Variabelen centreren en schalen
Klantsegmentatie in Python

Karolis Urbonas
Head of Data Science, Amazon
Een probleem vaststellen
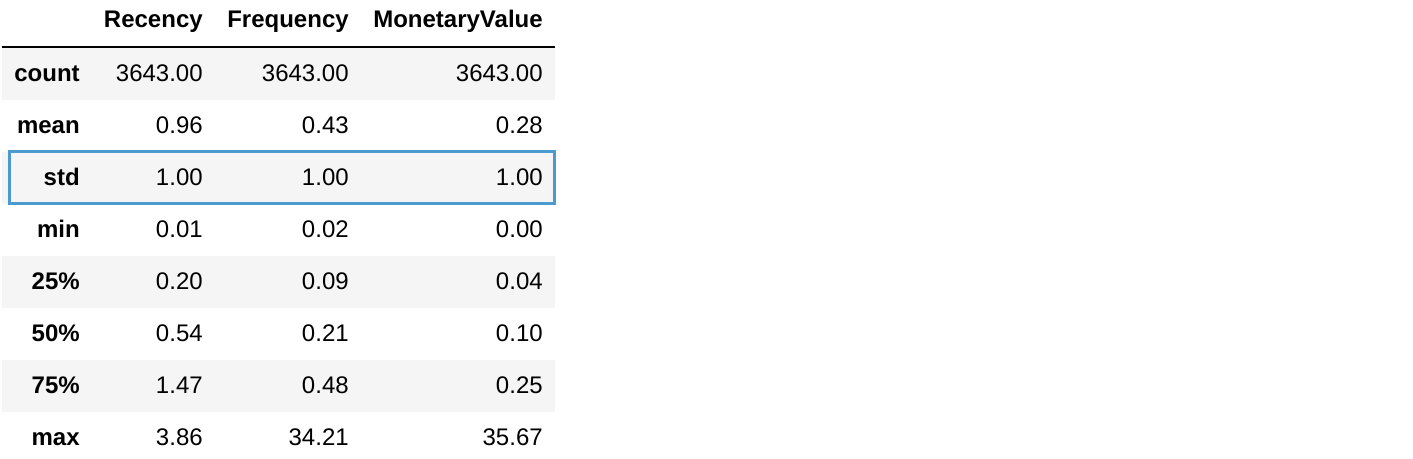
datamart_rfm.describe()
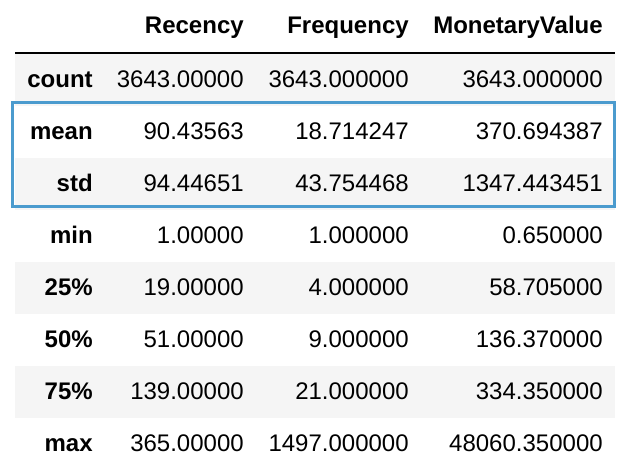
Variabelen met verschillend gemiddelde centreren
- K-means werkt goed op variabelen met hetzelfde gemiddelde
- Centreren: trek voor elke observatie het gemiddelde af
datamart_centered = datamart_rfm - datamart_rfm.mean()
datamart_centered.describe().round(2)
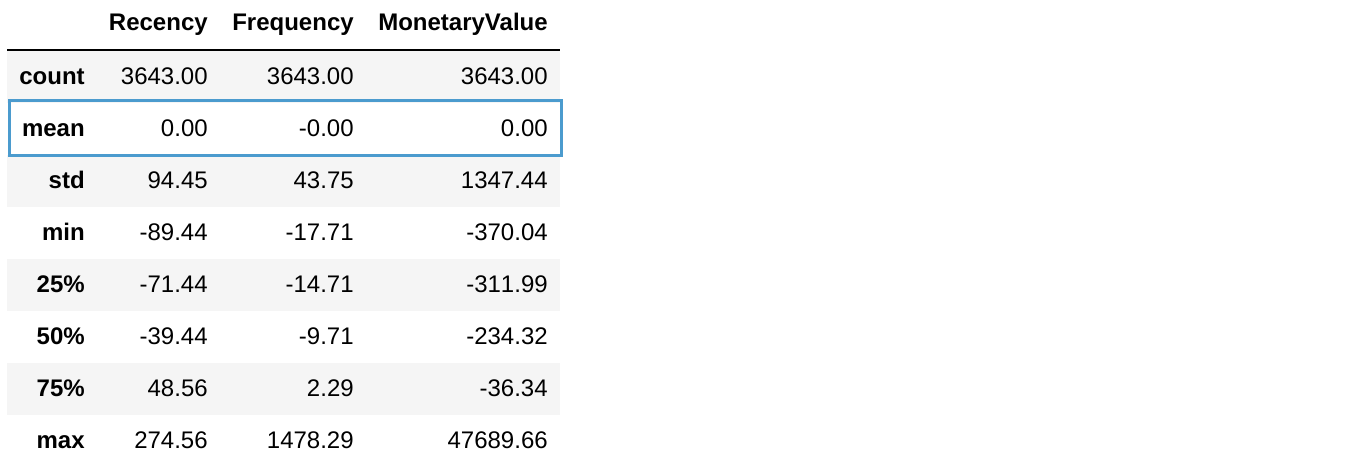
Variabelen met verschillende variantie schalen
- K-means werkt beter op variabelen met gelijke variantie/standaardafwijking
- Schalen: deel door de standaardafwijking per variabele
datamart_scaled = datamart_rfm / datamart_rfm.std()
datamart_scaled.describe().round(2)