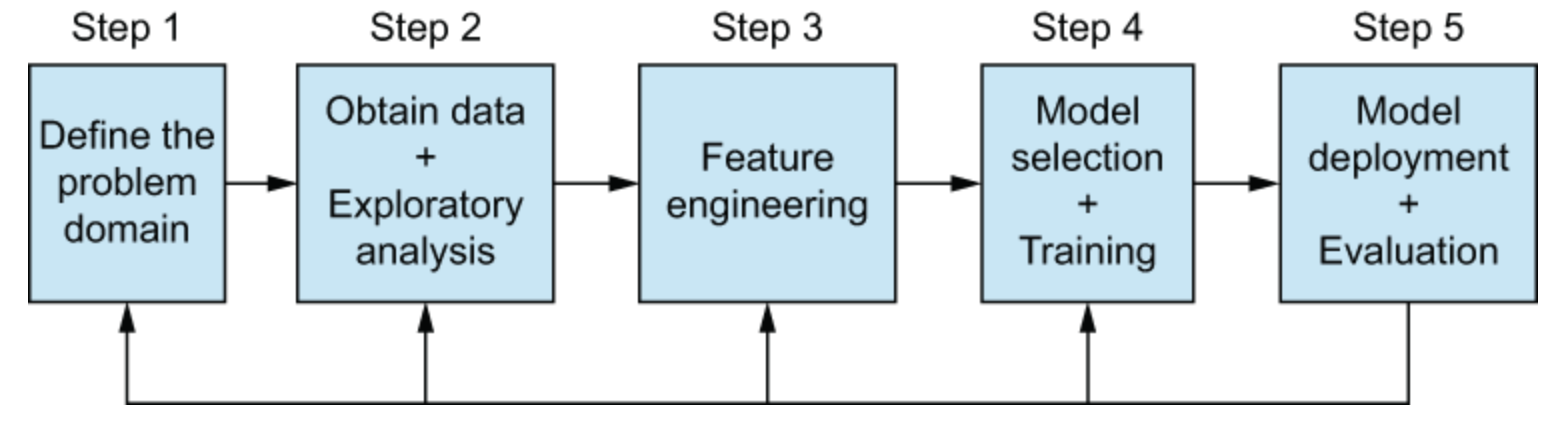
Feature engineering
Machine Learning-modellen ontwikkelen voor productie

Sinan Ozdemir
Data Scientist and Author
Introductie tot feature engineering
- Trainingsdata transformeren om de ML-pijplijn te maximaliseren
- Rekencomplexiteit verlagen
- Voorbeelden
- Data uit meerdere bronnen aggregeren
- Nieuwe features construeren
- Feature-transformaties toepassen
1 https://www.manning.com/books/feature-engineering-bookcamp
Data aggregeren uit meerdere bronnen
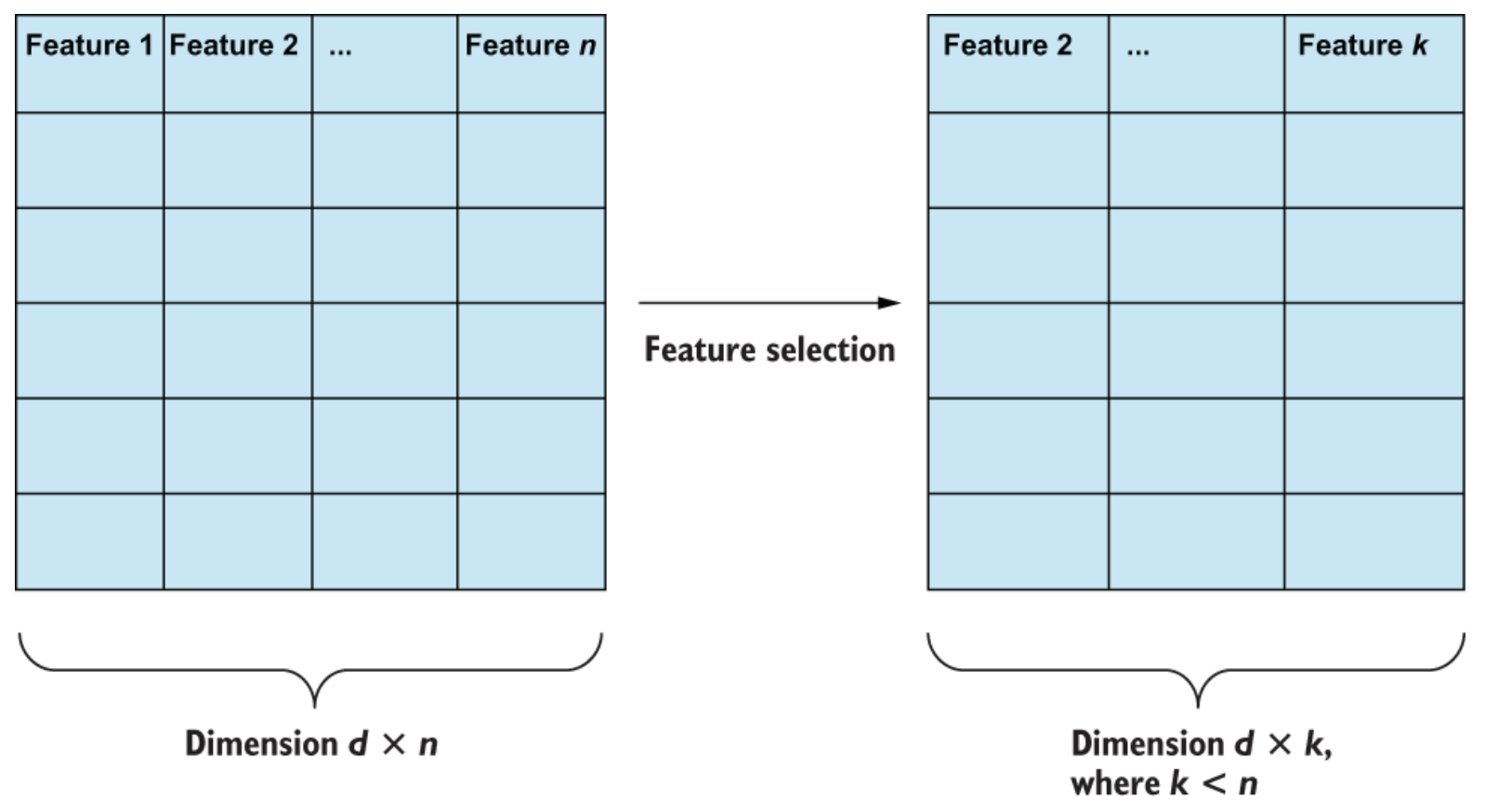
Feature-selectie
1 https://www.manning.com/books/feature-engineering-bookcamp
Meer leren over feature engineering


