Verdwijnende en exploderende gradiënten
Recurrent Neural Networks (RNN's) voor taalmodellen met Keras

David Cecchini
Data Scientist
RNN-modellen trainen
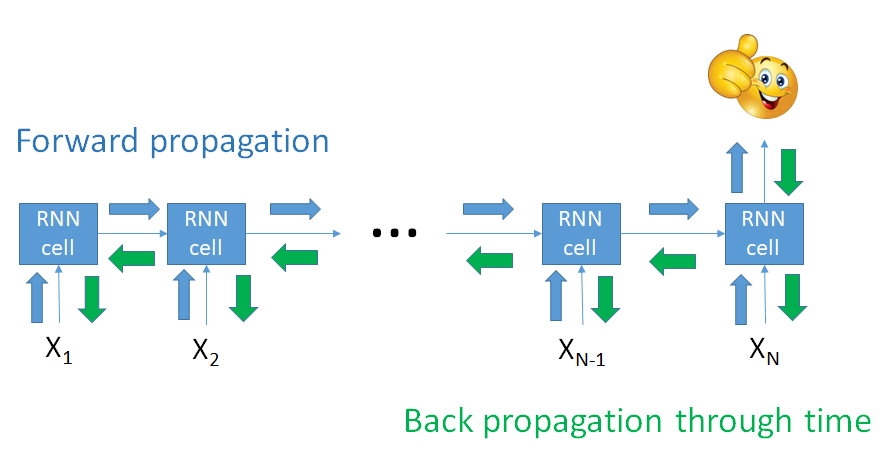
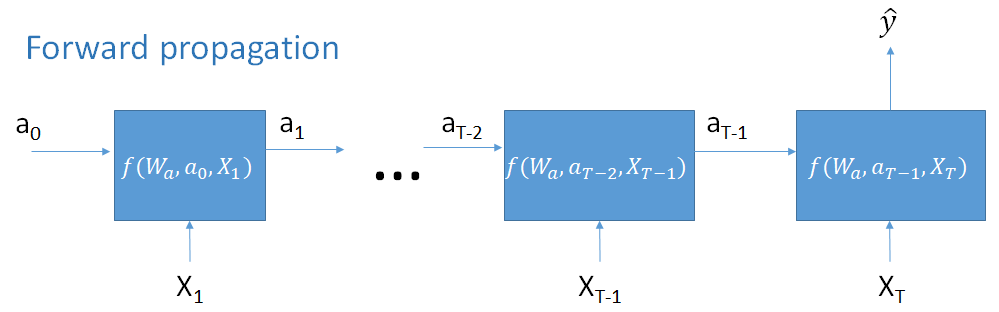
Voorbeeld: $$a_2 = f(W_a, a_1, x_2)$$
$$= f(W_a, f(W_a, a_0, x_1), x_2)$$
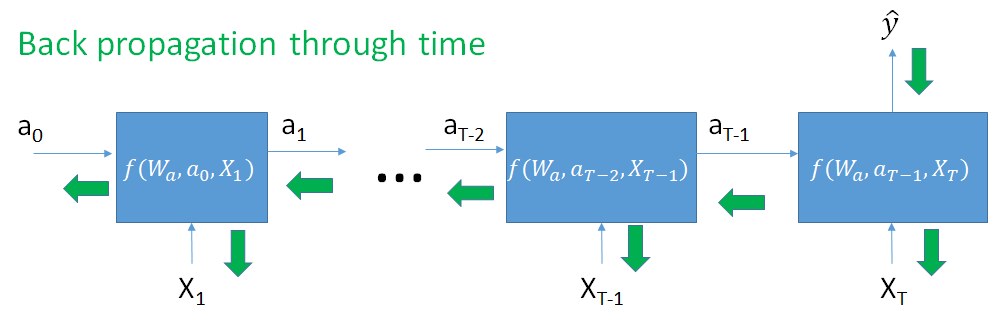
Onthoud:
$$ a_T = f(W_a, a_{T-1}, x_T) $$
$a_T$ hangt ook af van $a_{T-1}$, dat afhangt van $a_{T-2}$ en $W_a$, enz.!

