Praktische implementatie van k-means-clustering
Klantsegmentatie in Python

Karolis Urbonas
Head of Data Science, Amazon
Gemiddelde RFM-waarden per cluster analyseren
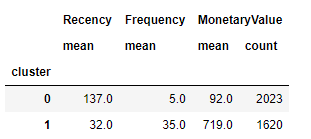
Het resultaat van een simpele 2-clusteroplossing:
Klantsegmentatie in Python
Karolis Urbonas
Head of Data Science, Amazon
Het resultaat van een simpele 2-clusteroplossing:

