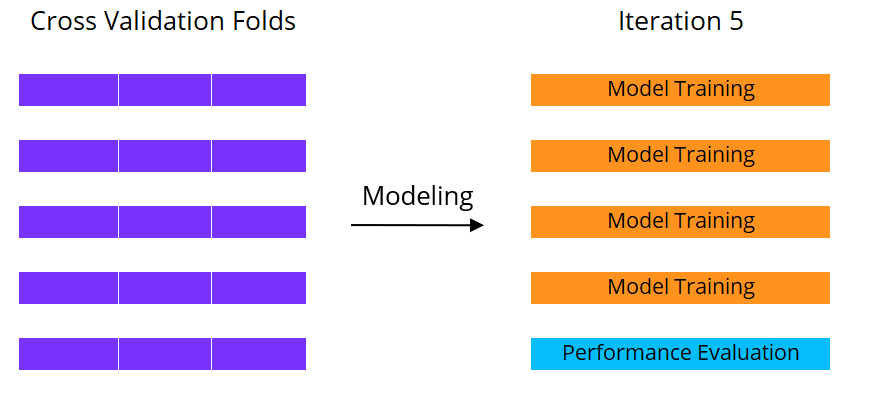
Prestaties inschatten met cross-validatie
Modelleren met tidymodels in R

David Svancer
Data Scientist
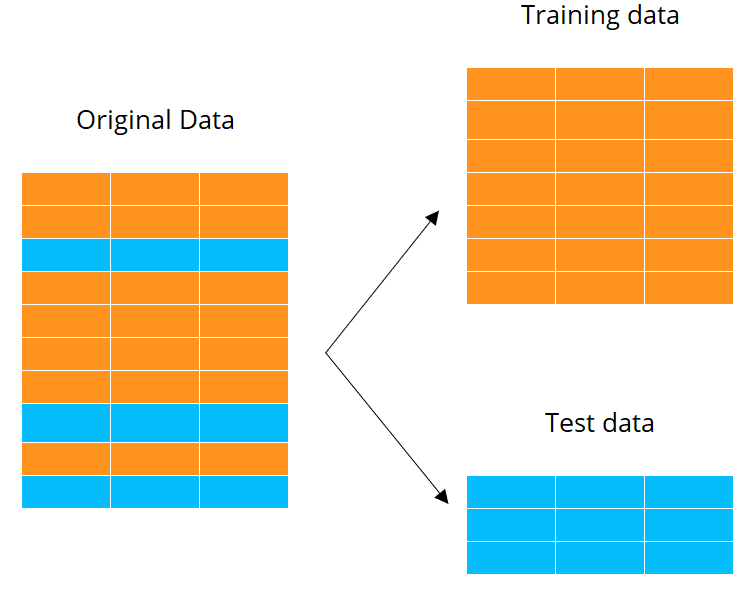
Trainings- en testdatasets
