Verdelingen per categorie met seaborn
Financiële data importeren en beheren in Python

Stefan Jansen
Instructor
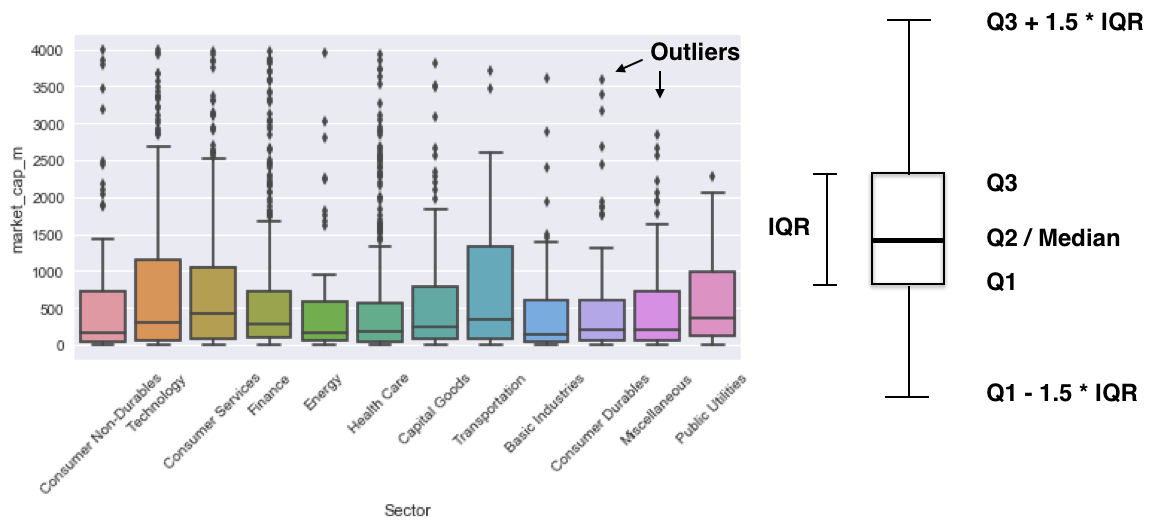
Boxplot: kwartielen en uitschieters
import seaborn as sns
sns.boxplot(x='Sector', y='market_cap_m', data=nasdaq)
plt.xticks(rotation=75);
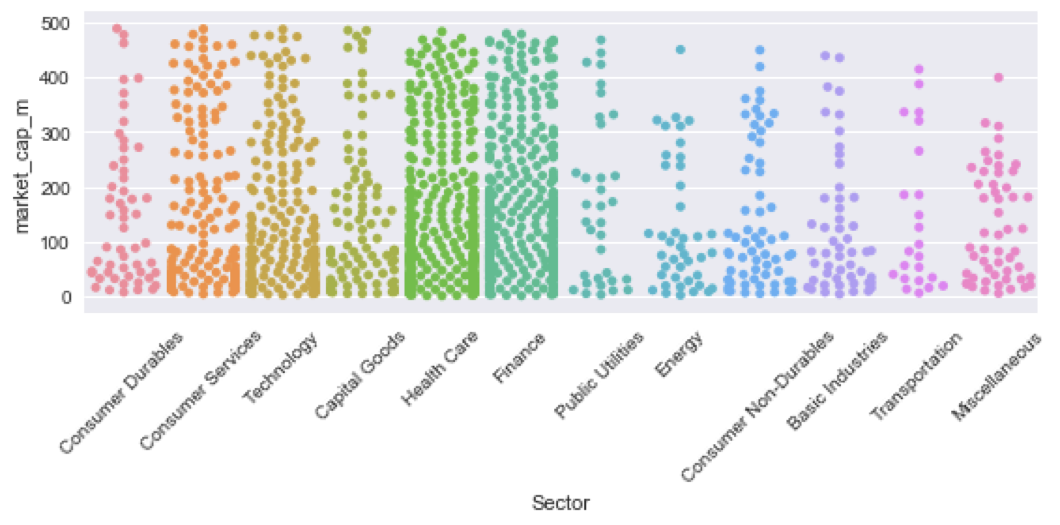
Een variant: SwarmPlot
sns.swarmplot(x='Sector', y='market_cap_m', data=nasdaq)
plt.xticks(rotation=75)
plt.show()