Data-engineering in Microsoft Fabric
Gegevens transformeren en analyseren met Microsoft Fabric

Luis Silva
Solution Architect - Data & AI
End-to-end data-analyse
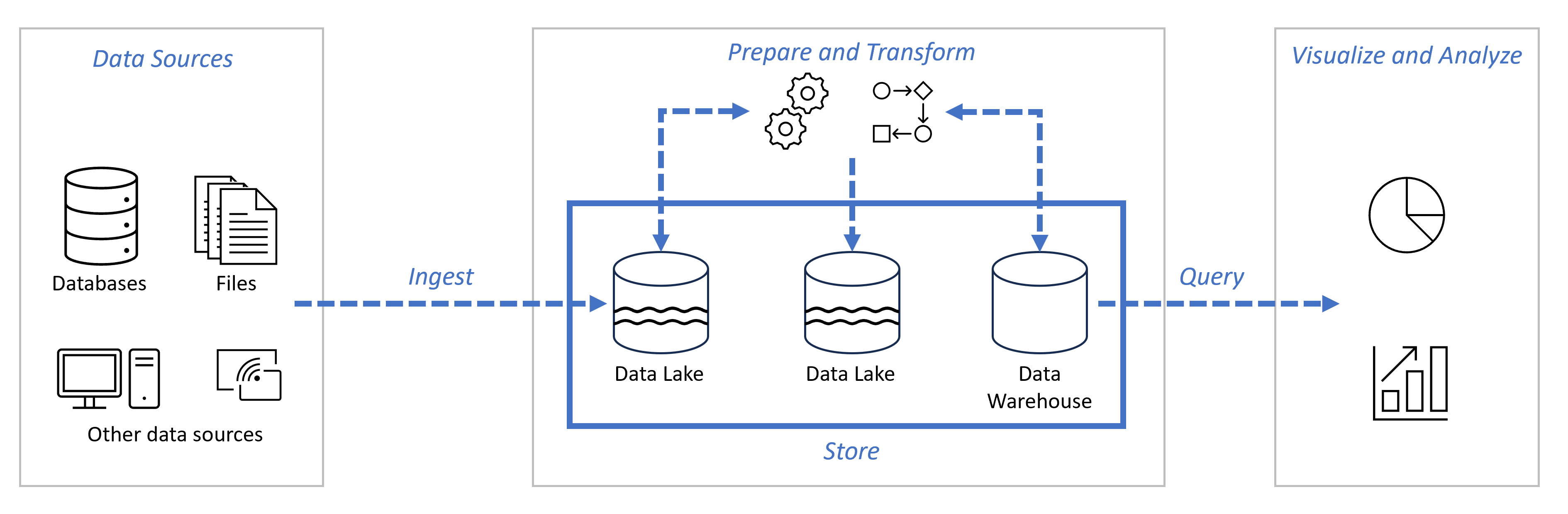
Data Factory
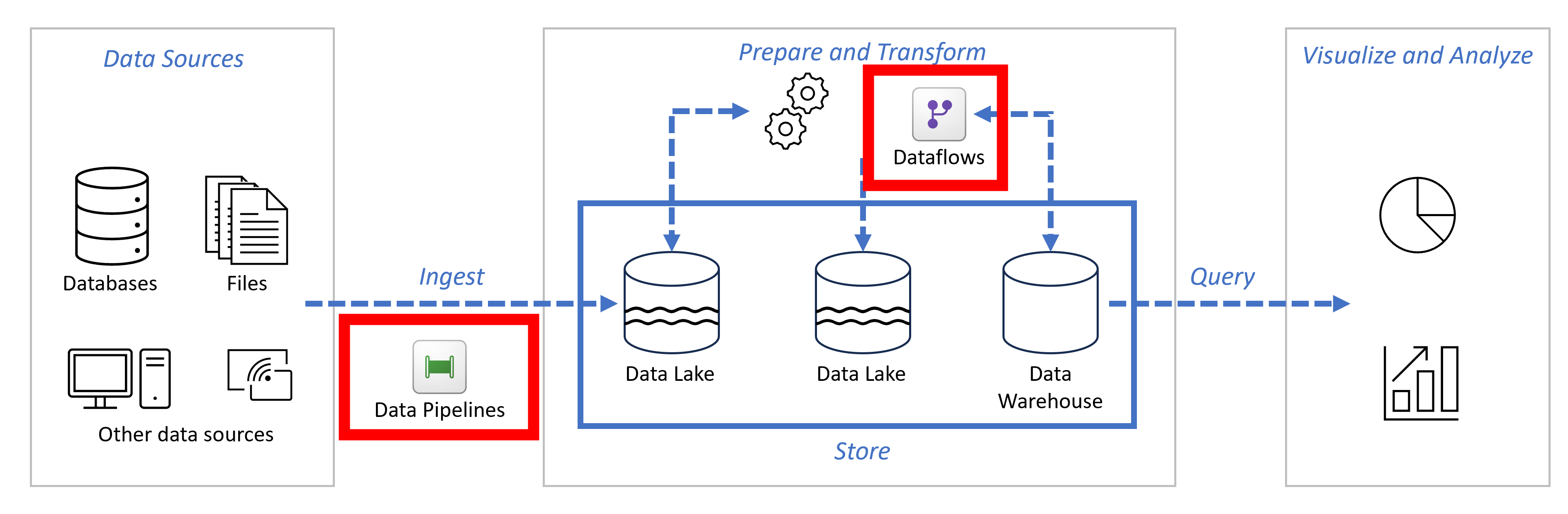
Dataflows

Data Pipelines
Synapse Data Engineering
