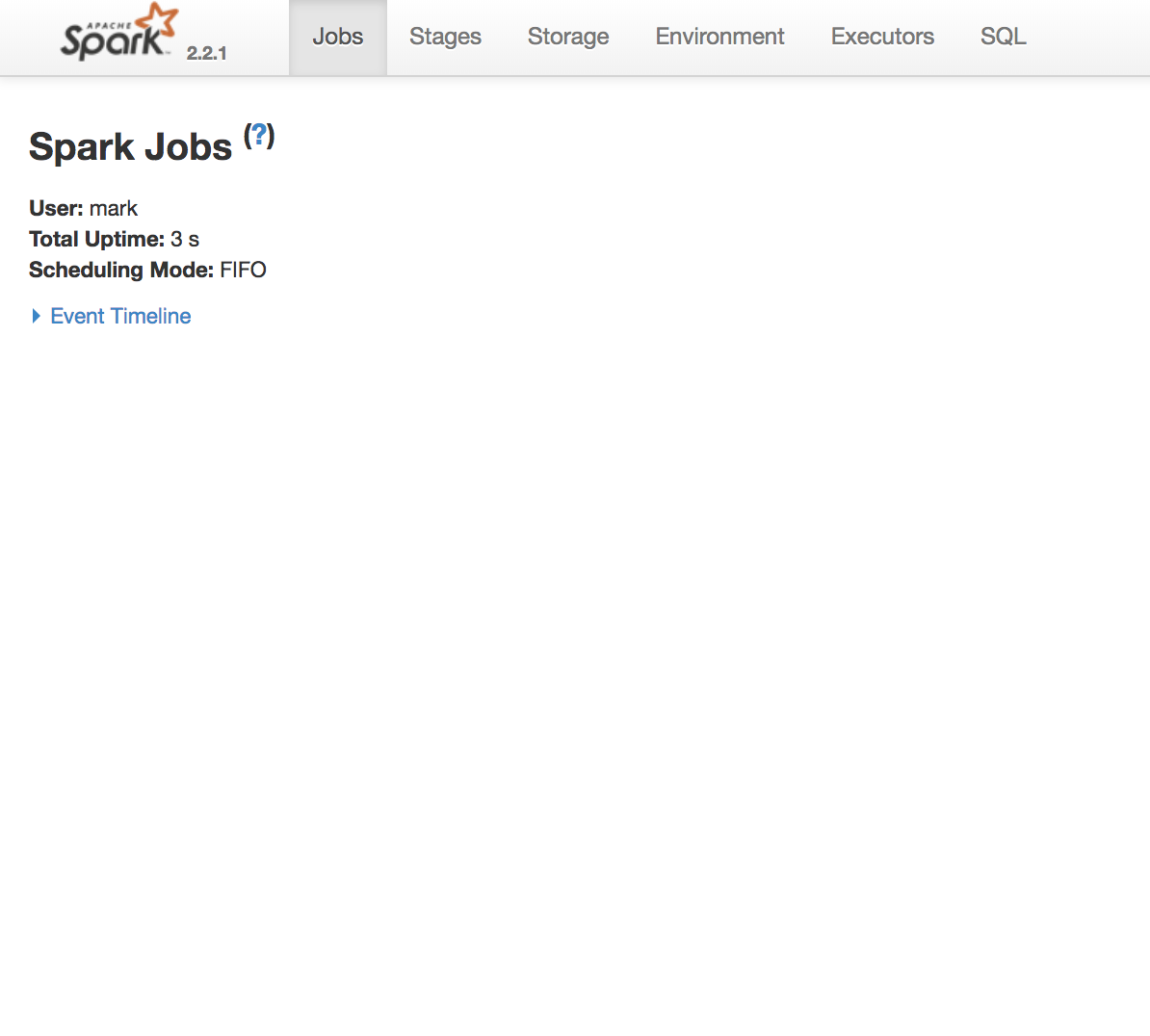
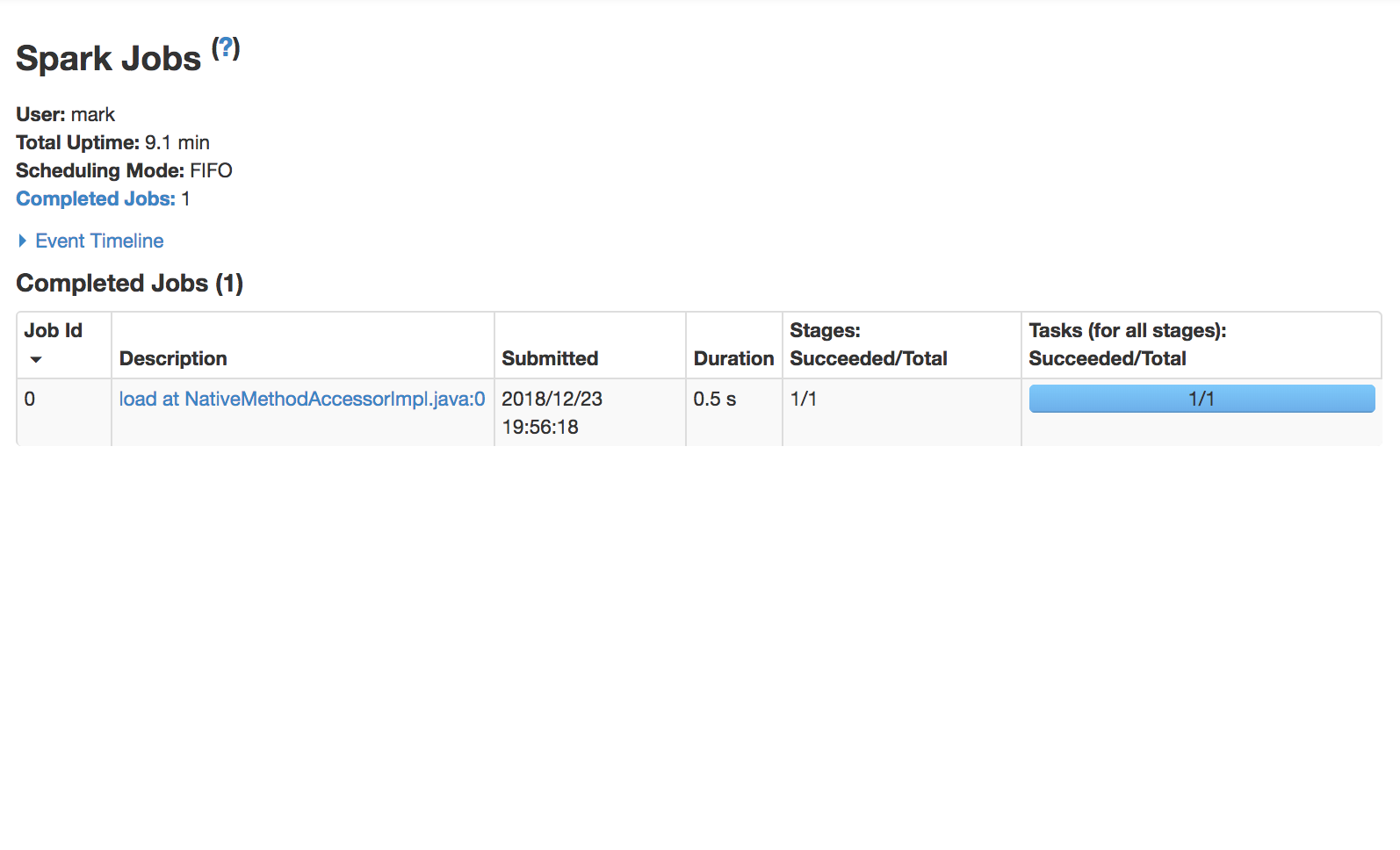
