Profielen en segmenten interpreteren
Klantsegmentatie in Python

Karolis Urbonas
Head of Data Science, Amazon
Samenvattende statistieken per cluster
- Vergelijk gemiddelde RFM-waarden van elke clusteroplossing
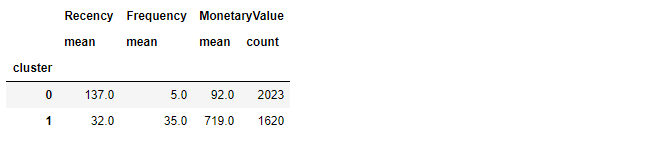
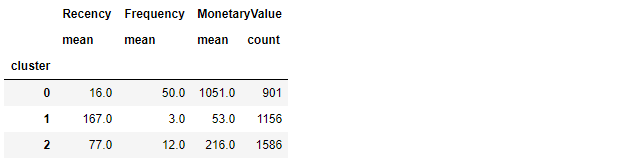
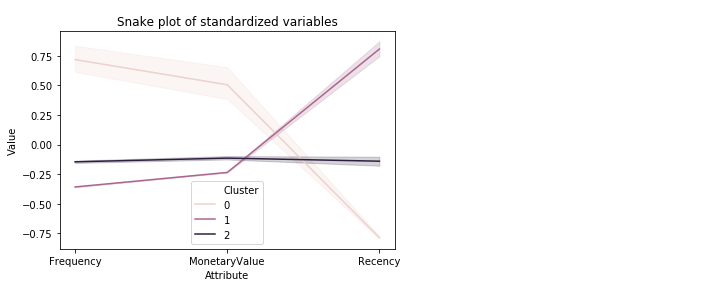
Een snake plot visualiseren
plt.title('Snake plot of standardized variables')
sns.lineplot(x="Attribute", y="Value", hue='Cluster', data=datamart_melt)
Heatmap: relatieve belangrijkheid
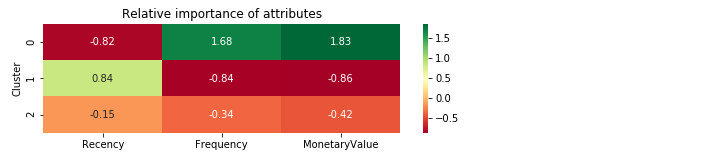
Recency Frequency MonetaryValue
Cluster
0 -0.82 1.68 1.83
1 0.84 -0.84 -0.86
2 -0.15 -0.34 -0.42