K-voudige cross-validatie
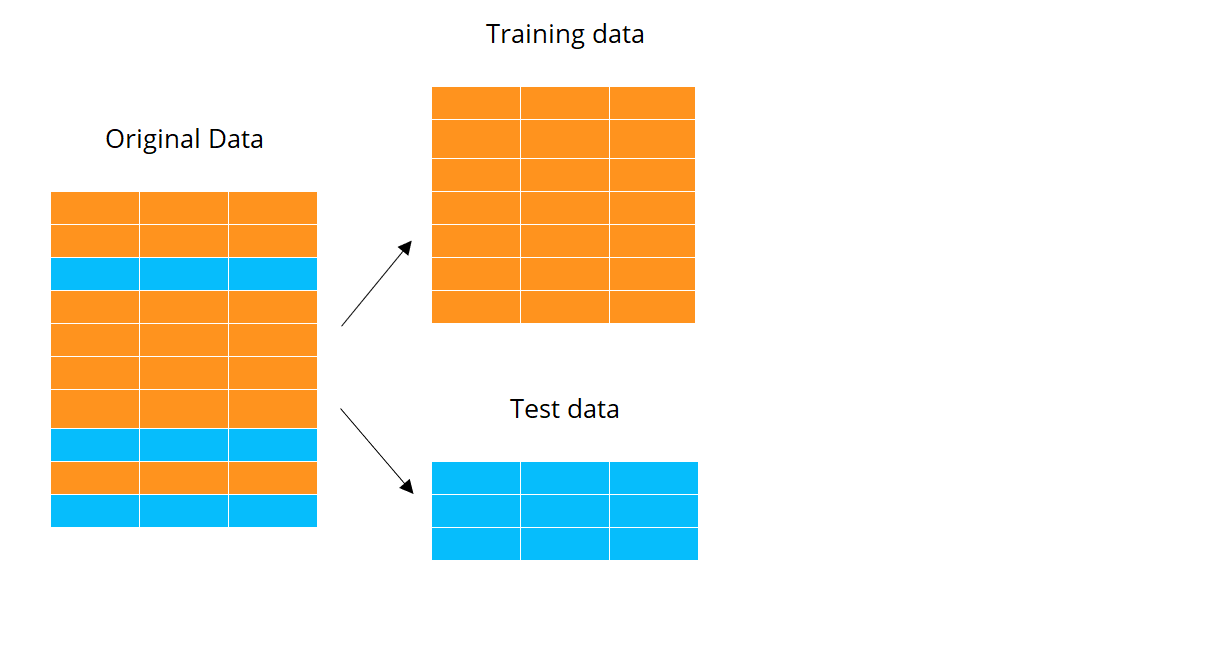
K-voudige cross-validatie
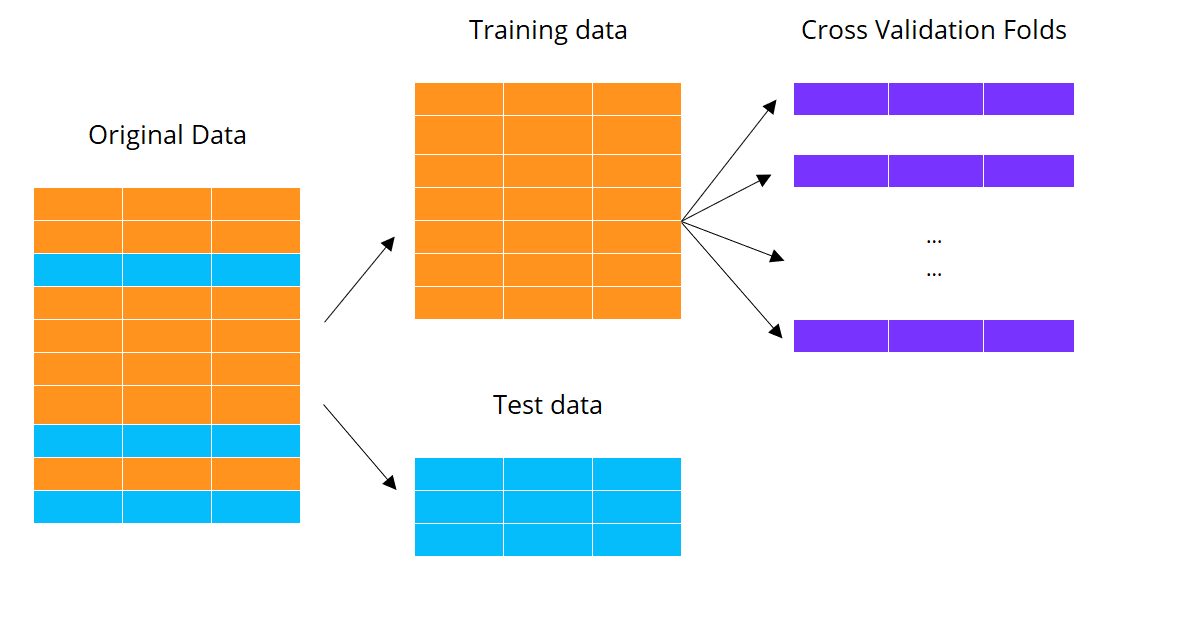
Machine learning met cross-validatie
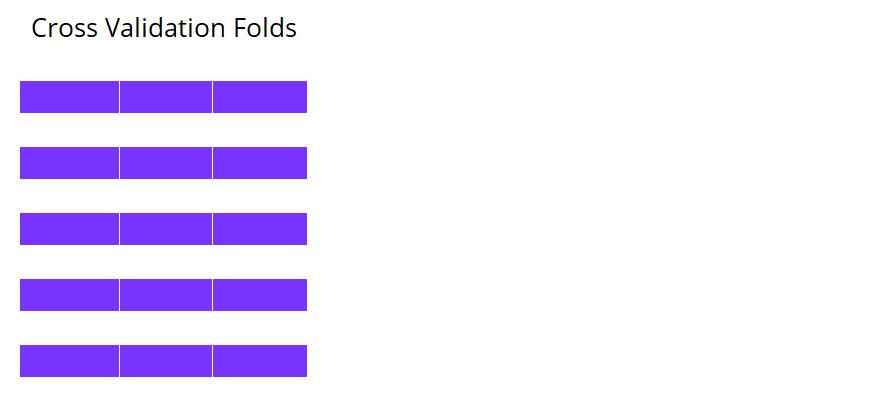
