Webscraping in R
Timo Grossenbacher
Instructor
//div/p[@class = "blue"]
div > p.blue
div
a
special
html %>% html_elements(xpath = '//p') # CSS selector equivalent: p
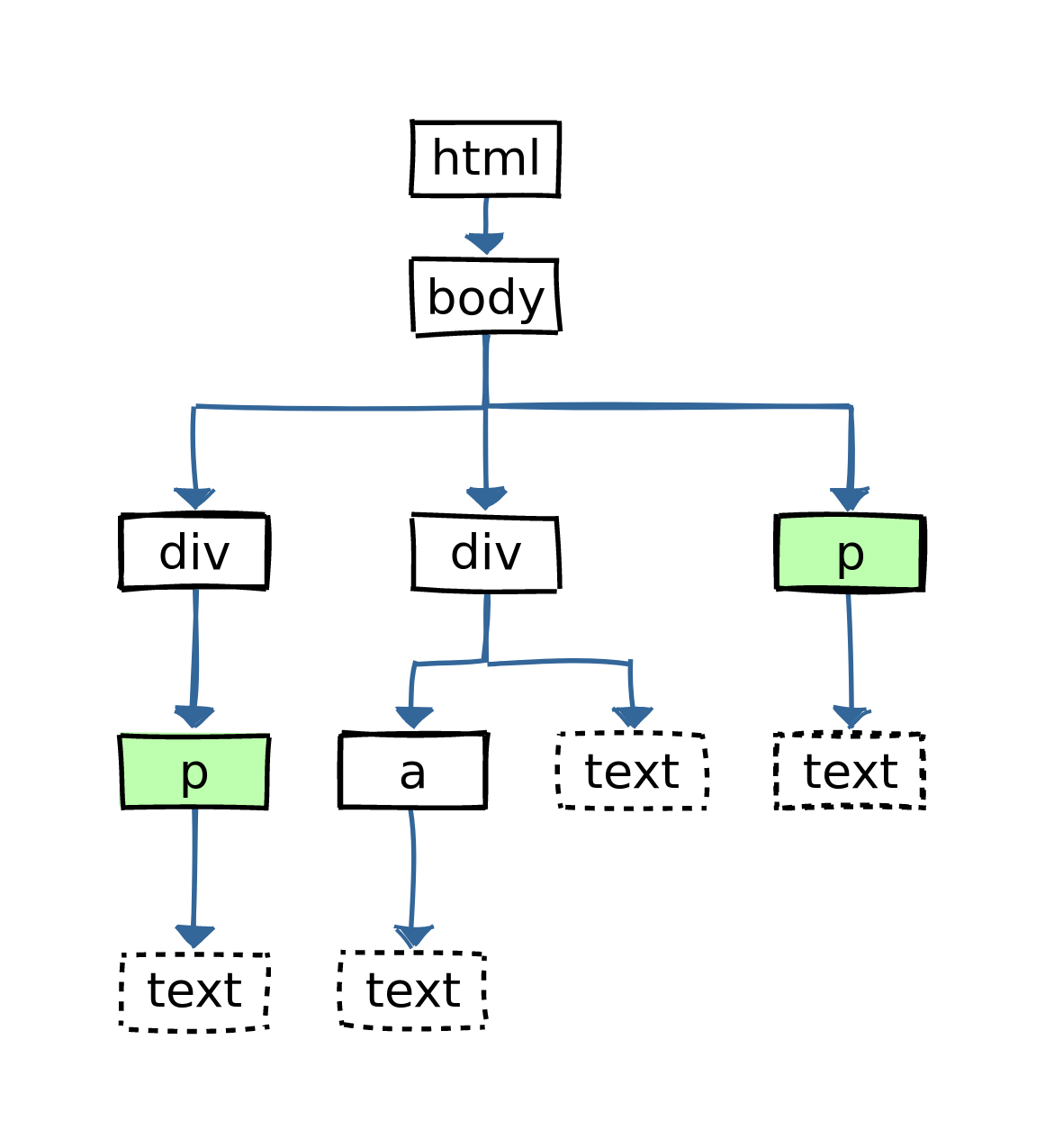
