Delta Lake-tabeloptimalisatie
Gegevens transformeren en analyseren met Microsoft Fabric

Luis Silva
Solution Architect - Data & AI
Wat is Delta Lake?
- Open-source opslaglaag voor lakehouses
- ACID-transacties, metadatabeheer en versiebeheer
- Fabric gebruikt Delta Lake-tabelindeling (Parquet) als standaard
- Interoperabiliteit tussen Fabric-ervaringen

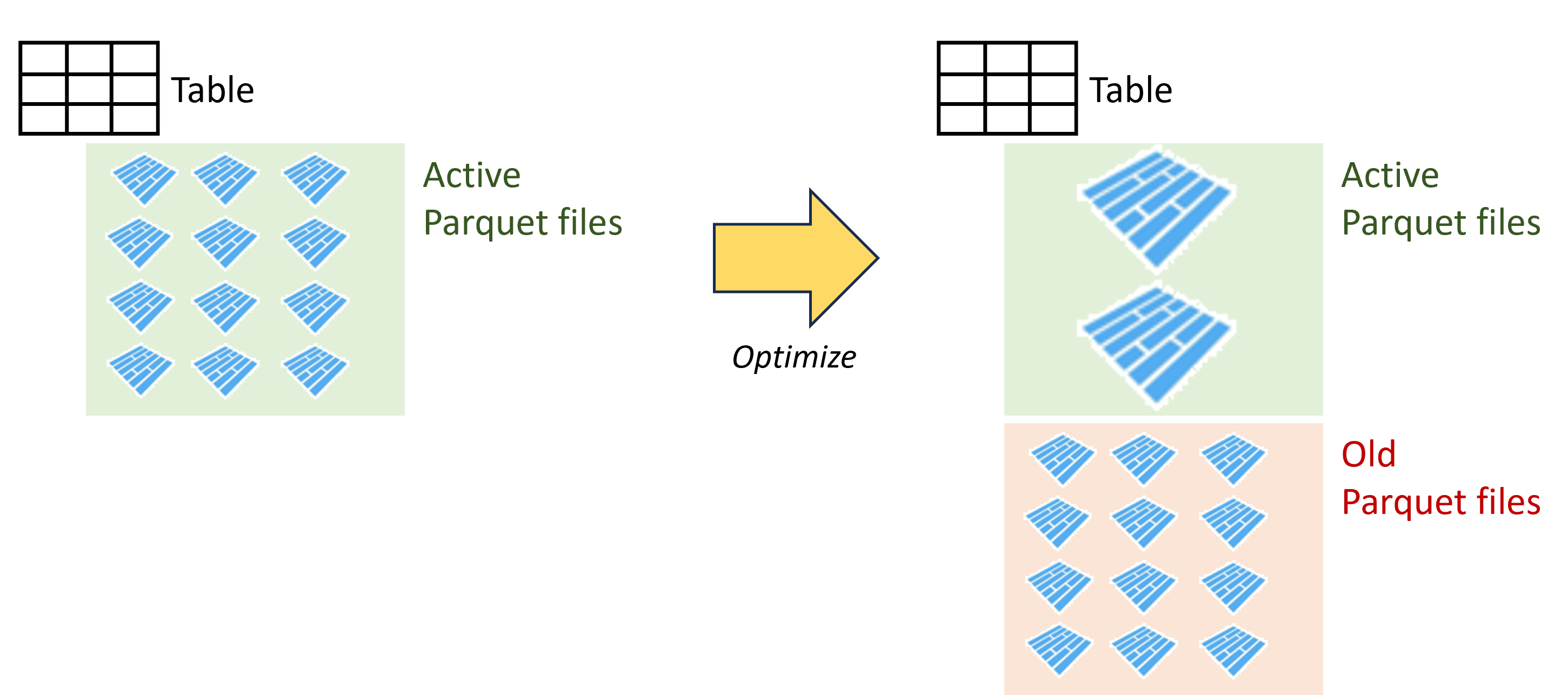
Optimize
- Bundel meerdere kleine Parquet-bestanden tot één groot bestand
- Ideale bestandsgrootte: 128 MB–1 GB
- Betere compressie en verdeling voor efficiënt lezen
- Aanraden na het laden van grote tabellen
Optimize
- Bundel meerdere kleine Parquet-bestanden tot één groot bestand