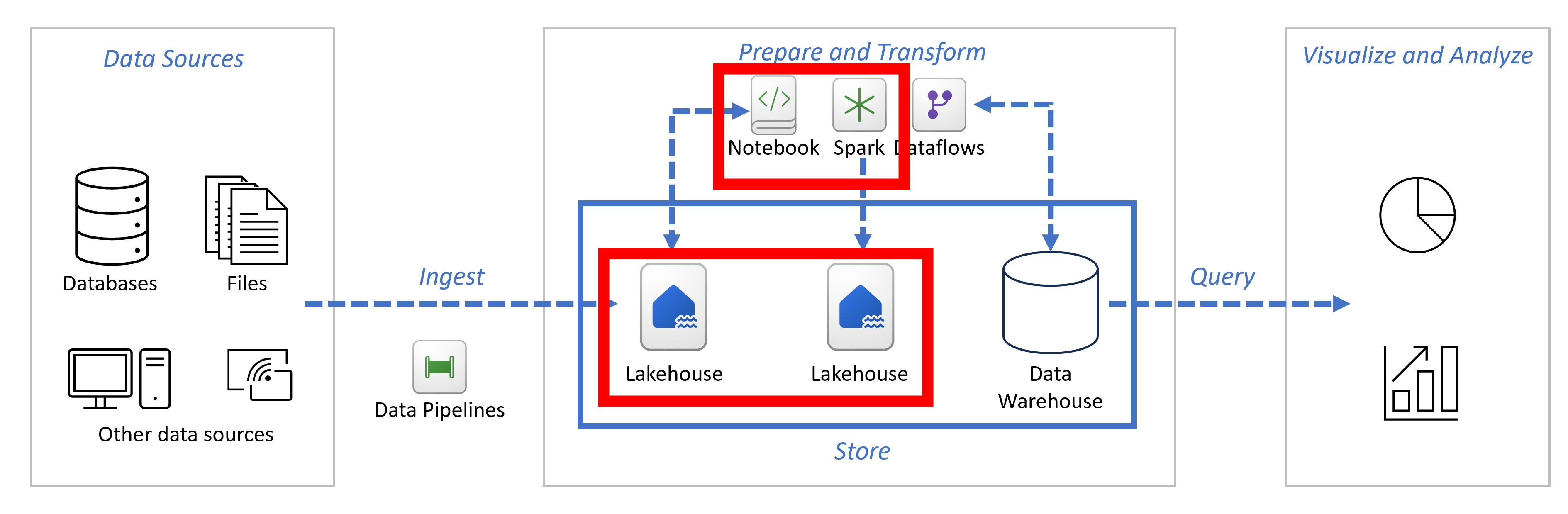
Lakehouses

Notebooks
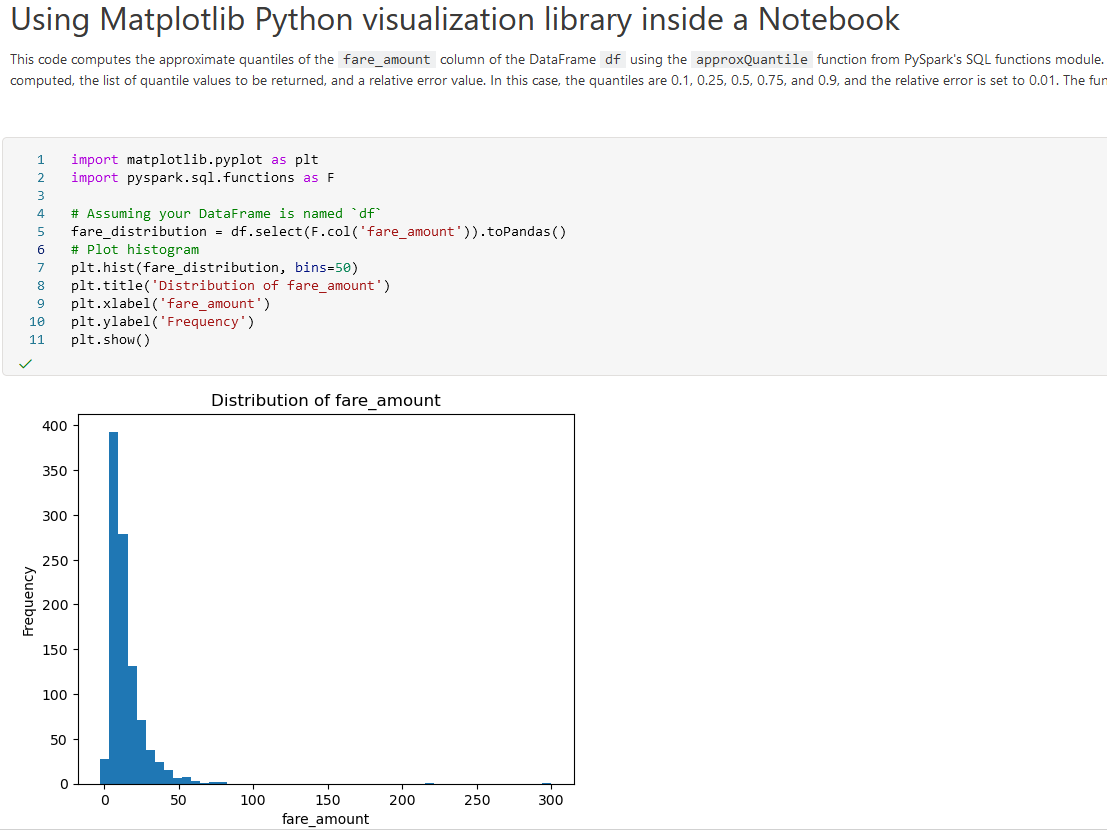
Apache Spark Job-definities
Synapse Data Warehouse

