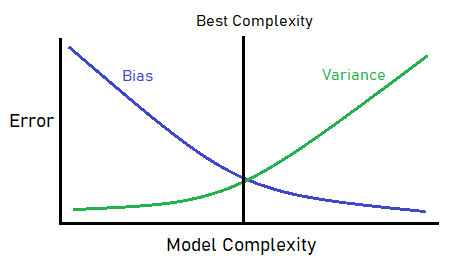
Bias-variantie-afweging
Machine Learning met boomgebaseerde modellen in R

Sandro Raabe
Data Scientist
Hyperparameters


Complex model - overfitting - hoge variantie
Voorspellingen op trainingsset: goed gedaan!
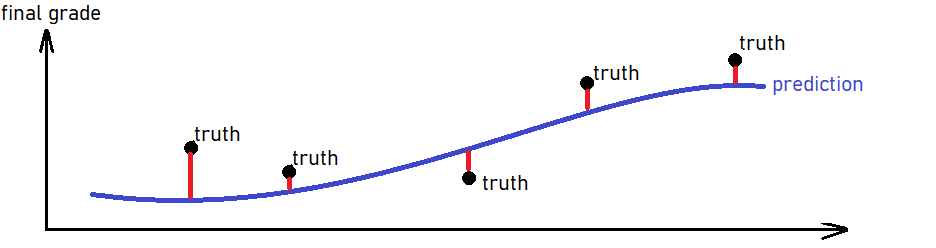
mae(train_results,
estimate = .pred,
truth = final_grade)
# A tibble: 1 x 3
.metric .estimate
1 mae 0.204
Voorspellingen op testset: ver naast!
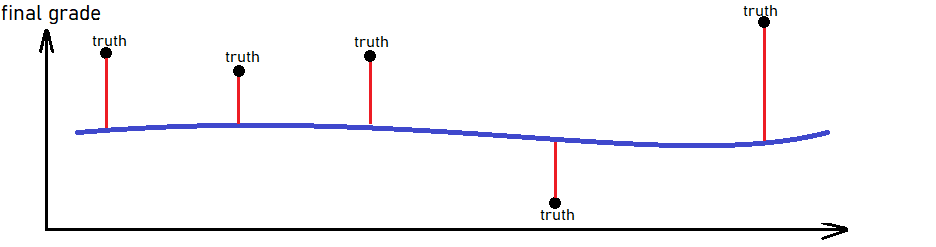
mae(test_results,
estimate = .pred,
truth = final_grade)
# A tibble: 1 x 3
.metric .estimate
1 mae 0.947
De bias-variantie-afweging