Machine learning-workflows
Modelleren met tidymodels in R

David Svancer
Data Scientist
Classificatie met beslisbomen
Classificatie met beslisbomen
Classificatie met beslisbomen
Classificatie met beslisbomen
Classificatie met beslisbomen
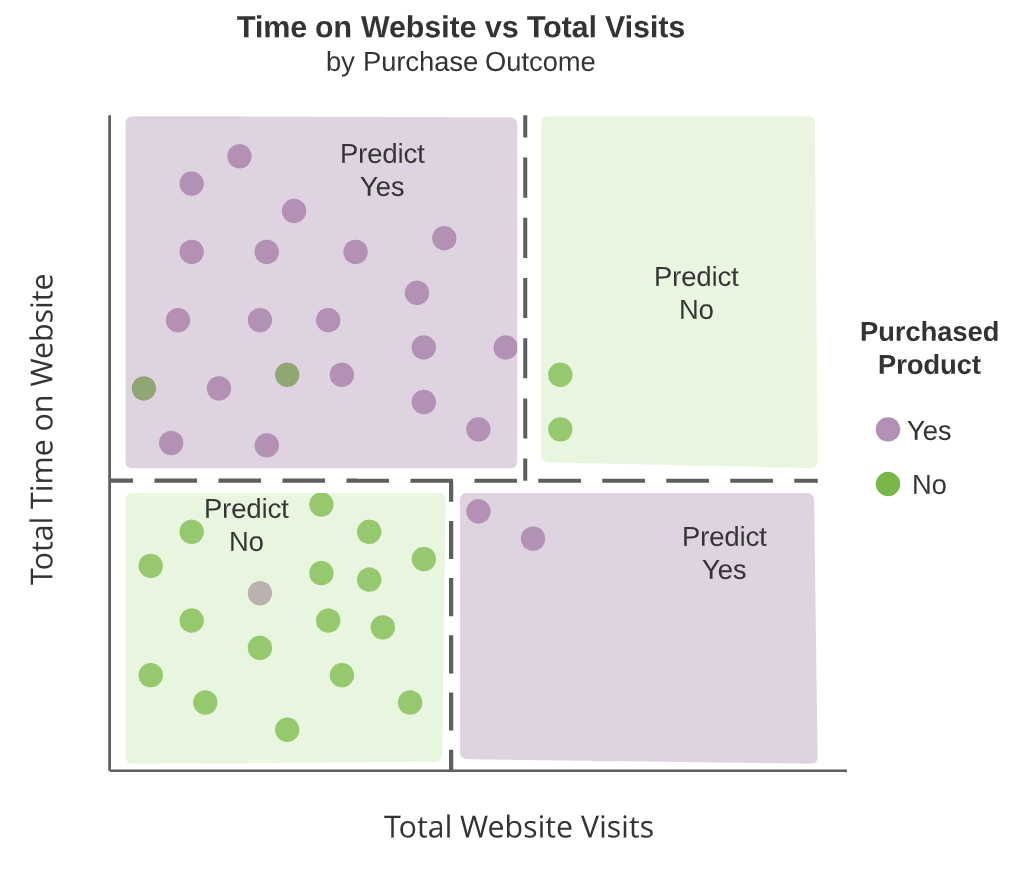
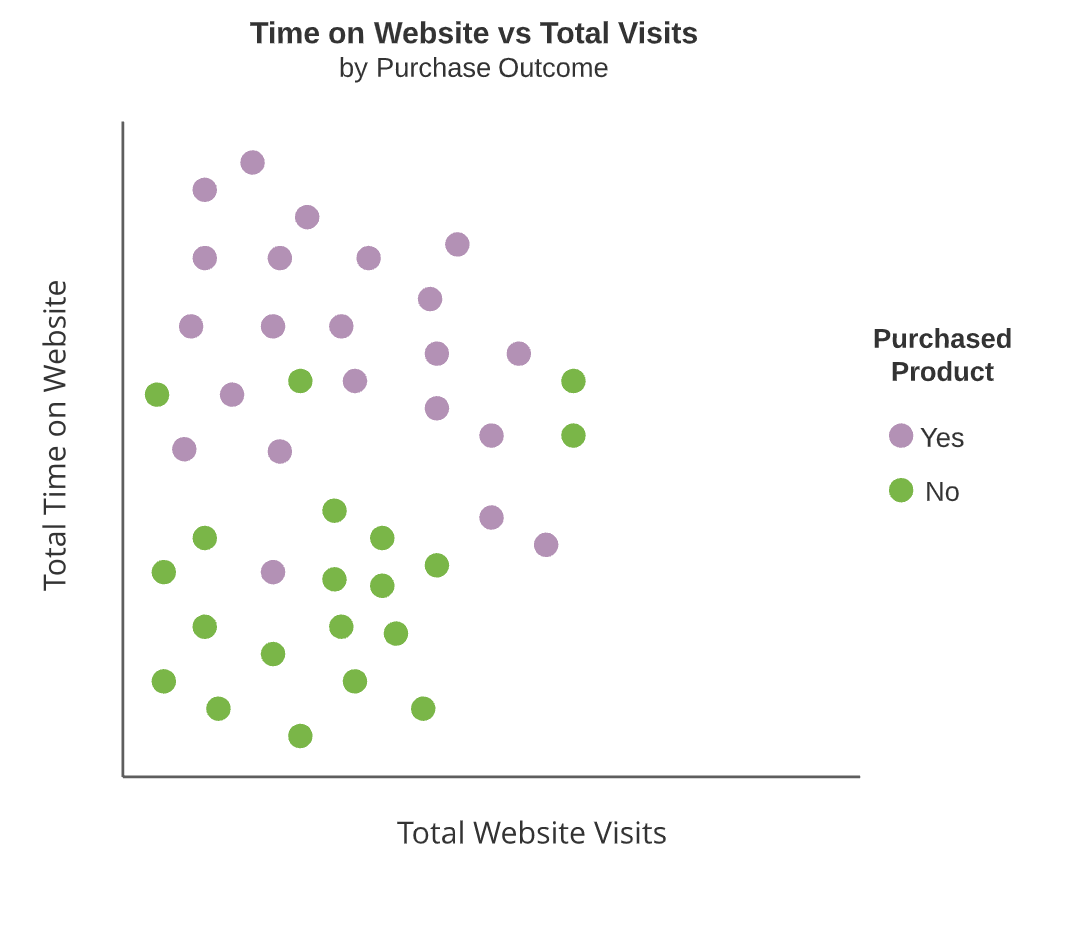
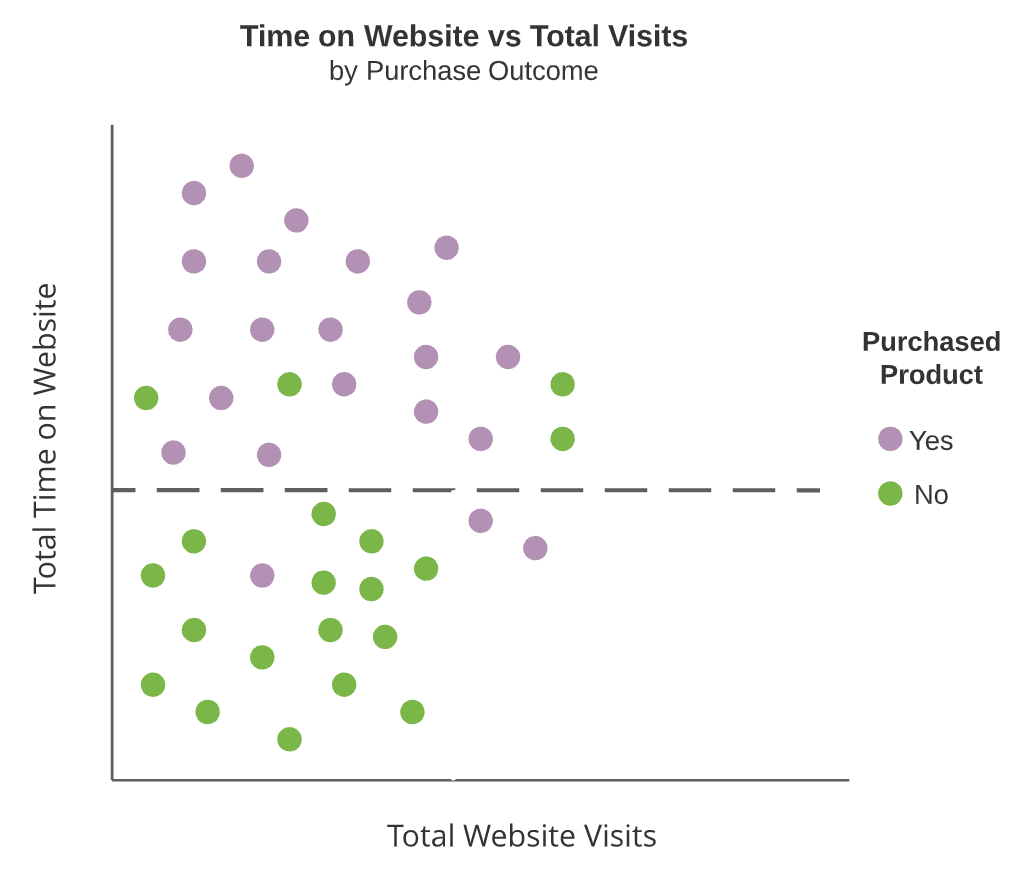
