Lek in features – data gebruiken die in de praktijk niet beschikbaar is
Lek in validatiestrategie – validatiestrategie wijkt af van de echte situatie
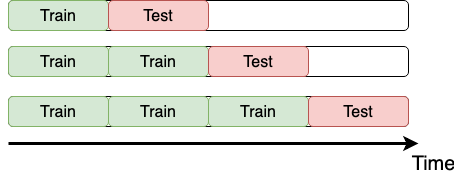
Tijdsdata
Time K-fold cross-validation
Time K-fold cross-validation
# Importeer TimeSeriesSplit
from sklearn.model_selection import TimeSeriesSplit
# Maak een TimeSeriesSplit-object
time_kfold = TimeSeriesSplit(n_splits=5)
# Sorteer train op datum
train = train.sort_values('date')
# Loop door elke cross-validatiesplit
for train_index, test_index in time_kfold.split(train):
cv_train, cv_test = train.iloc[train_index], train.iloc[test_index]
Validatiepijplijn
# Lijst voor de resultaten
fold_metrics = []
for train_index, test_index in CV_STRATEGY.split(train):
cv_train, cv_test = train.iloc[train_index], train.iloc[test_index]
# Train een model
model.fit(cv_train)
# Maak voorspellingen
predictions = model.predict(cv_test)
# Bereken de metriek
metric = evaluate(cv_test, predictions)
fold_metrics.append(metric)
Modelvergelijking
Fold-nummer
Model A MSE
Model B MSE
Fold 1
2.95
2.97
Fold 2
2.84
2.45
Fold 3
2.62
2.73
Fold 4
2.79
2.83
Totale validatiescore
import numpy as np
# Eenvoudig gemiddelde over de folds
mean_score = np.mean(fold_metrics)
# Totale validatiescore
overall_score_minimizing = np.mean(fold_metrics) + np.std(fold_metrics)
# Of
overall_score_maximizing = np.mean(fold_metrics) - np.std(fold_metrics)