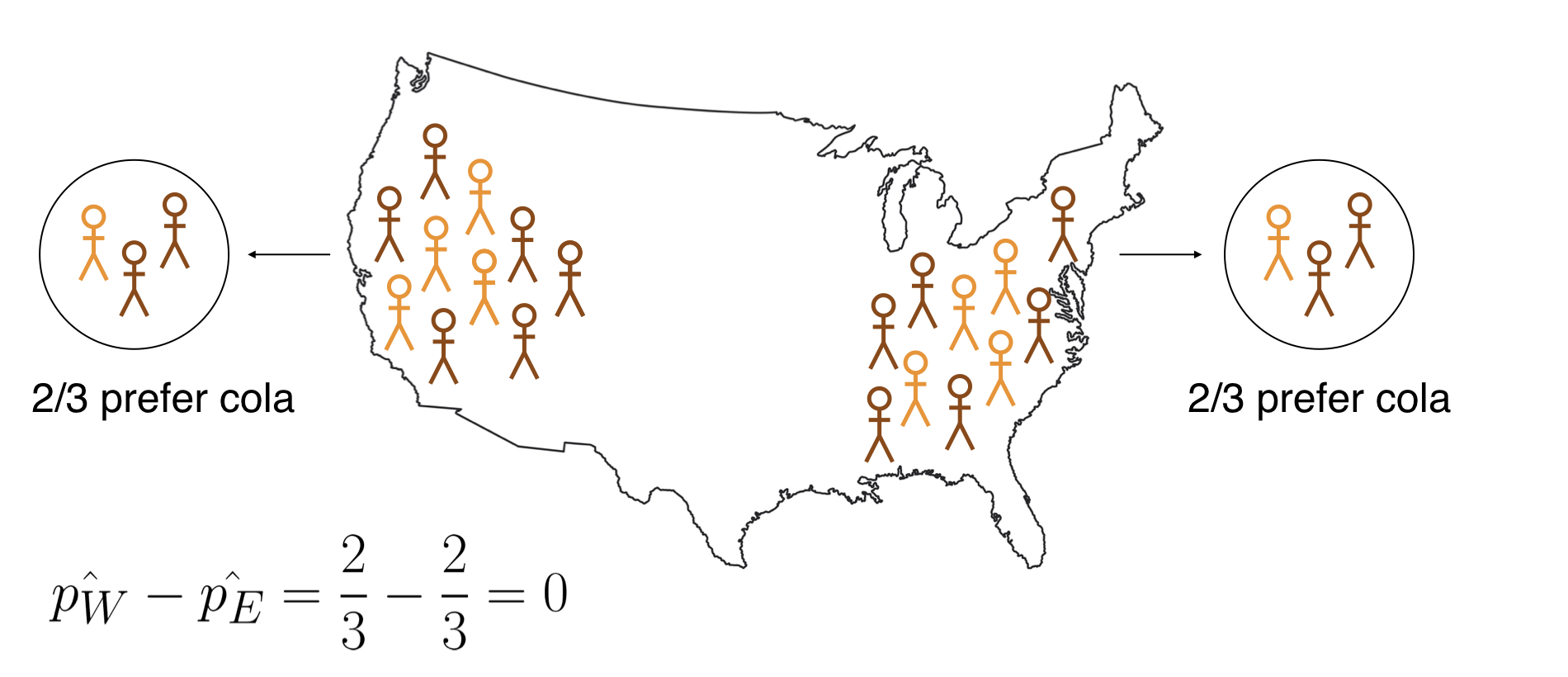
Logica van inferentie
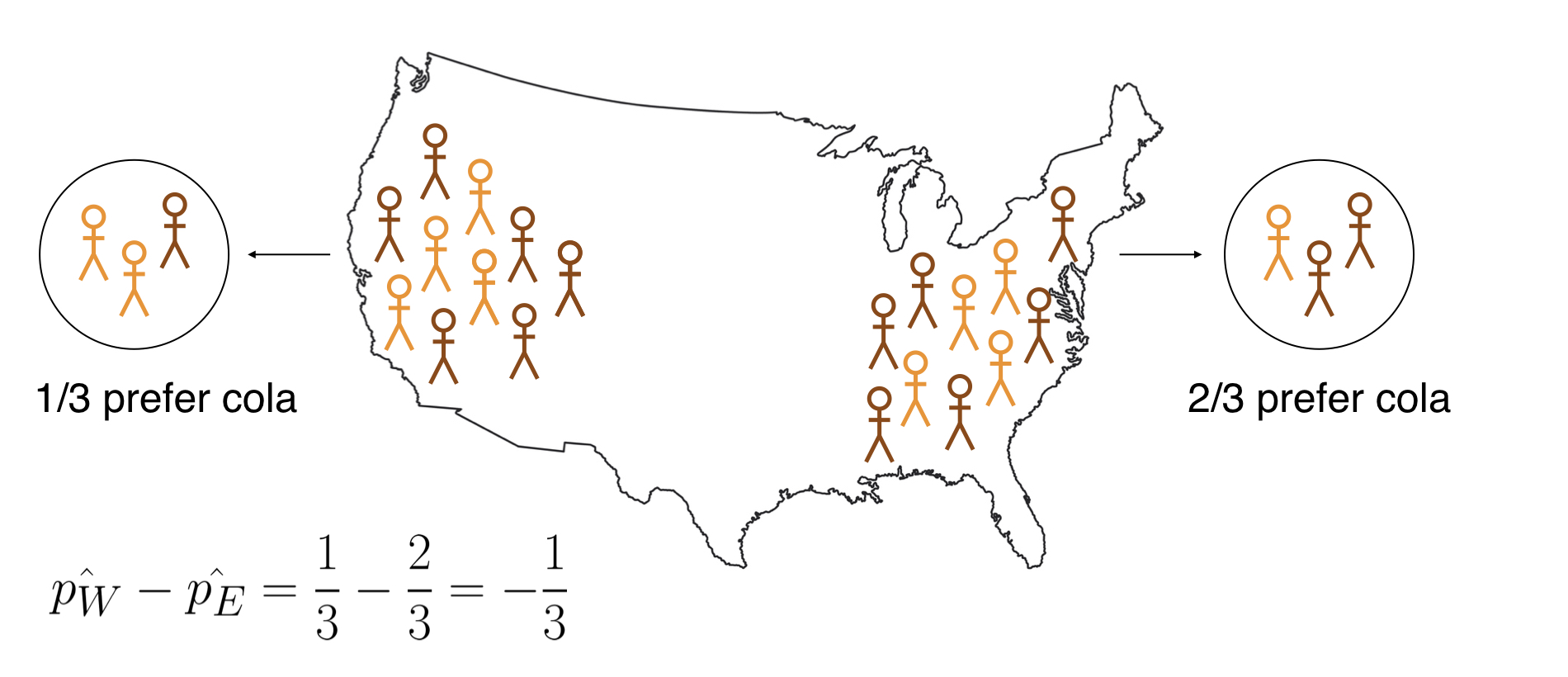