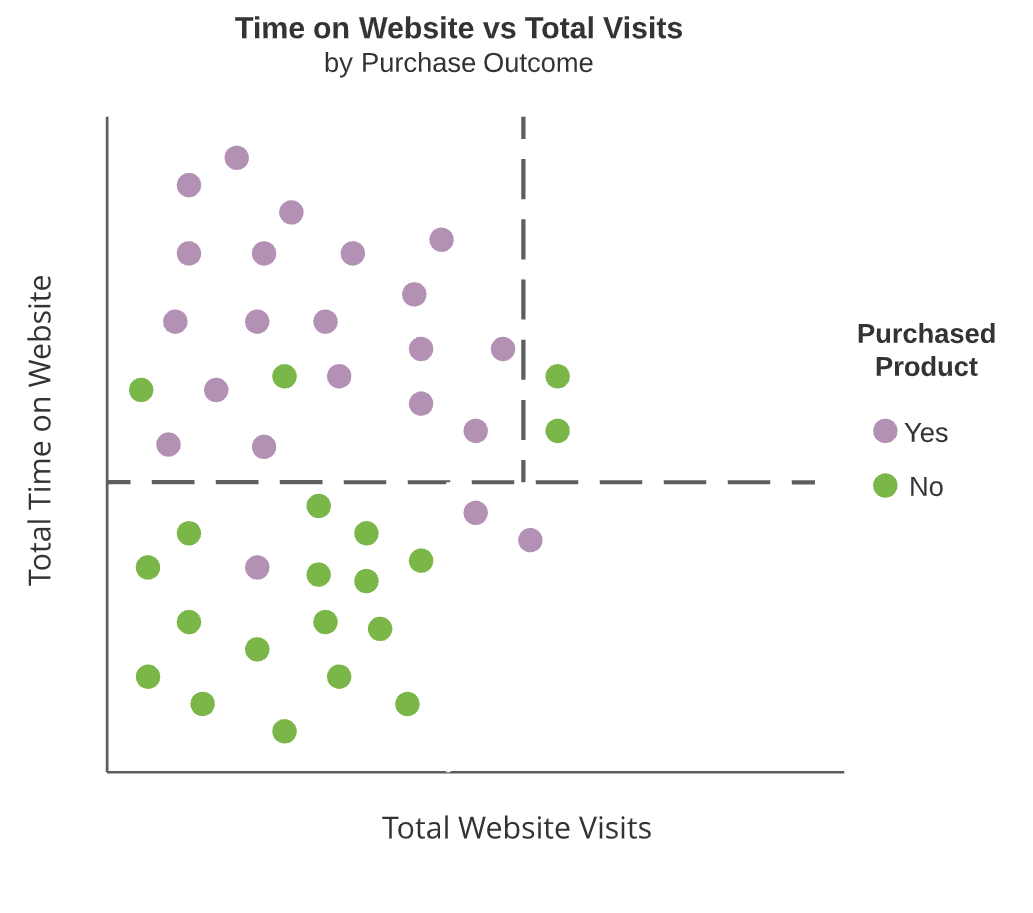
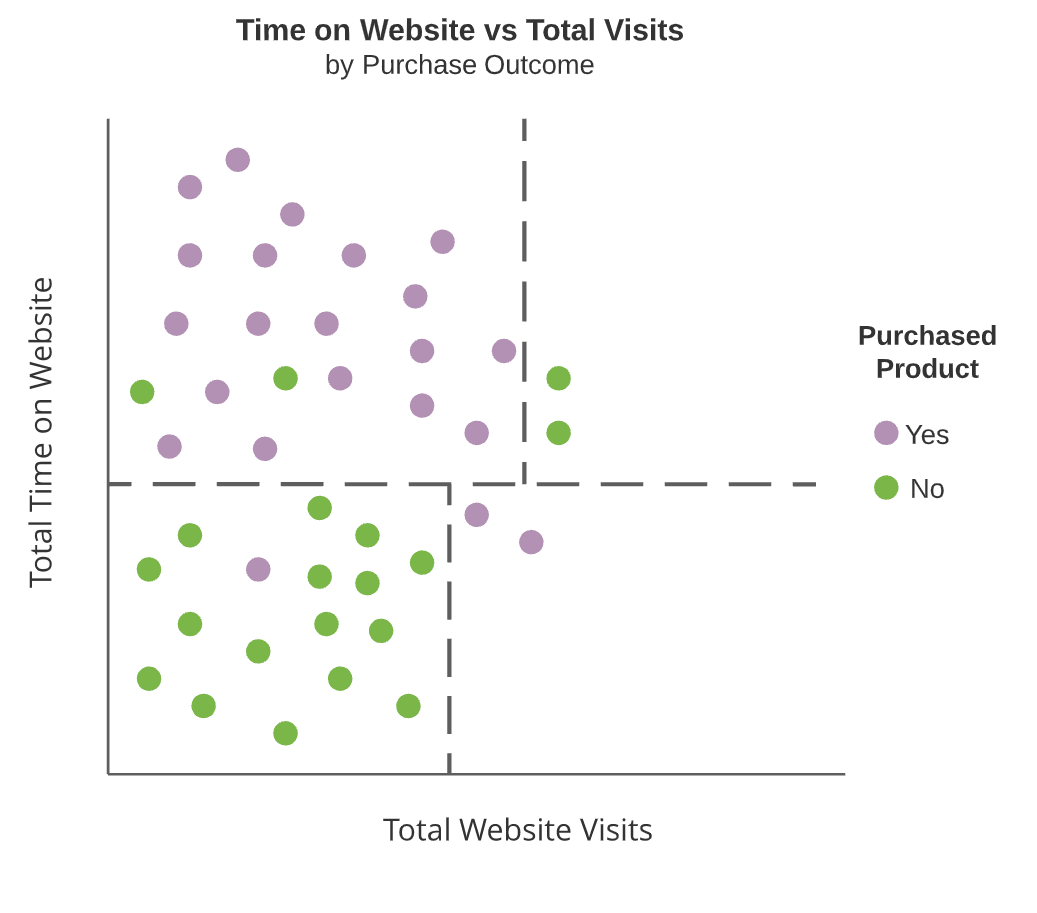
Boomdiagrammen
- Interne knopen
- Splitsingen in de beslisboom (donkere vakken)
- Terminale knopen
