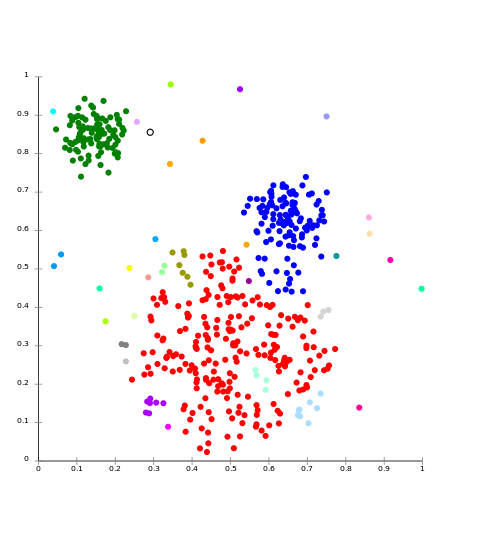
Andere clusteringsmethoden voor fraudedetectie
Fraudedetectie in Python

Charlotte Werger
Data Scientist
Er zijn veel verschillende clusteringsmethoden
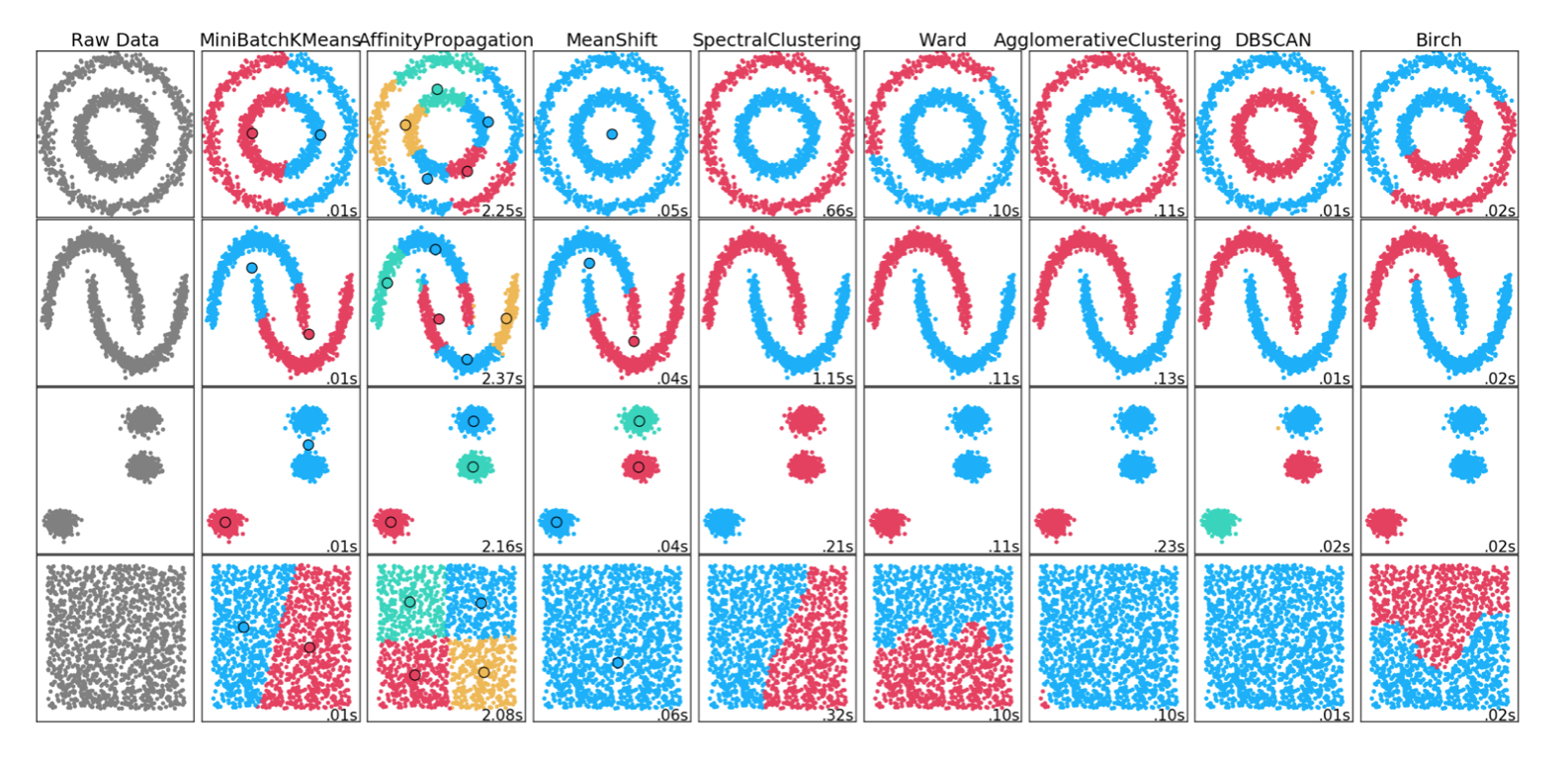
En verschillende manieren om fraude te markeren: kleinste clusters gebruiken
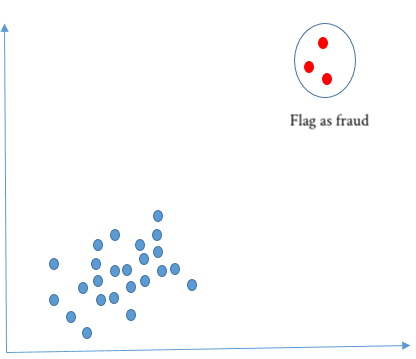
In de praktijk ziet het er vaker zo uit