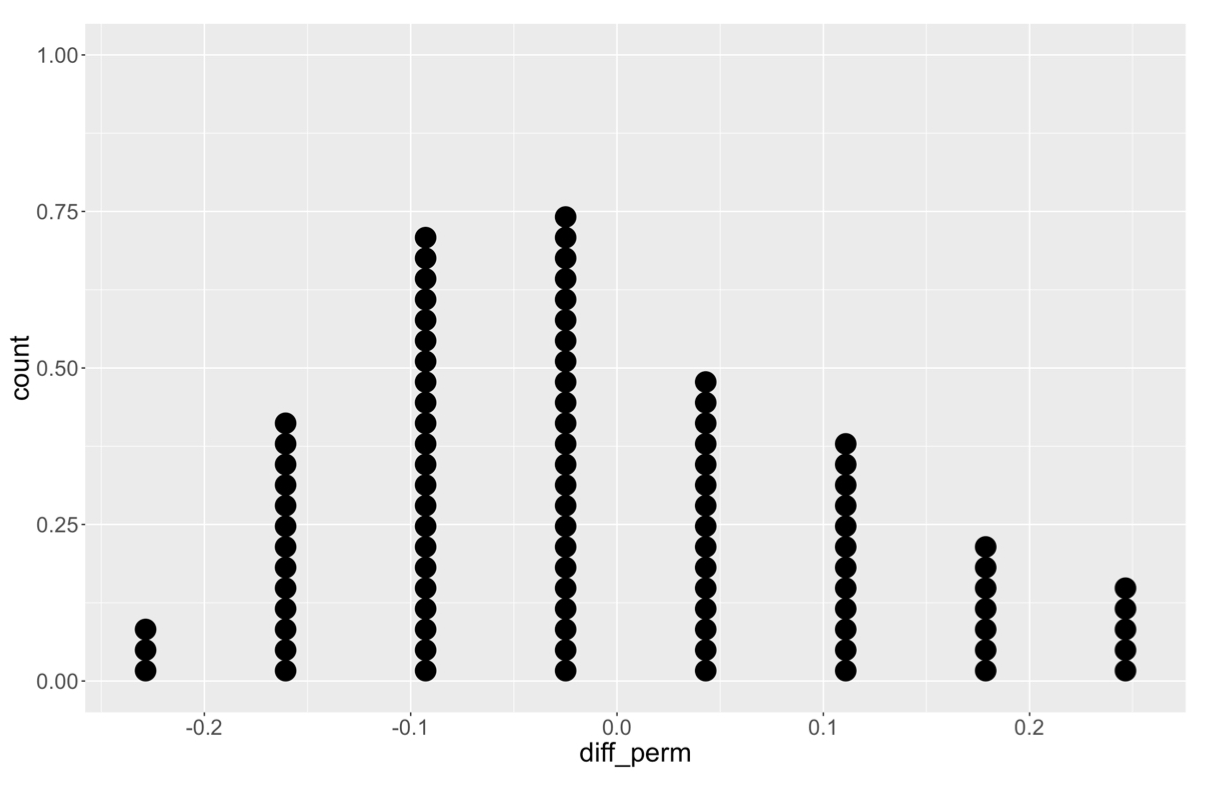
De nulverdeling begrijpen
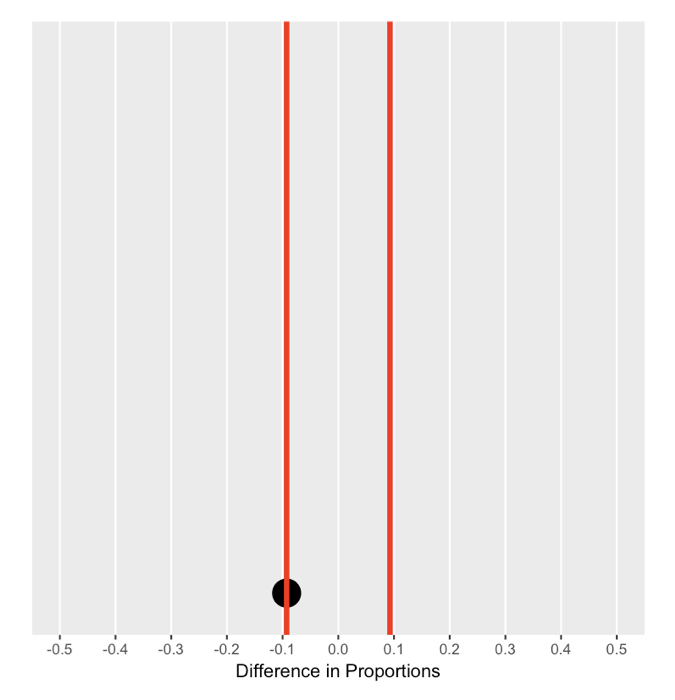
De nulverdeling begrijpen
