Neurale machinale vertaling
Recurrent Neural Networks (RNN's) voor taalmodellen met Keras

David Cecchini
Data Scientist
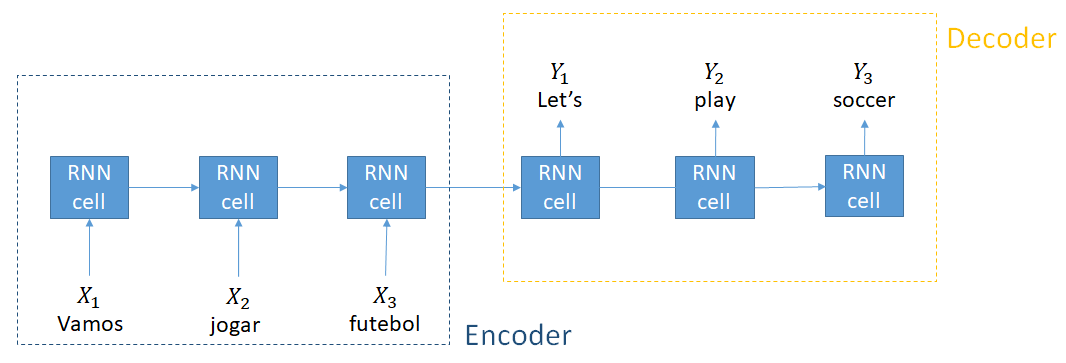
Encoders en decoders
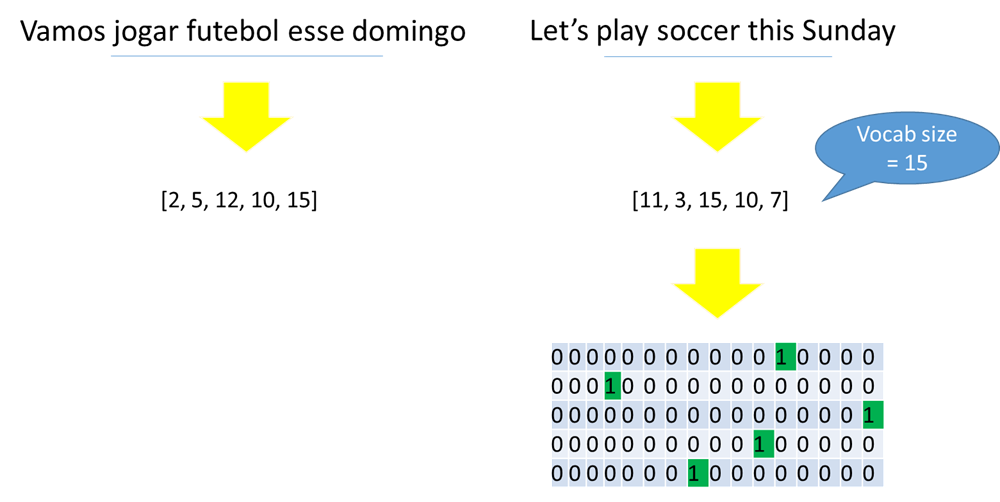
Datavoorbereiding
Recurrent Neural Networks (RNN's) voor taalmodellen met Keras
David Cecchini
Data Scientist