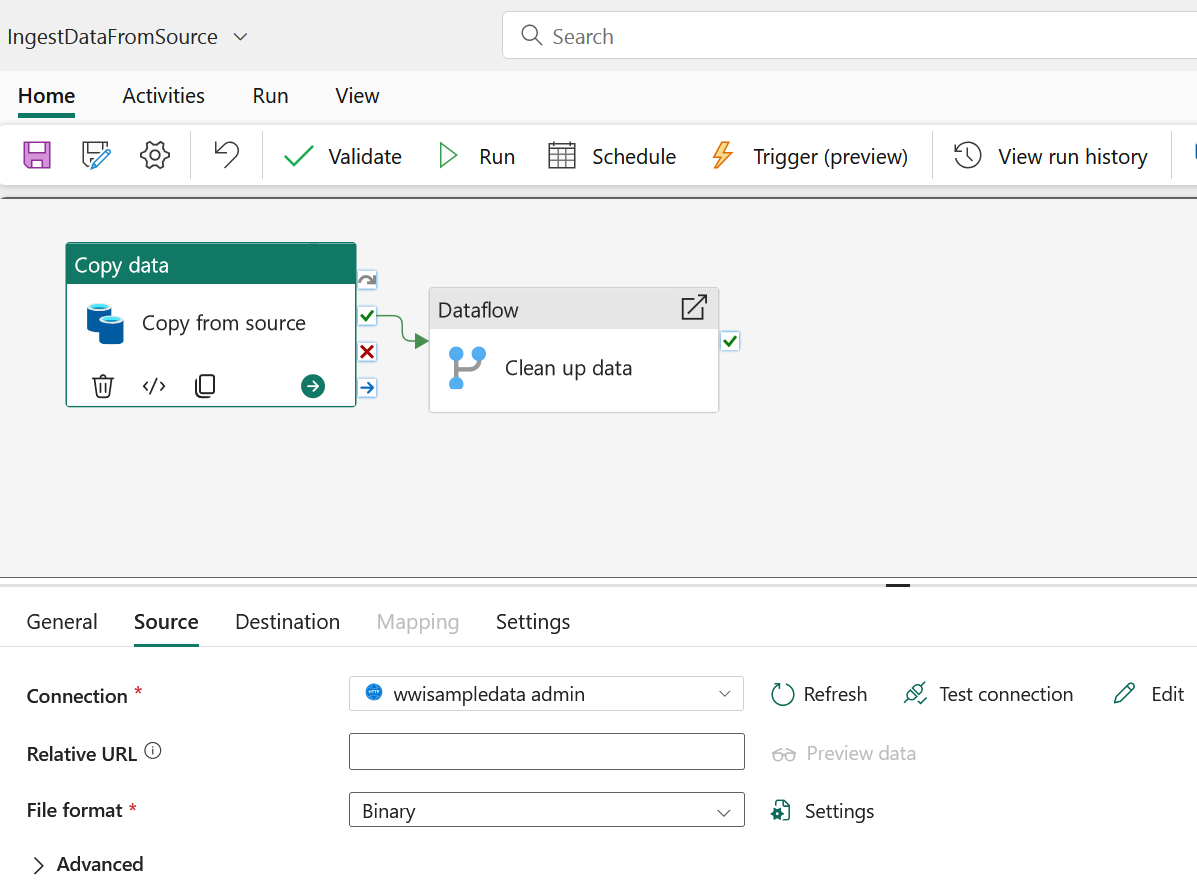
Een tool voor datakopie kiezen

Een tool voor datakopie kiezen
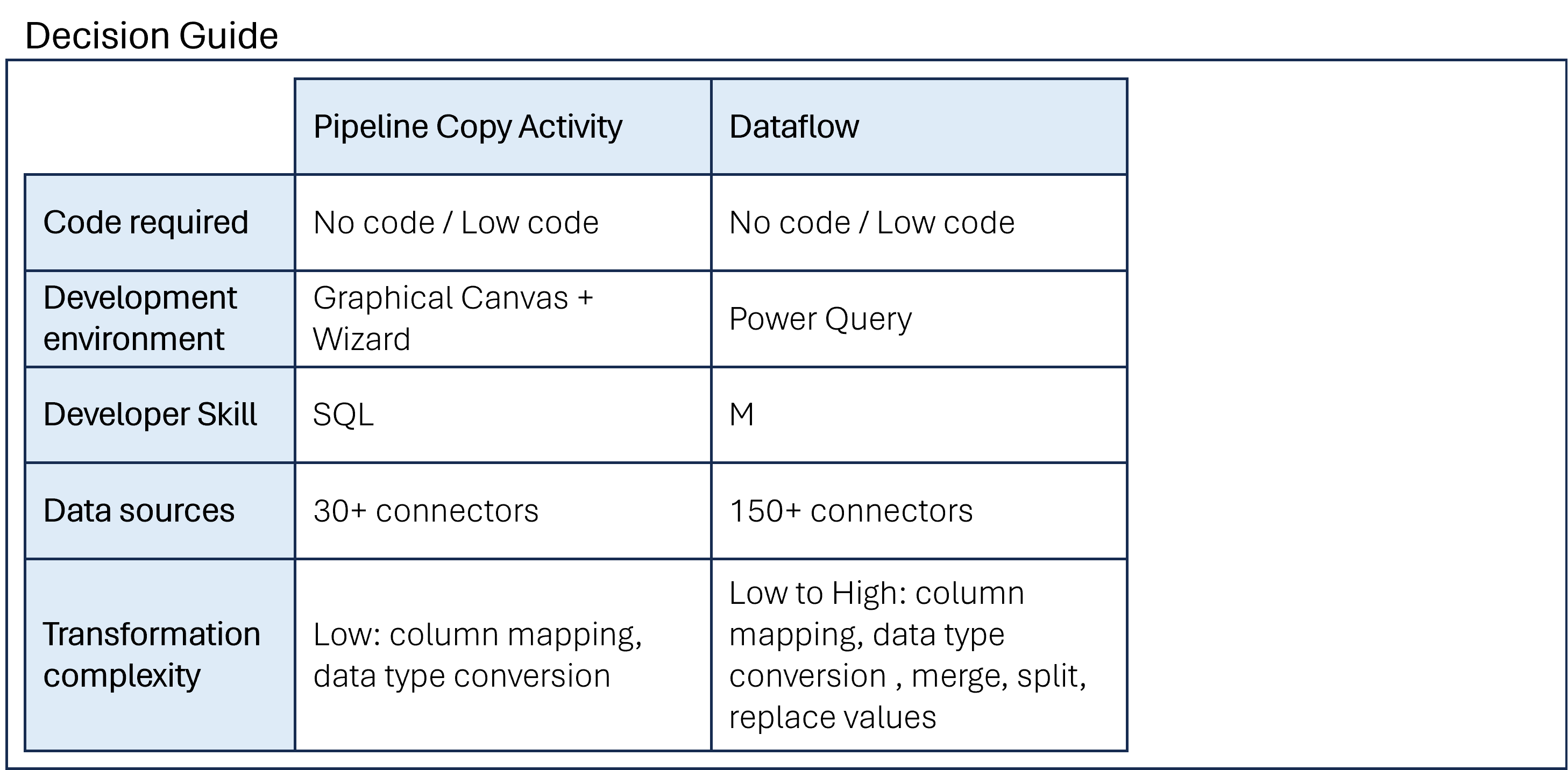
Een tool voor datakopie kiezen