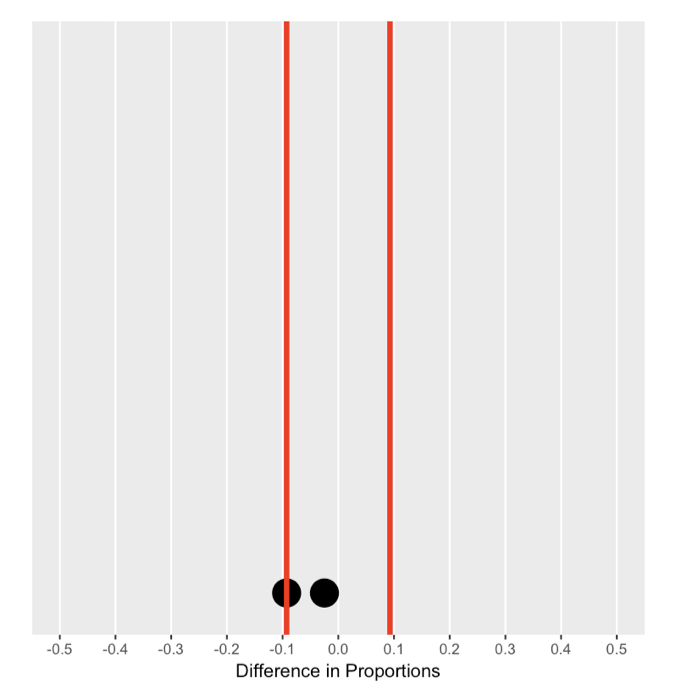
De nulverdeling begrijpen
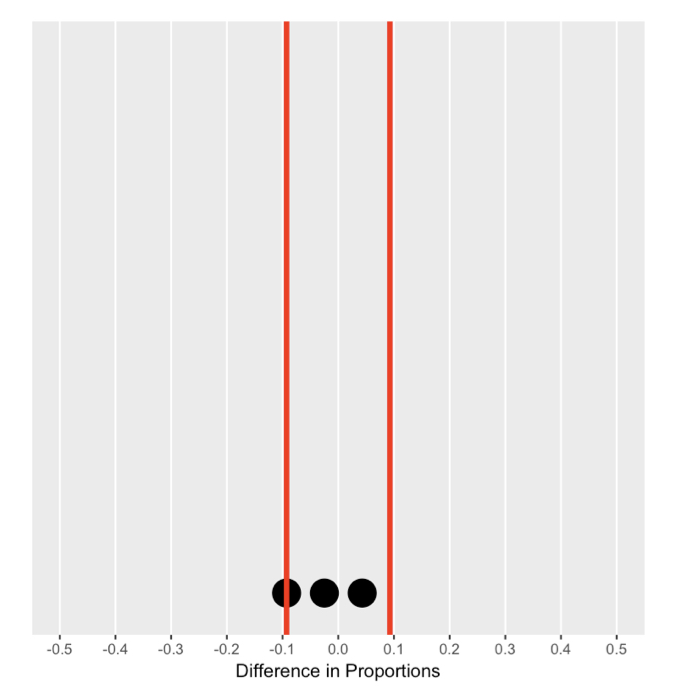
De nulverdeling begrijpen