- Regio’s die niet verder worden gesplitst
- Groene en paarse vakken
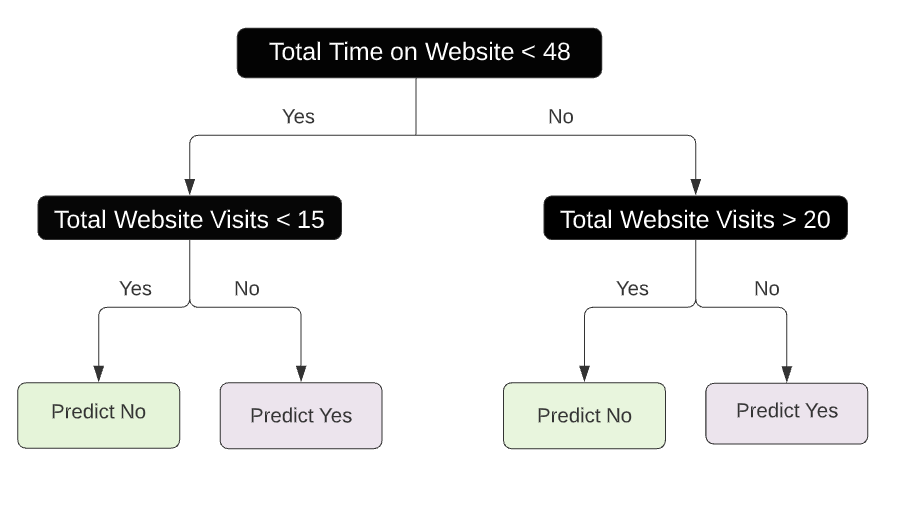
Interne knopen zijn stippellijnen en terminale knopen zijn gemarkeerde rechthoeken

