Prestatiemetrics voor regressiebomen
Machine Learning met boomgebaseerde modellen in R

Sandro Raabe
Data Scientist
Veelgebruikte metrics voor regressie
- Gemiddelde Absolute Fout (MAE)
- Wortel Gemiddelde Kwadratische Fout (RMSE)
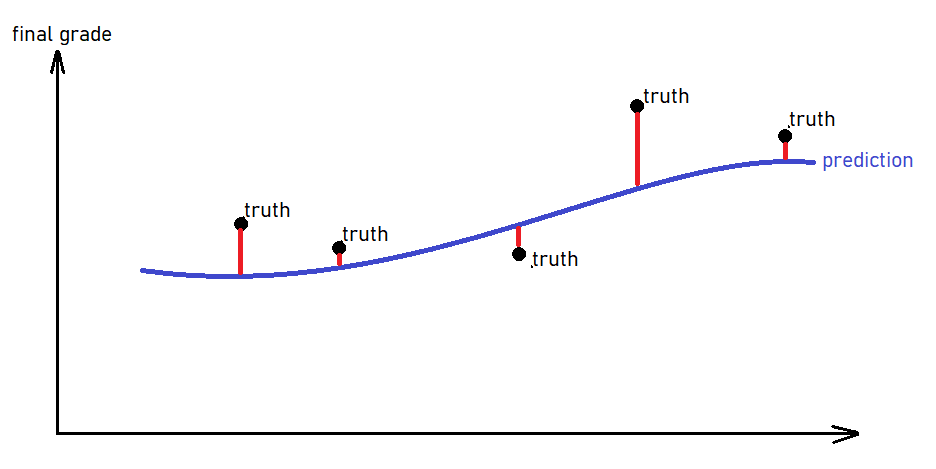
MAE: intuïtie
Machine Learning met boomgebaseerde modellen in R
Sandro Raabe
Data Scientist