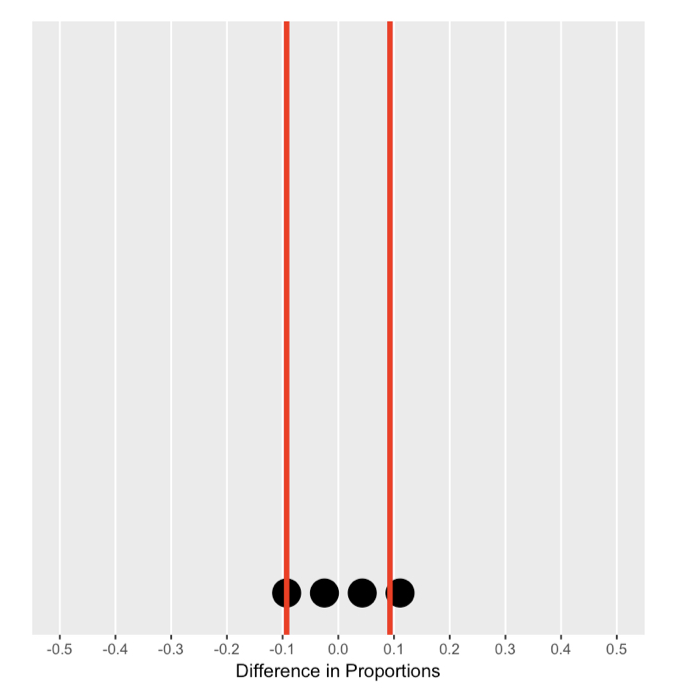
De nulverdeling begrijpen
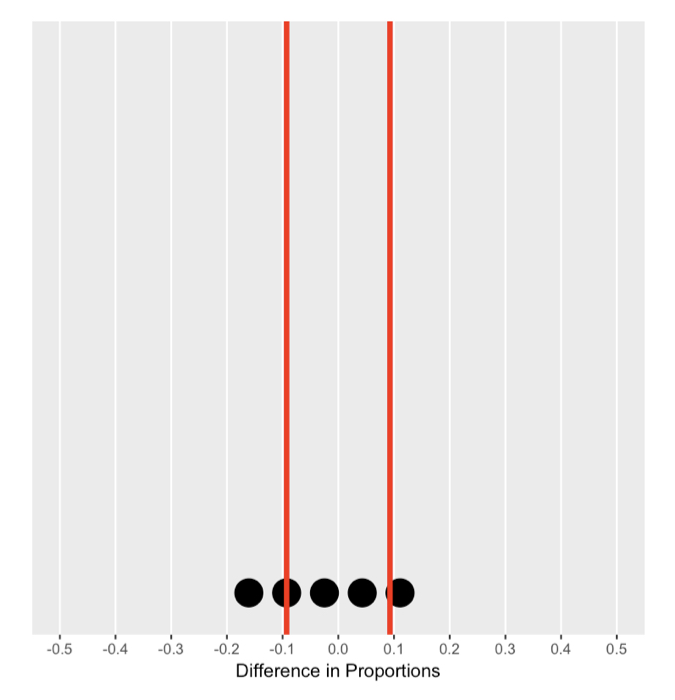