Machine learning met cross-validatie
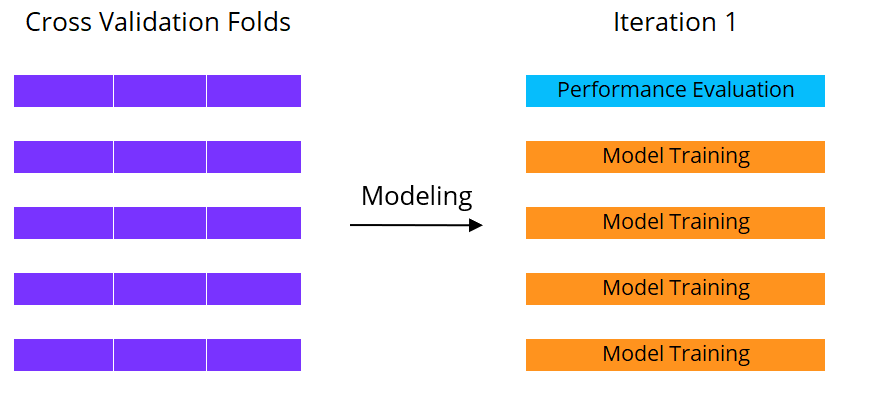
Machine learning met cross-validatie
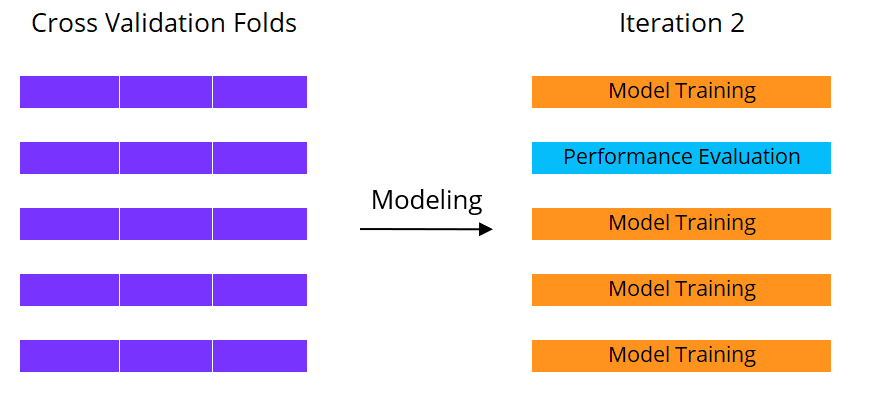
Machine learning met cross-validatie