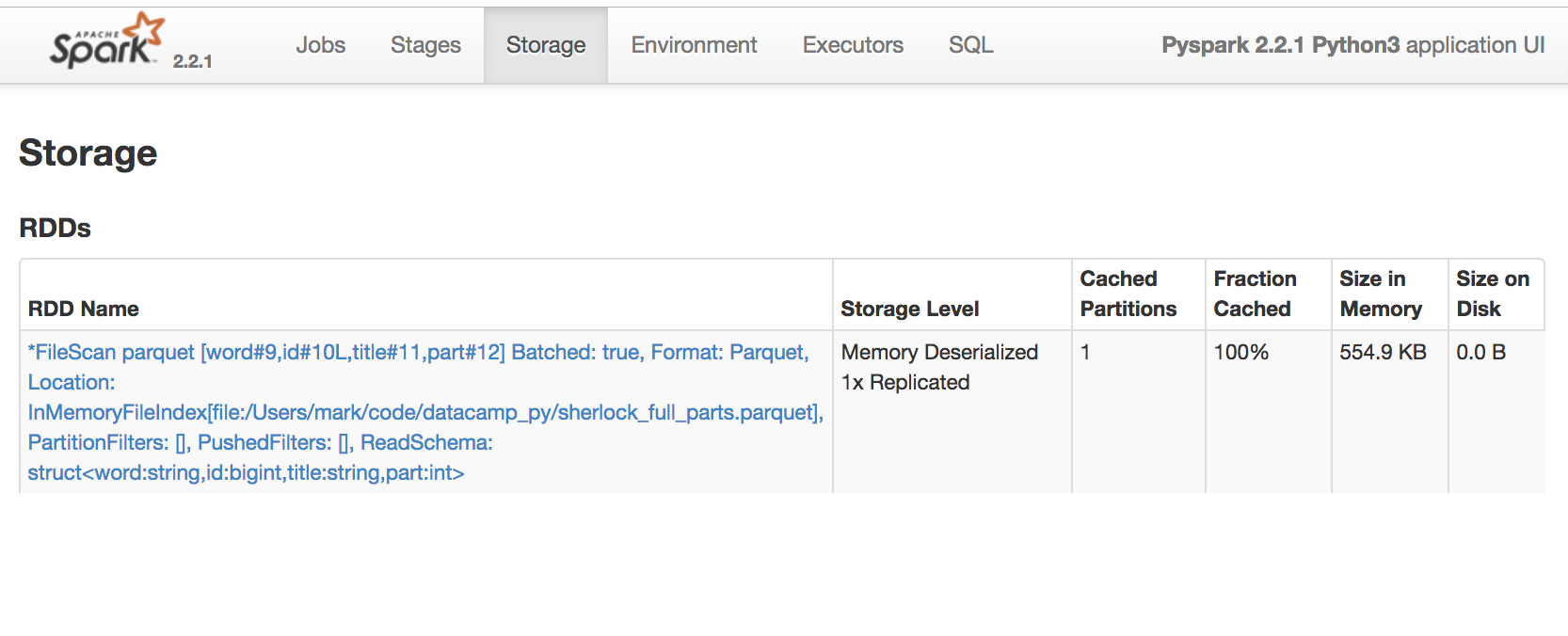
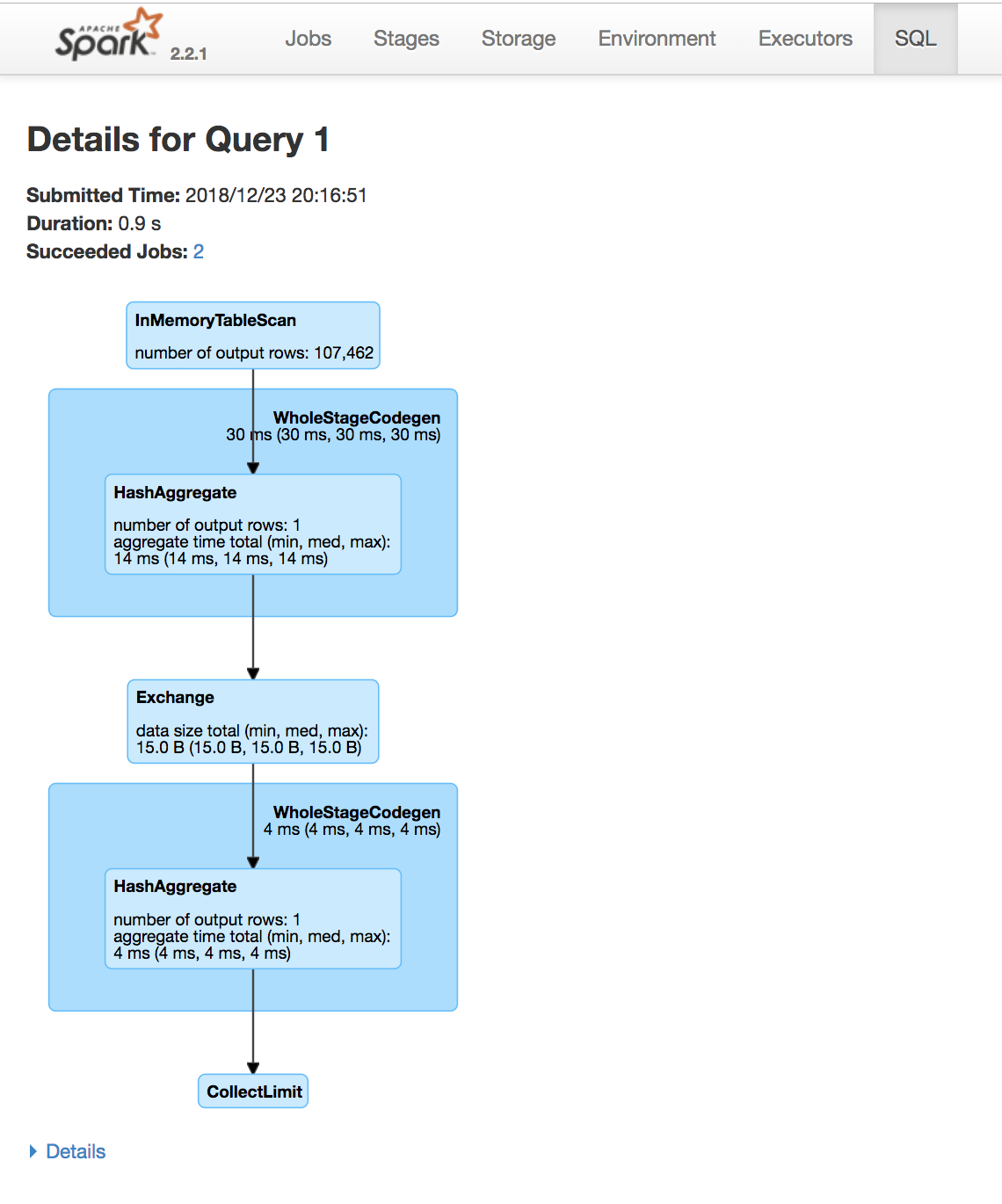