De nulverdeling begrijpen
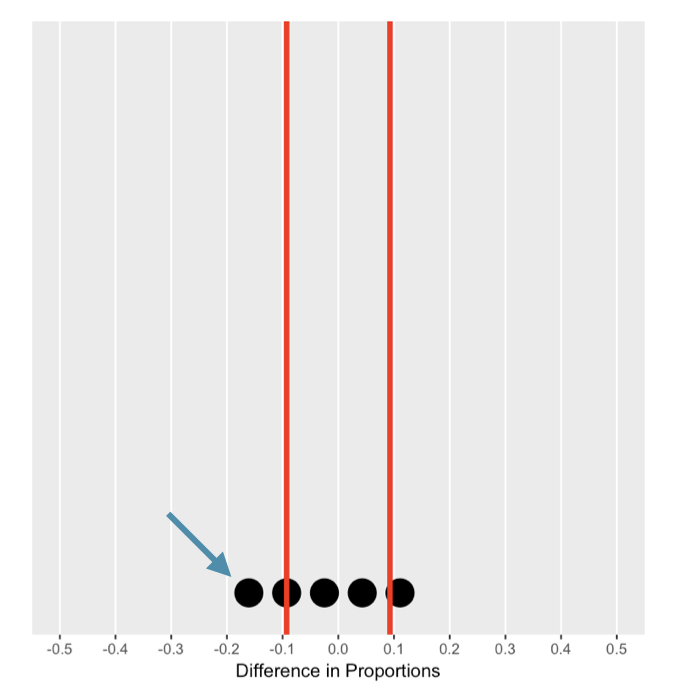
De nulverdeling begrijpen
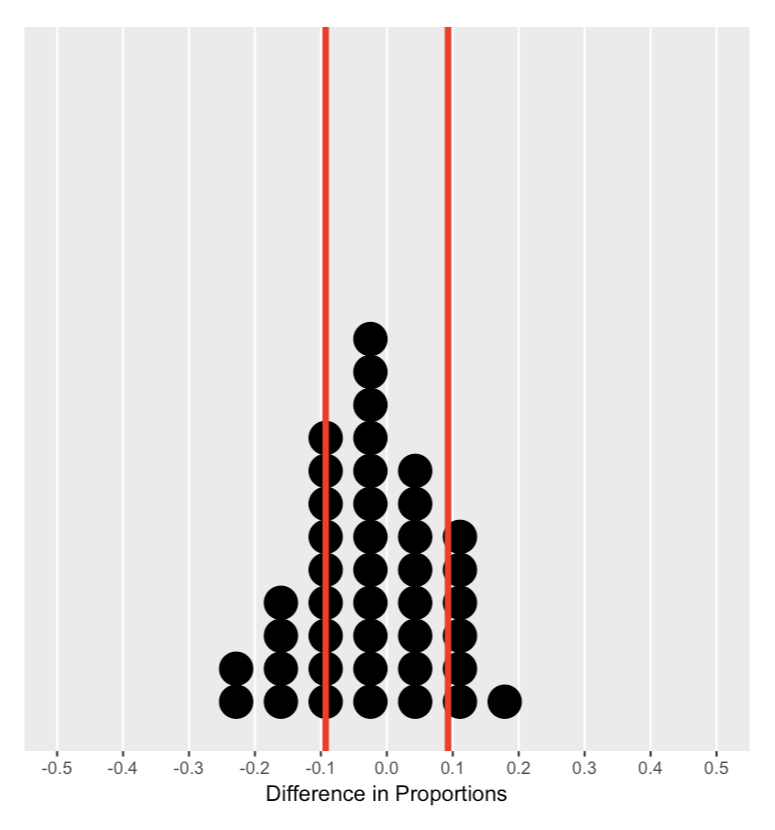
