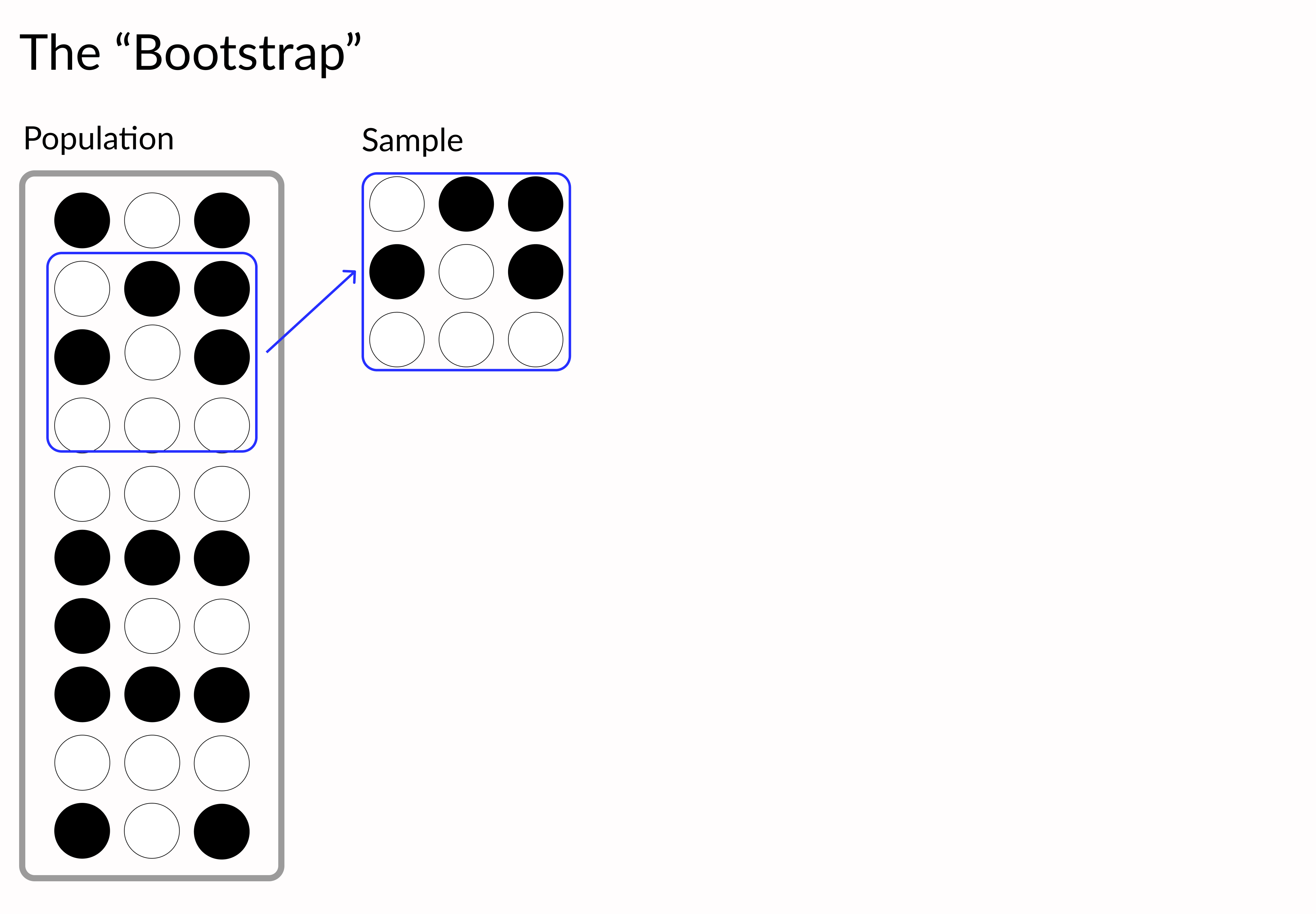
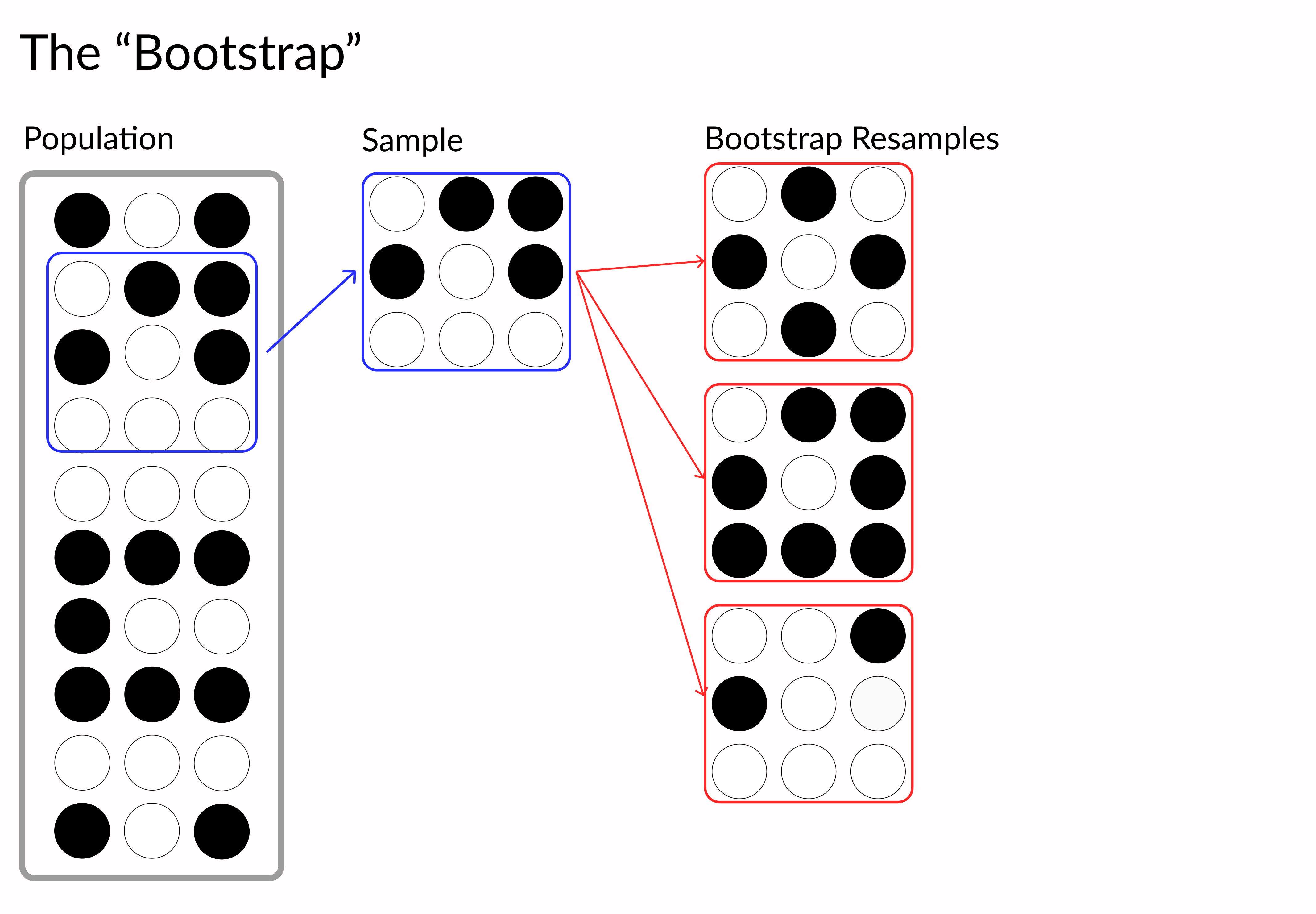
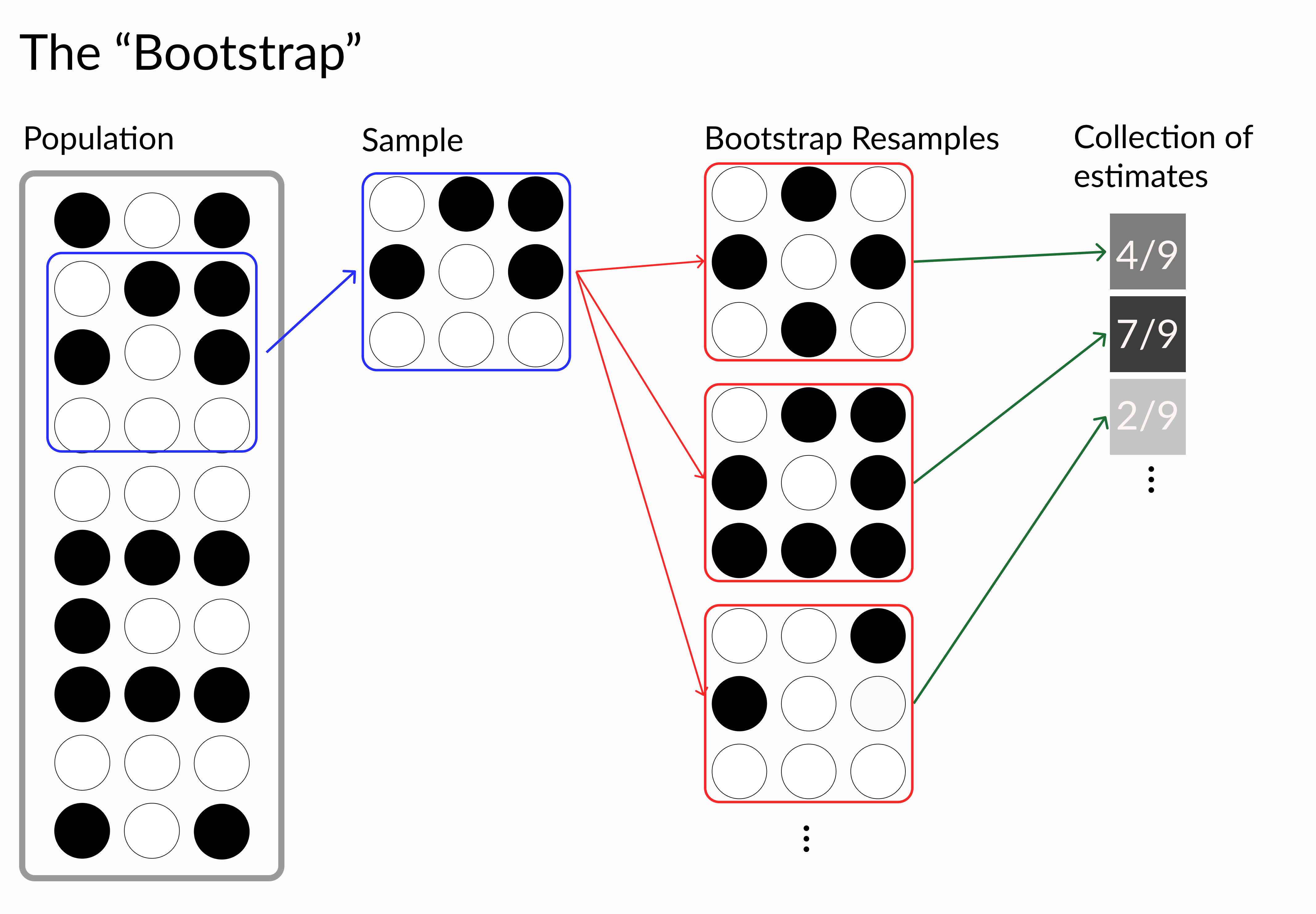
denver_may = pollution.query("city == 'Denver' & month == 8")
# Perform bootstrapped mean on a vector
def bootstrap(data, n_boots):
return [np.mean(np.random.choice(data,len(data)))
for _ in range(n_boots) ]
# Generate 1,000 bootstrap samples
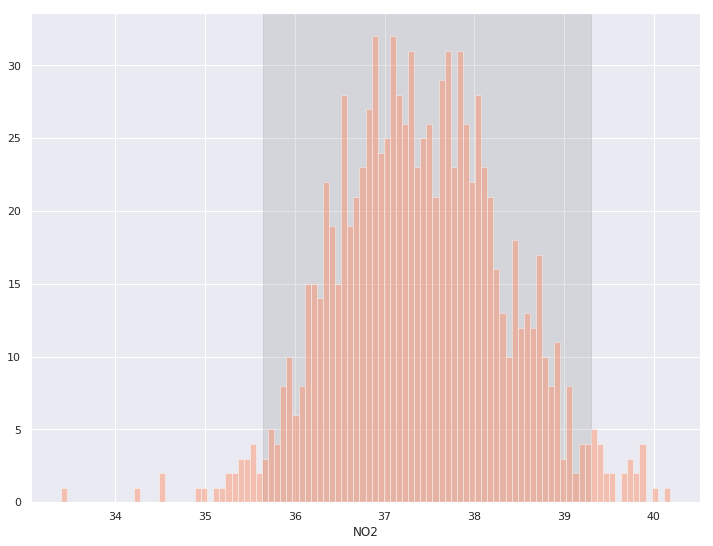
boot_means = bootstrap(denver_may.NO2, 1000)