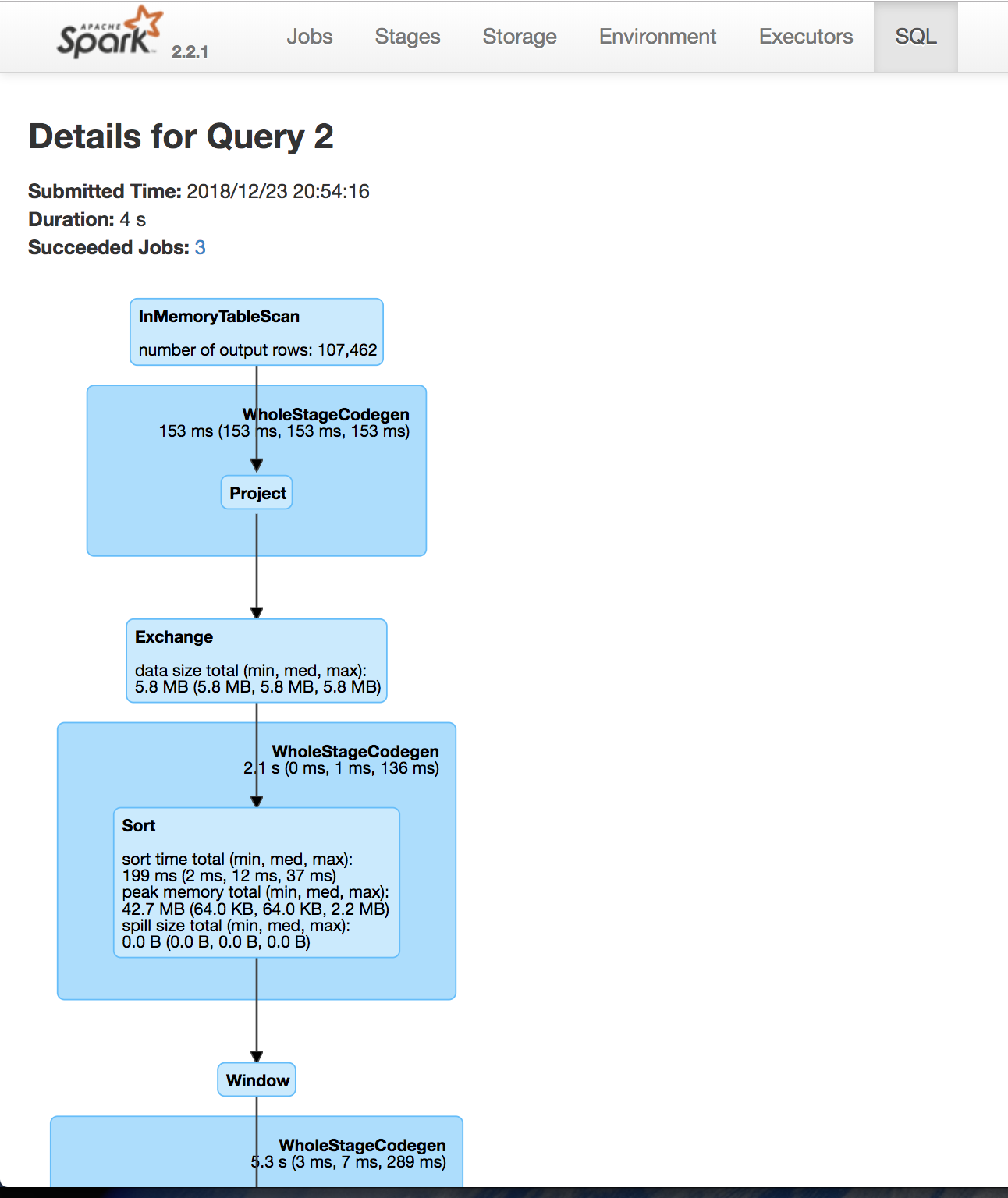
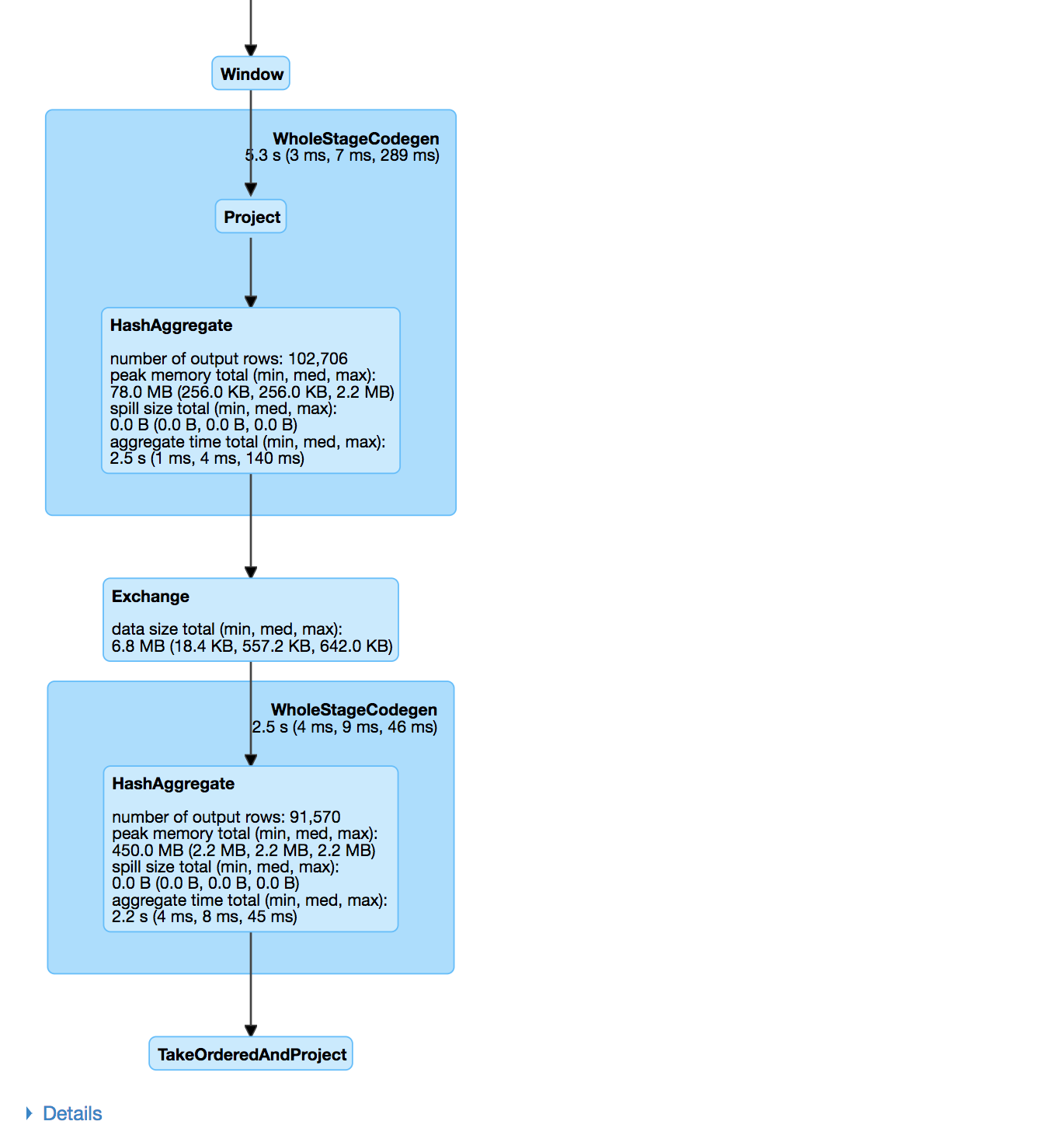
