Simulatietest: oplossing
Supply Chain Analytics in Python

Aaren Stubberfield
Supply Chain Analytics Mgr.
Let op
- Gebruik LP of IP niet voor problemen die lang duren om op te lossen

Overzichtsconcept
Algemeen concept:
- Voeg willekeurige ruis toe aan door jou gekozen kerninvoer
- Los het model herhaaldelijk op
- Bekijk de verdeling
Waarom proberen
Waarom:
- Invoer is vaak een schatting. Er is risico op onnauwkeurigheid.
- Eerdere gevoeligheidsanalyse bekeek maar één invoer tegelijk.
Context
Context - Glasbedrijf - Resourceplanning:
| Resource | Prod. A | Prod. B | Prod. C |
|---|---|---|---|
| Winst $US | $500 | $450 | $600 |
Restricties:
- Er zijn vraag-, productiecapaciteit- en magazijncapaciteitsrestricties
Risico's:
- Winstschattingen kunnen onnauwkeurig zijn
# Klasse initialiseren en variabelen definiëren
model = LpProblem("Max Glass Co. Profits", LpMaximize)
A = LpVariable('A', lowBound=0)
B = LpVariable('B', lowBound=0)
C = LpVariable('C', lowBound=0)
# Doelfunctie definiëren
model += 500 * A + 450 * B + 600 * C
# Restricties definiëren en oplossen
model += 6 * A + 5 * B + 8 * C <= 60
model += 10.5 * A + 20 * B + 10 * C <= 150
model += A <= 8
model.solve()
Codevoorbeeld - stap 2
a, b, c = normalvariate(0,25),
normalvariate(0,25),
normalvariate(0,25)
# Doelfunctie definiëren
model += (500+a)*A + (450+b)*B + (600+c)*C
# Klasse initialiseren en variabelen definiëren
model = LpProblem("Max Glass Co. Profits",
LpMaximize)
A = LpVariable('A', lowBound=0)
B = LpVariable('B', lowBound=0)
C = LpVariable('C', lowBound=0)
a, b, c = normalvariate(0,25),
normalvariate(0,25),
normalvariate(0,25)
# Doelfunctie definiëren
model += (500+a)*A + (450+b)*B + (600+c)*C
# Restricties definiëren en oplossen
model += 6 * A + 5 * B + 8 * C <= 60
model += 10.5 * A + 20 * B + 10 * C <= 150
model += A <= 8
model.solve()
def run_pulp_model():
# Klasse initialiseren
model = LpProblem("Max Glass Co. Profits", LpMaximize)
A = LpVariable('A', lowBound=0)
B = LpVariable('B', lowBound=0)
C = LpVariable('C', lowBound=0)
a, b, c = normalvariate(0,25), normalvariate(0,25), normalvariate(0,25)
# Doelfunctie definiëren
model += (500+a)*A + (450+b)*B + (600+c)*C
# Restricties definiëren en oplossen
model += 6 * A + 5 * B + 8 * C <= 60
model += 10.5 * A + 20 * B + 10 * C <= 150
model += A <= 8
model.solve()
o = {'A':A.varValue, 'B':B.varValue, 'C':C.varValue, 'Obj':value(model.objective)}
return(o)
Codevoorbeeld - stap 4
def run_pulp_model():
# Klasse initialiseren
model = LpProblem("Max Glass Co. Profits",
LpMaximize)
A = LpVariable('A', lowBound=0)
B = LpVariable('B', lowBound=0)
C = LpVariable('C', lowBound=0)
a, b, c = normalvariate(0,25),
normalvariate(0,25),
normalvariate(0,25)
# Doelfunctie definiëren
model += (500+a)*A + (450+b)*B +
(600+c)*C
# Restricties definiëren en oplossen
model += 6 * A + 5 * B + 8 * C <= 60
model += 10.5 * A + 20 * B + 10 * C <= 150
model += A <= 8
model.solve()
o = {'A':A.varValue, 'B':B.varValue,
'C':C.varValue,
'Obj':value(model.objective)}
return(o)
for i in range(100):
output.append(run_pulp_model())
df = pd.DataFrame(output)
Codevoorbeeld - stap 5
print(df['A'].value_counts())
print(df['B'].value_counts())
print(df['C'].value_counts())
Output: (resultaten kunnen verschillen)
6.666667 73
0.000000 14
8.000000 13
Name: A, dtype: int64
4.000000 73
5.454546 14
2.400000 13
Name: B, dtype: int64
0.000000 86
4.090909 14
Name: C, dtype: int64
Visualiseren als histogram
Product A:
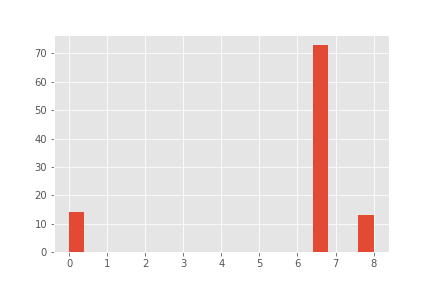
Product B:
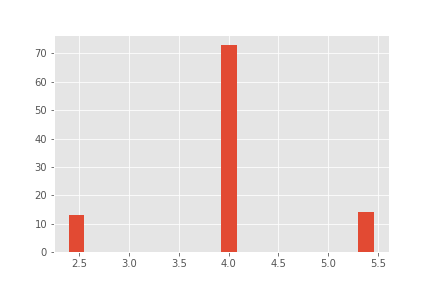
Product C:
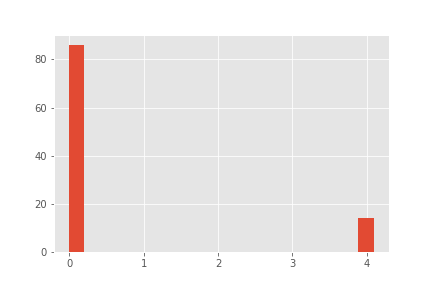
Objectiefwaarden:
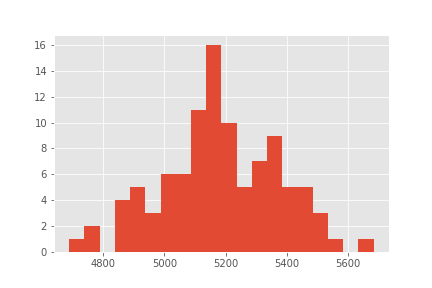
Samenvatting
- Niet gebruiken voor problemen die lang duren om op te lossen
Voordelen
- Zie hoe optimale uitkomsten veranderen als invoer verandert
Stappen
- Begin met standaard PuLP-modelcode
- Voeg ruis toe aan kerninvoer met Python's
normalvariate - Verpak PuLP-code in een functie die de output retourneert
- Maak een lus die de functie aanroept en resultaten in een DataFrame opslaat
- Visualiseer de resultaten-DataFrame
Laten we oefenen!
Supply Chain Analytics in Python