# Get lower and upper 95% interval bounds
lower, upper = np.percentile(boot_means, [2.5, 97.5])
# Shaded background of interval
plt.axvspan(lower, upper, color='grey', alpha=0.2)
# Plot histogram of samples
sns.histplot(boot_means, bins = 100)
# Maak een DataFrame met bootstrap-data
denver_may_boot = pd.concat([
denver_may.sample(n=len(denver_may), replace=True).assign(sample=i)
for i in range(100)])
# Plot regressies per sample
sns.lmplot('CO', 'O3', data=denver_may_boot, scatter=False,
# Laat seaborn voor elke resample een regressielijn tekenen
hue='sample',
# Lijnen oranje en transparant maken
line_kws = {'color': 'coral', 'alpha': 0.2},
# Geen betrouwbaarheidsintervallen
ci=None, legend = False)
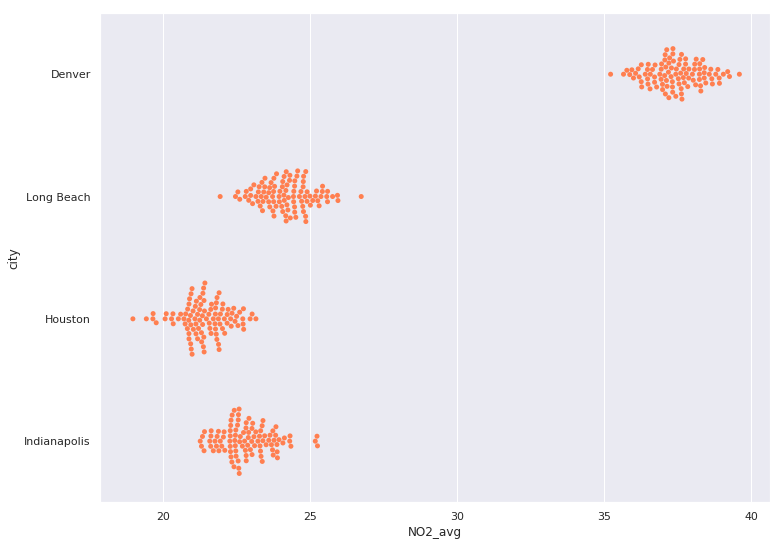
aug_pol = pollution.query("month == 8")
# DataFrame voor bootstrap-samples
city_boots = pd.DataFrame()
for city in ['Denver', 'Long Beach', 'Houston', 'Indianapolis']:
# Filter NO2 van de stad
city_NO2 = aug_pol[aug_pol.city == city].NO2
# 100 bootstrap-samples van NO2 van de stad en in DataFrame zetten
cur_boot = pd.DataFrame({ 'NO2_avg': bootstrap(city_NO2, 100),
'city': city })
# Toevoegen aan andere boots
city_boots = pd.concat([city_boots,cur_boot])
# Visualiseer bootstrap-samples met beeswarm-plot
sns.swarmplot(y="city", x="NO2_avg", data=city_boots,
# Alle kleuren gelijk zetten
color='coral')