De nulverdeling begrijpen
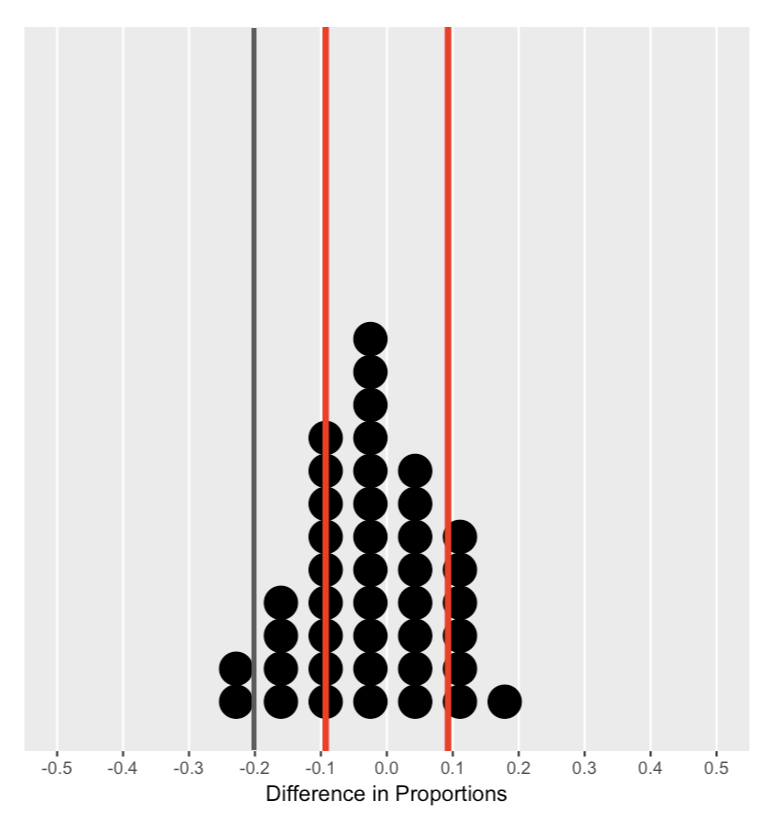
De nulverdeling begrijpen
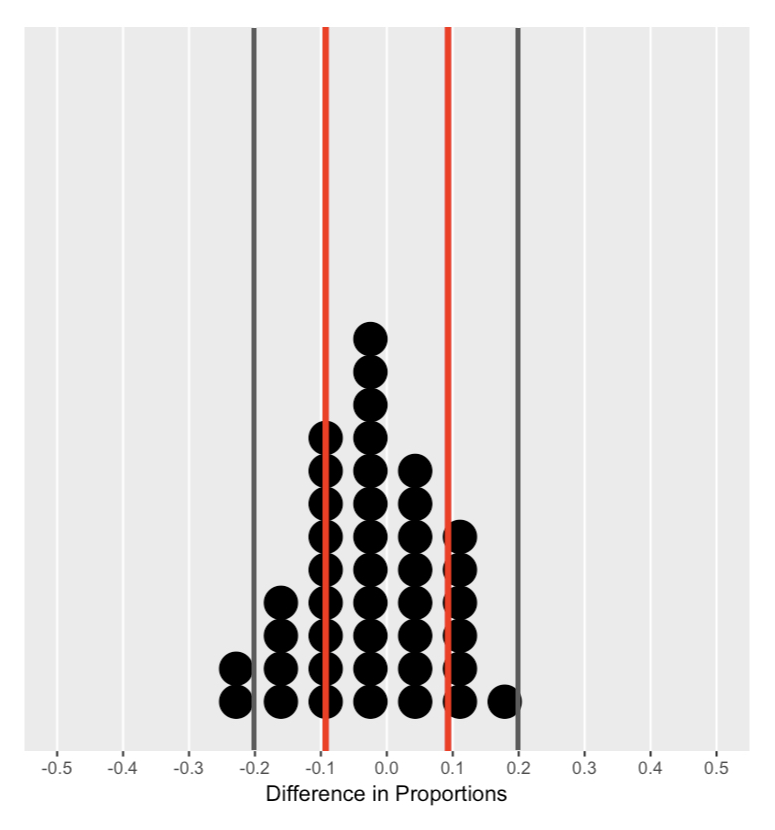
De nulverdeling begrijpen
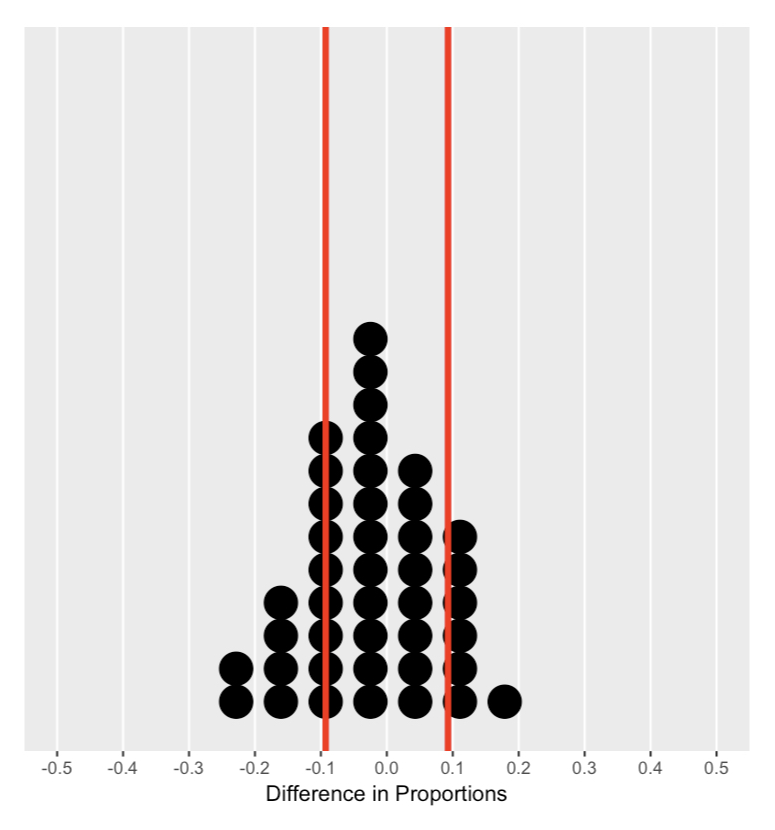
De nulverdeling begrijpen