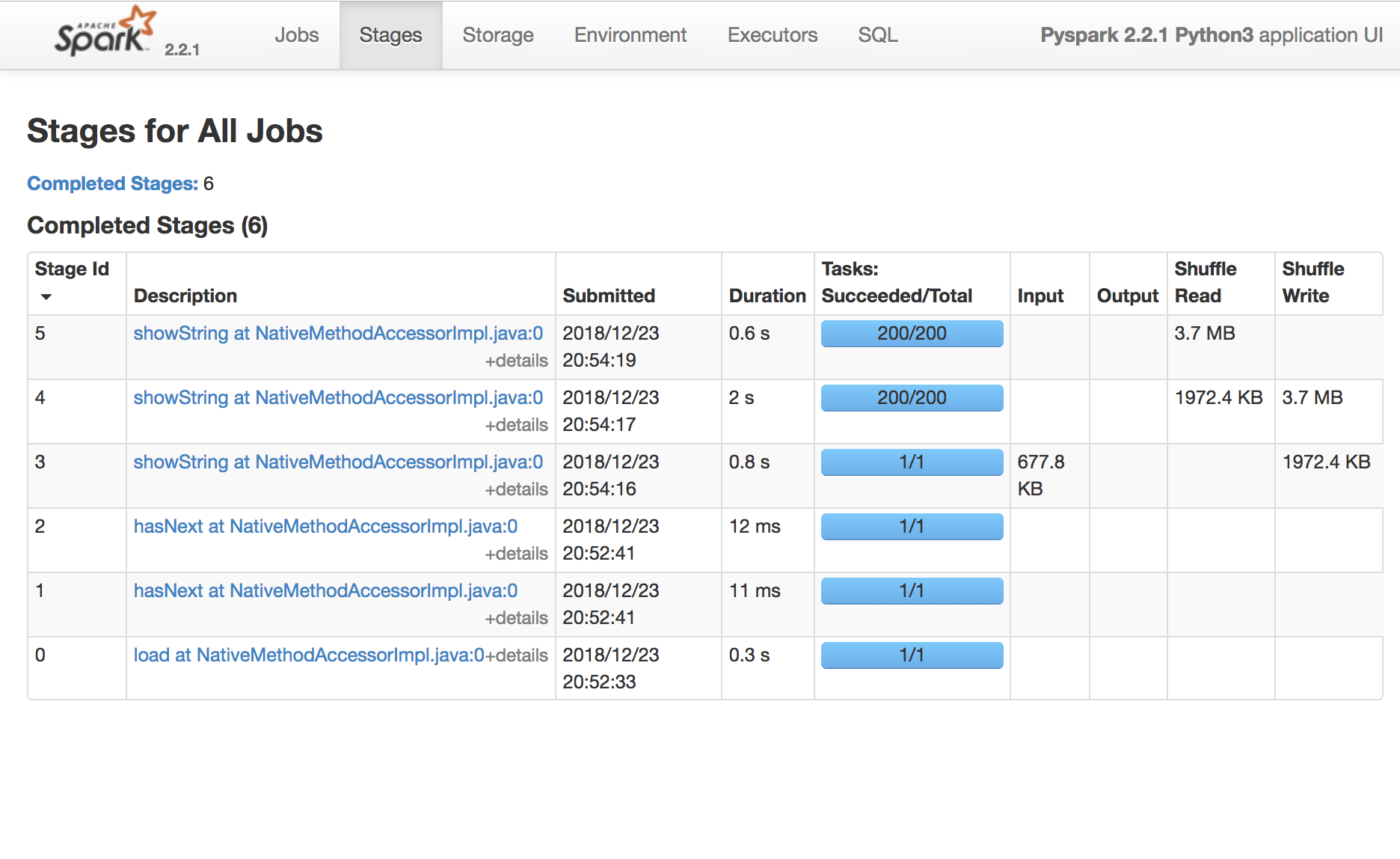
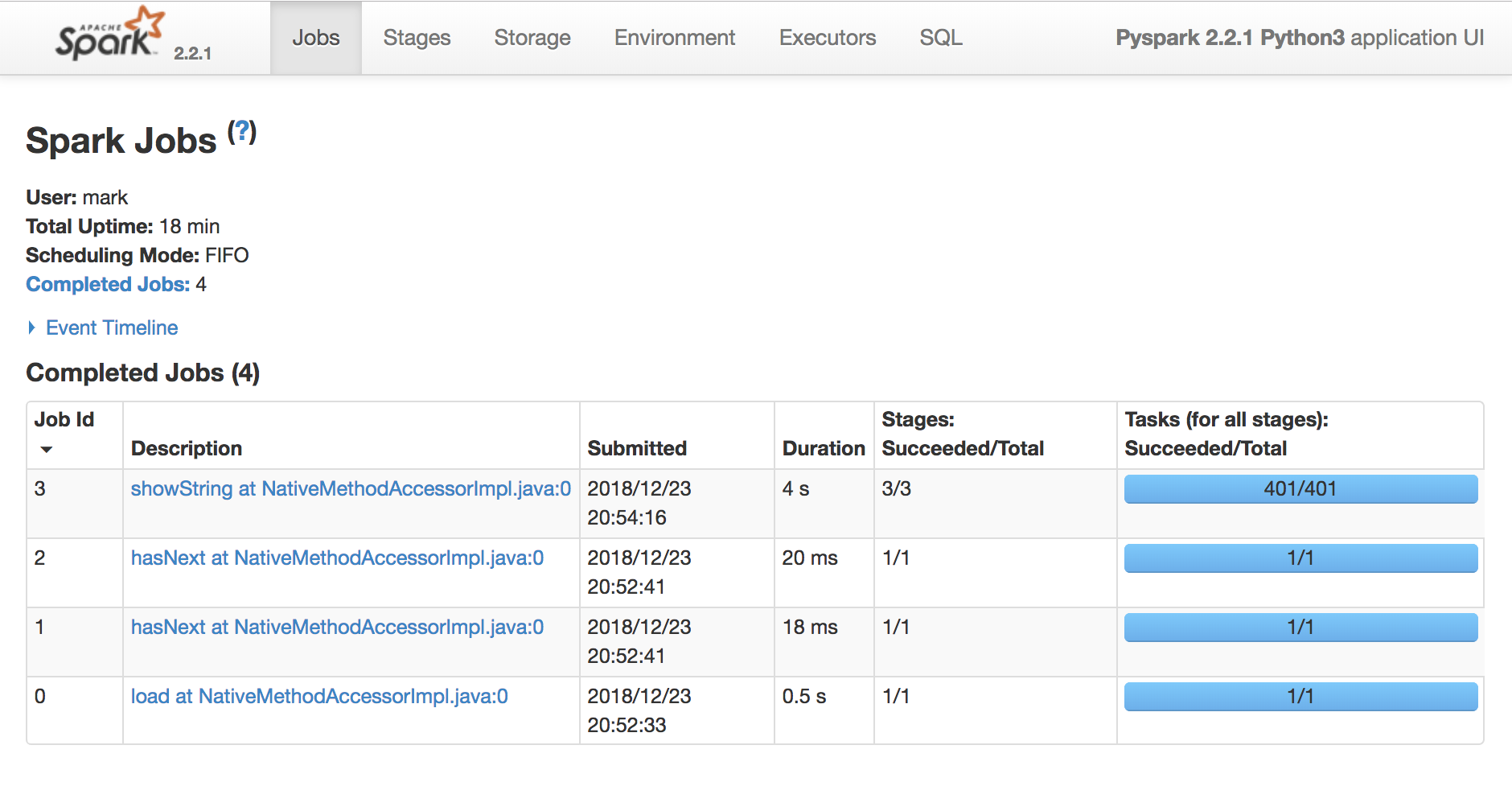
Gebruik de Spark UI om uitvoering te inspecteren
Een Spark-taak (Task) is een uitvoereenheid die op één cpu draait
Een Spark-fase (Stage) is een groep taken die dezelfde berekening parallel uitvoeren, elk meestal op een andere subset van de data
Een Spark-job is een berekening getriggerd door een actie, opgedeeld in één of meer stages.