- Ideale bestandsgrootte: 128 MB–1 GB
- Betere compressie en verdeling voor efficiënt lezen
- Aanraden na het laden van grote tabellen
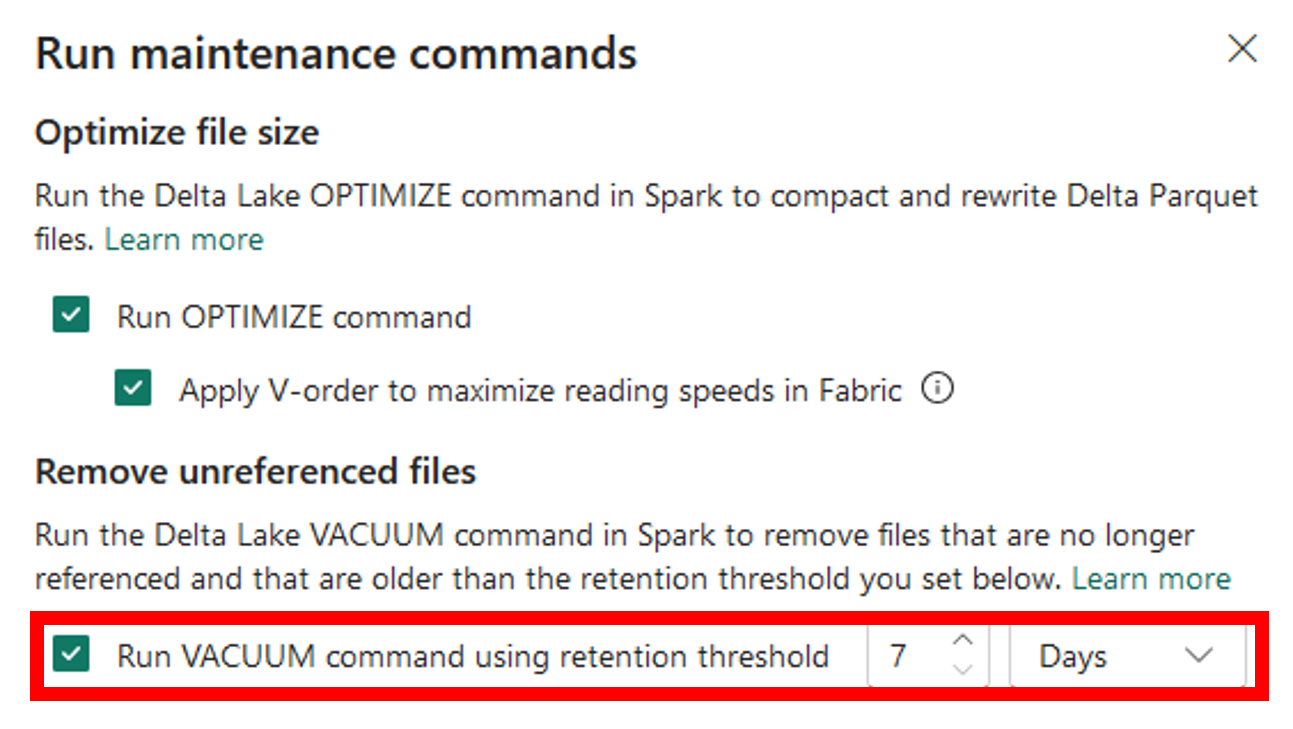
De Optimize-opdracht uitvoeren via Lakehouse Explorer
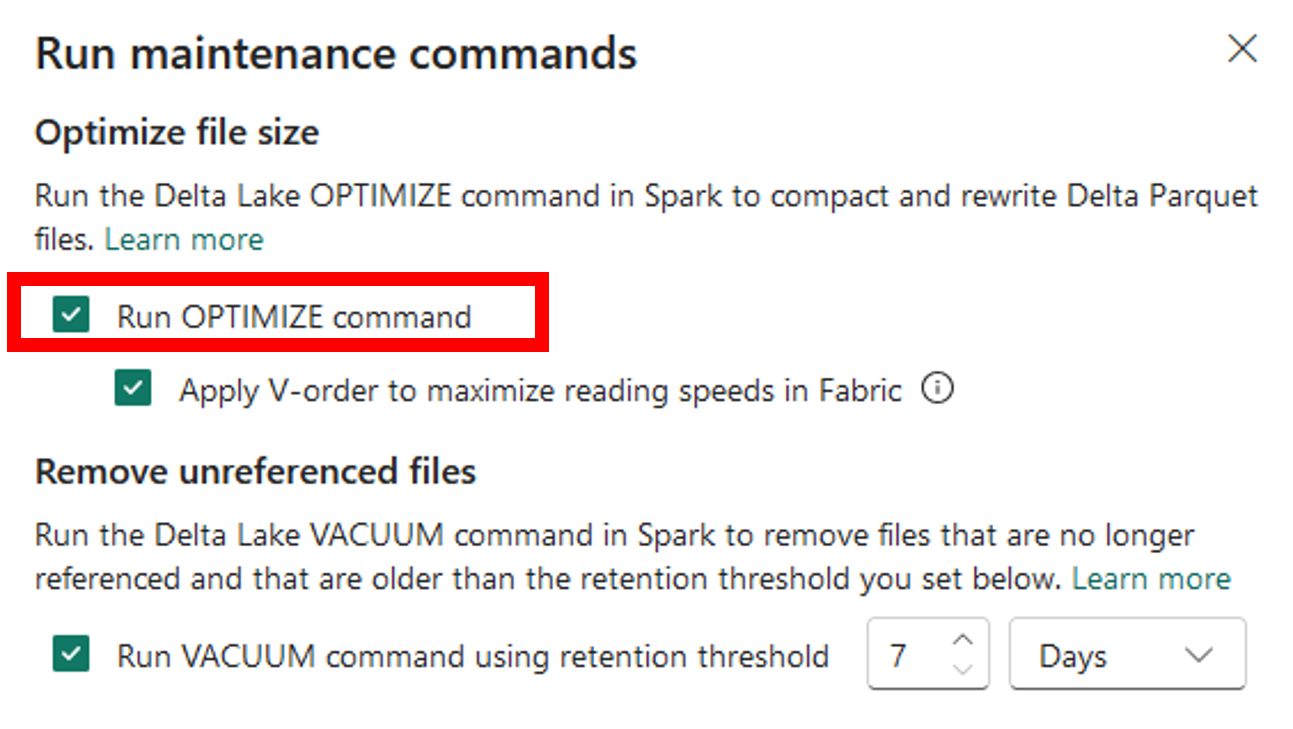
V-Order toepassen via Lakehouse Explorer
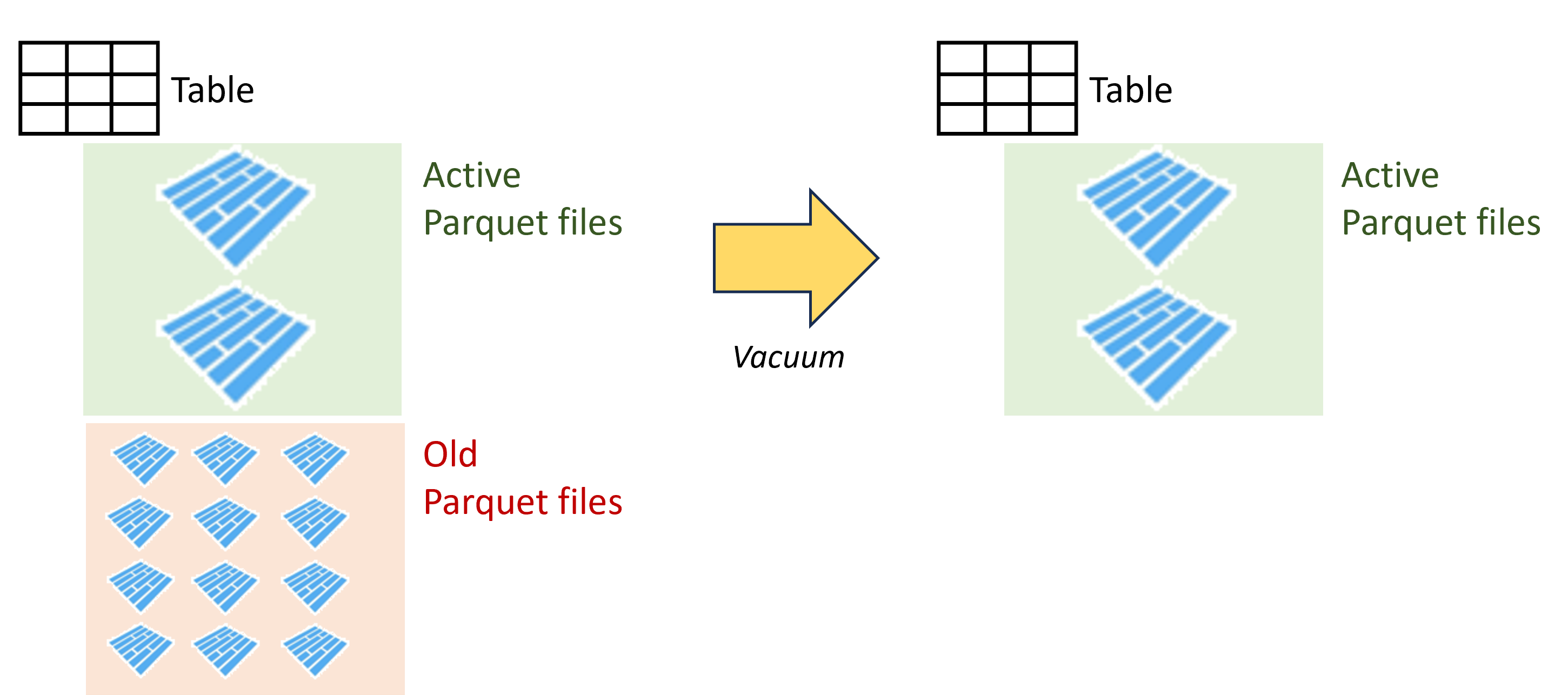
Vacuum
- Verwijder oude, overbodige bestanden ouder dan de retentiedrempel
- Verlaag cloudopslagkosten
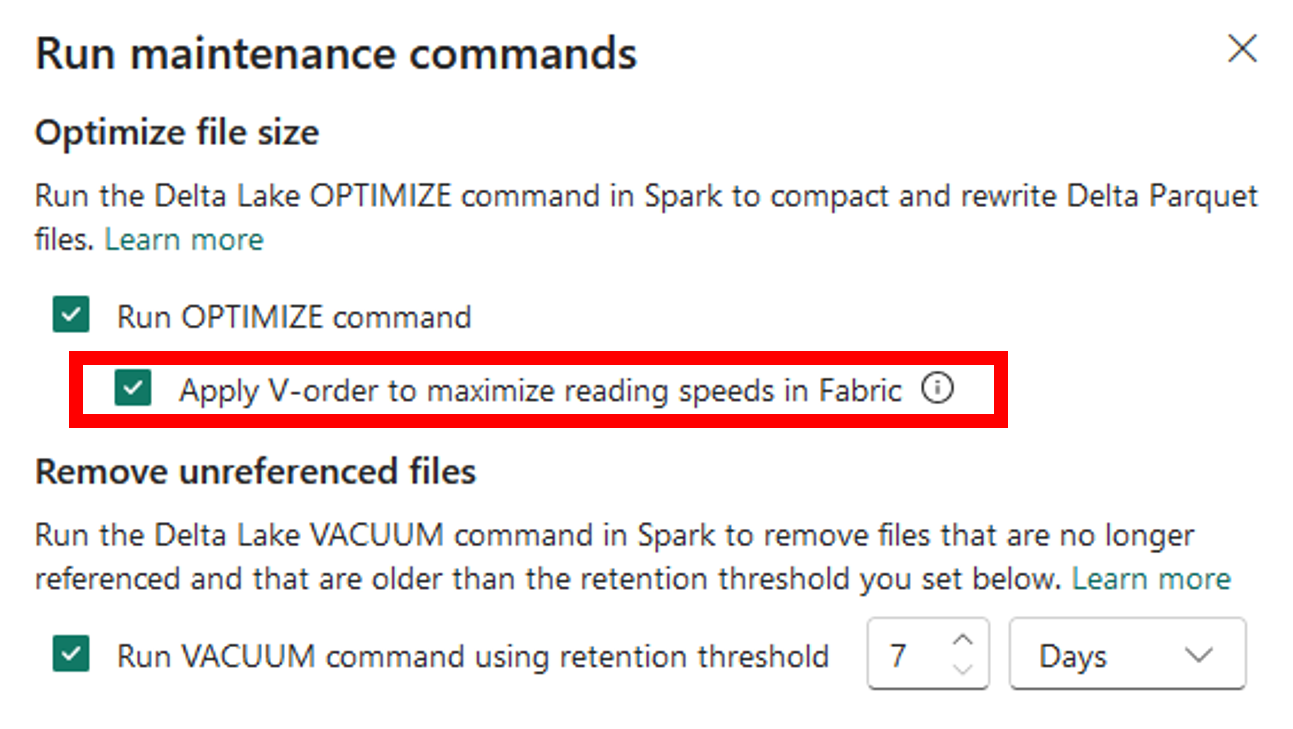
Vacuum
- Verwijder oude, overbodige bestanden ouder dan de retentiedrempel
- Verlaag cloudopslagkosten
Vacuum uitvoeren via Lakehouse Explorer