Omgaan met missende data
Machine Learning-sollicitatievragen oefenen in Python

Lisa Stuart
Data Scientist
Cursusoverzicht
- Hoofdstuk 1: Preprocessing en visualisatie
- Missende data, uitschieters, normalisatie
- Hoofdstuk 2: Supervised learning
- Featureselectie, regularisatie, feature-engineering
- Hoofdstuk 3: Unsupervised learning
- Clustermethode kiezen, feature-extractie, dimensiereductie
- Hoofdstuk 4: Modelselectie en evaluatie
- Generalisatie en evaluatie, modelselectie
Machine-learningpipeline (ML)
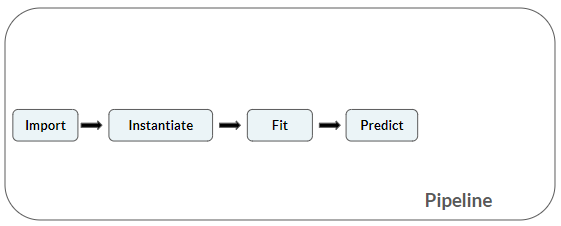
Onze ML-pipeline
Missende data
- Impact van technieken
- Missende waarden vinden
- Strategieën om te behandelen
Technieken
- Weglaten
- Rijen verwijderen -->
.dropna(axis=0) - Kolommen verwijderen -->
.dropna(axis=1)
- Rijen verwijderen -->
- Imputatie
- Vullen met nul -->
SimpleImputer(strategy='constant', fill_value=0) - Gemiddelde imputeren ->
SimpleImputer(strategy='mean') - Mediaan imputeren -->
SimpleImputer(strategy='median') - Modus imputeren -->
SimpleImputer(strategy='most_frequent') - Iteratieve imputatie -->
IterativeImputer()
- Vullen met nul -->
Waarom moeite doen?
- Verklein de kans op bias
- De meeste ML-algoritmes vereisen volledige data
Effecten van imputatie
- Hangt af van:
- Missende waarden
- Oorspronkelijke variantie
- Aanwezigheid van uitschieters
- Grootte en richting van scheefheid
- Weglaten --> Kan te veel verwijderen
- Nul --> Verlaagt resultaten (bias omlaag)
- Gemiddelde --> Gevoeliger voor uitschieters
- Mediaan --> Beter bij uitschieters
- Modus en iteratieve imputatie --> Probeer uit
| Functie | retourneert |
|---|---|
df.isna().sum() |
aantal missend |
df['feature'].mean() |
gemiddelde feature |
.shape |
rijen-, kolomaantallen |
df.columns |
kolomnamen |
.fillna(0) |
vult missend met 0 |
select_dtypes(include = [np.number] ) |
numerieke kolommen |
select_dtypes(include = ['object'] ) |
tekstkolommen |
.fit_transform(numeric_cols) |
fit en transformeer |
Effecten van missende waarden
Wat zijn de effecten van missende waarden in een Machine Learning (ML)-context? Kies de juiste uitspraak:
- Missende waarden zijn geen probleem, want de meeste
sklearn-algoritmes kunnen ermee omgaan. - Observaties of features met missende waarden verwijderen is meestal een goed idee.
- Missende data introduceert vaak bias en leidt tot misleidende resultaten, dus je kunt het niet negeren.
- Missende waarden met nul vullen zal resultaten omhoog vertekenen.
Effect van missende waarden: antwoord
Wat zijn de effecten van missende waarden in een ML-context? Het juiste antwoord is:
- Missende data introduceert vaak bias en leidt tot misleidende resultaten, dus je kunt het niet negeren. (Test welke vulling de variantie het minst beïnvloedt voor de beste aanpak.)
Effecten van missende waarden: onjuiste antwoorden
Wat zijn de effecten van missende waarden in een ML-context?
- Missende waarden zijn geen probleem... (De meeste
sklearn-algoritmes kunnen er niet mee overweg en geven een fout.) - Observaties of features met missende waarden verwijderen... (Tenzij je dataset groot is en het aandeel missend klein, krimpt verwijderen je data vaak te veel voor zinvolle ML.)
- Vullen met nul zal resultaten omhoog vertekenen. (Het omgekeerde: vullen met nul vertekent omlaag.)
Laten we oefenen!
Machine Learning-sollicitatievragen oefenen in Python