html %>% html_elements(xpath = '//body//p') # CSS selector equivalent: body p
html %>% html_elements(xpath = '/html/body//p') # CSS selector equivalent: html > body p
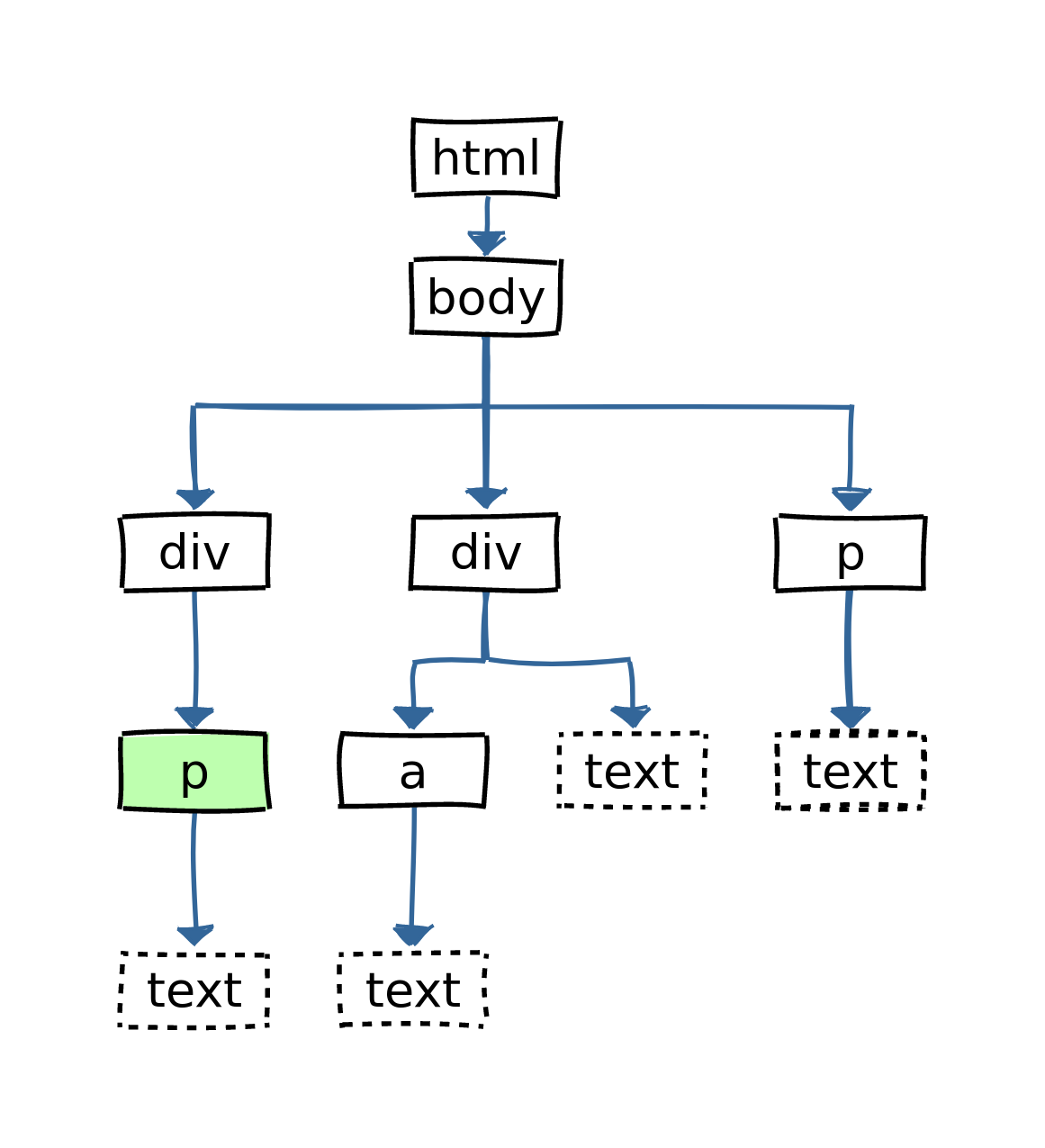
html %>% html_elements(xpath = '//div/p') # CSS selector equivalent: div > p
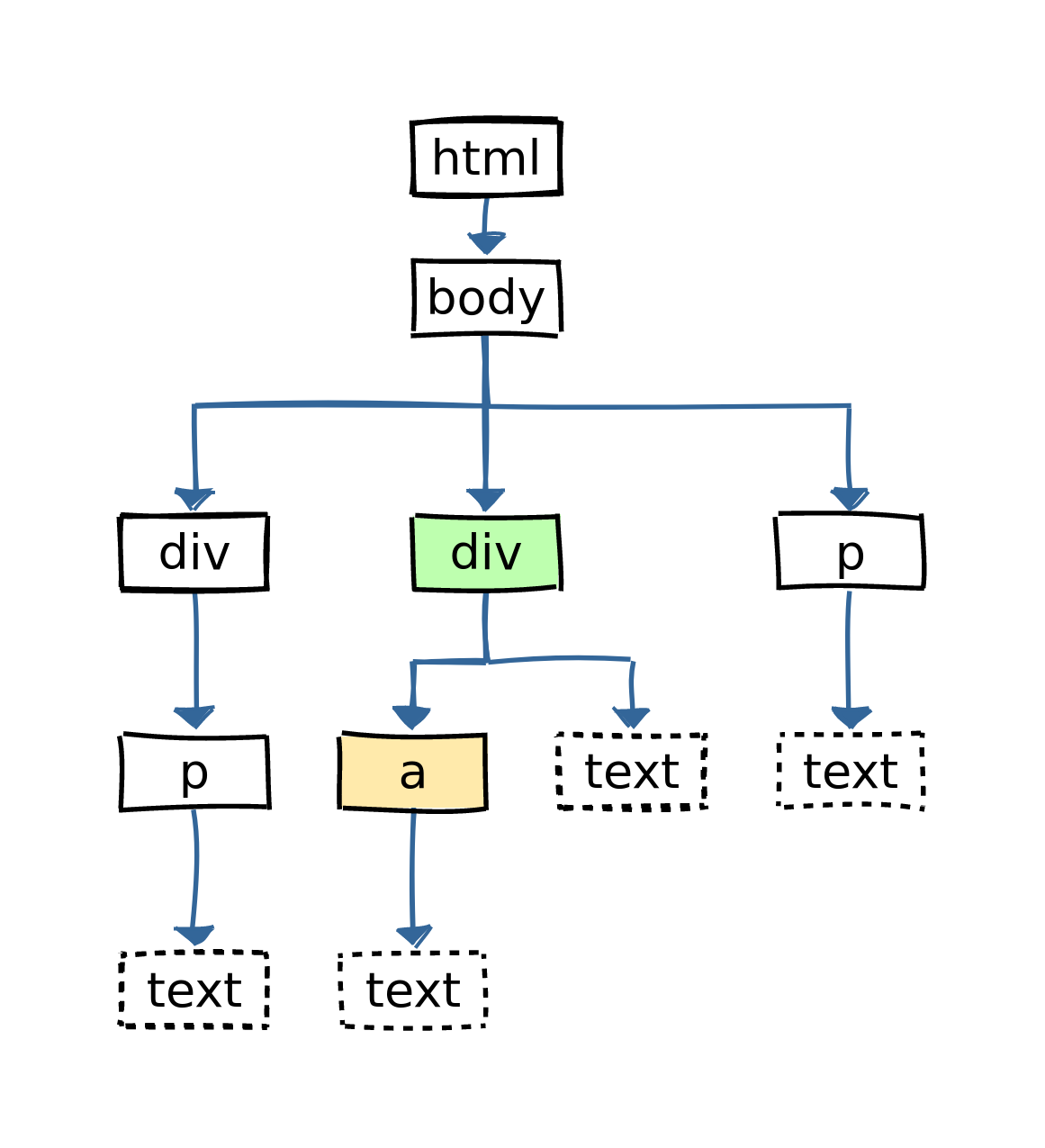
html %>% html_elements(xpath = '//div[a]') # CSS selector equivalent: none
/
//
span
[...]
//span/a[@class = "external"]
span > a.external
//*[@id = "special"]//div
#special div
*#special div