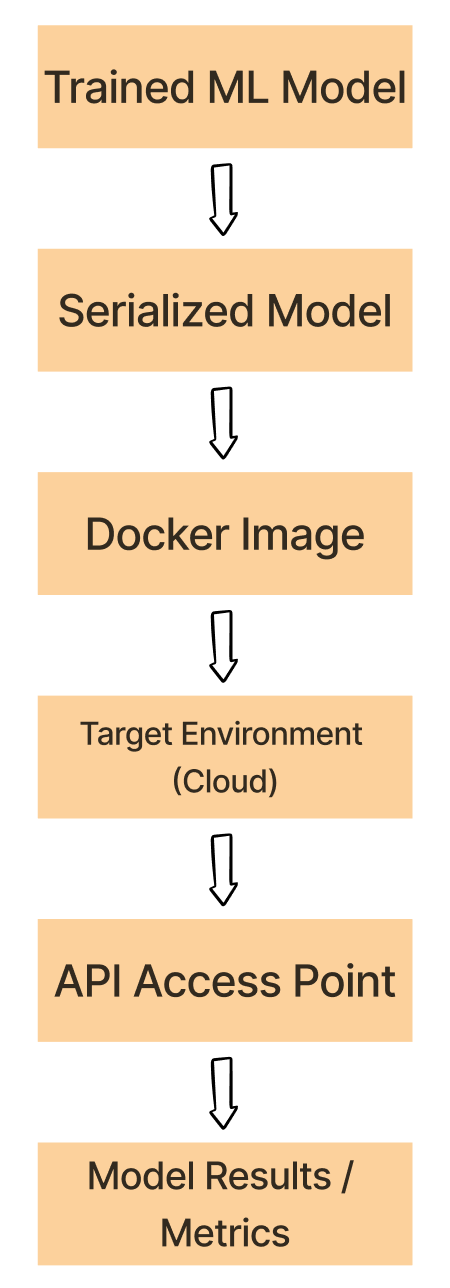
ML-modellen verpakken
Machine Learning-modellen ontwikkelen voor productie

Sinan Ozdemir
Data Scientist, Entrepreneur, and Author
ML-omgevingen verpakken met Docker
- Zorg dat de modelomgeving het kan draaien
- virtualenv e.d. maken consistente, reproduceerbare omgevingen
- Docker-containers zijn zelfvoorzienend en eenvoudig te deployen

Experiment -> Docker-werkstroom