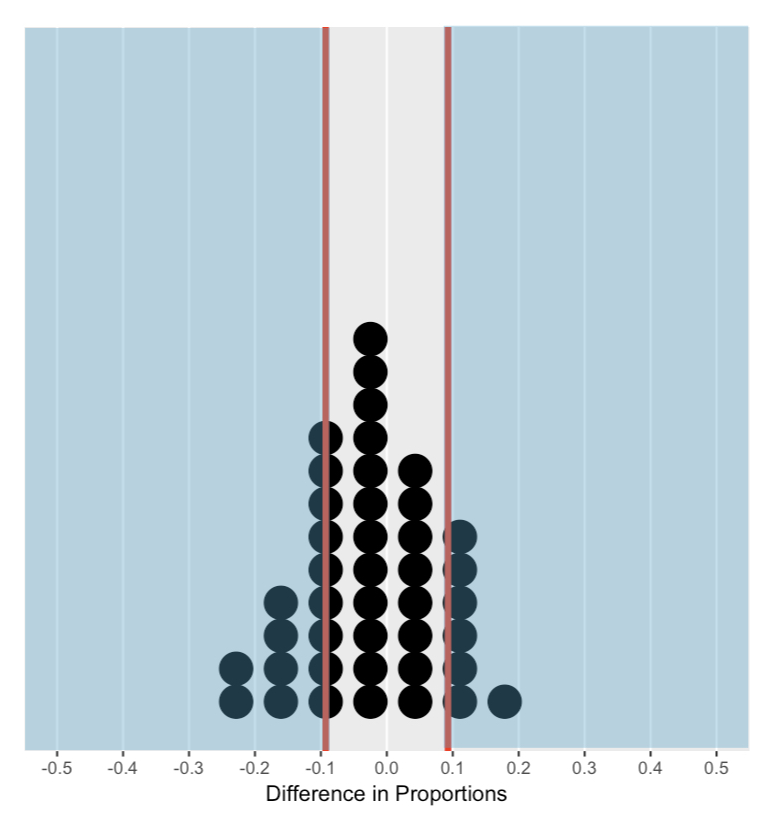
De nulverdeling begrijpen
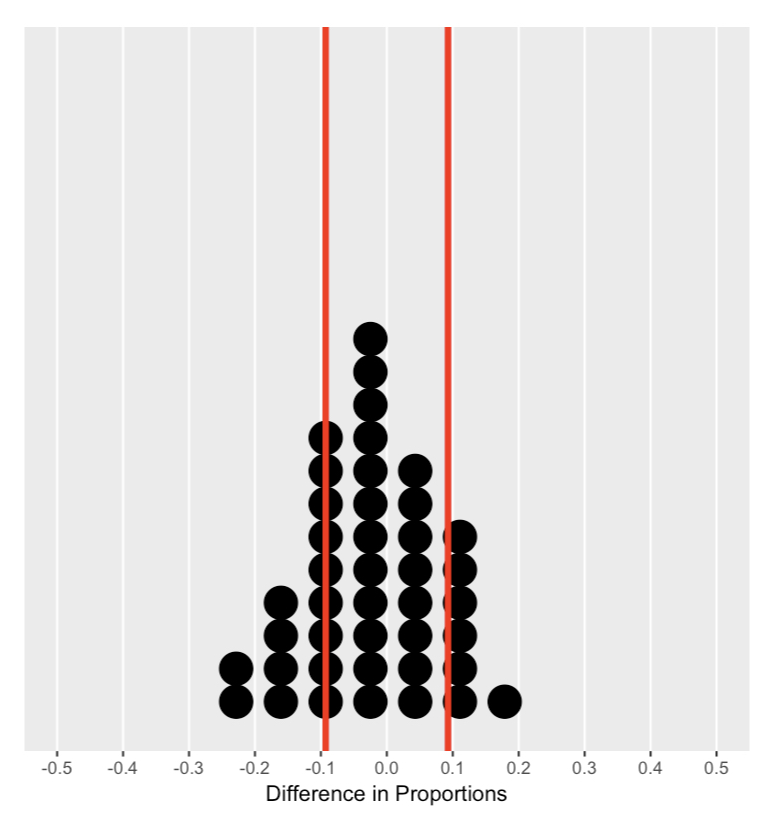
Willekeurige verdeling