Datavoorbereiding voor segmentatie
Machine Learning voor marketing in Python

Karolis Urbonas
Head of Analytics & Science, Amazon
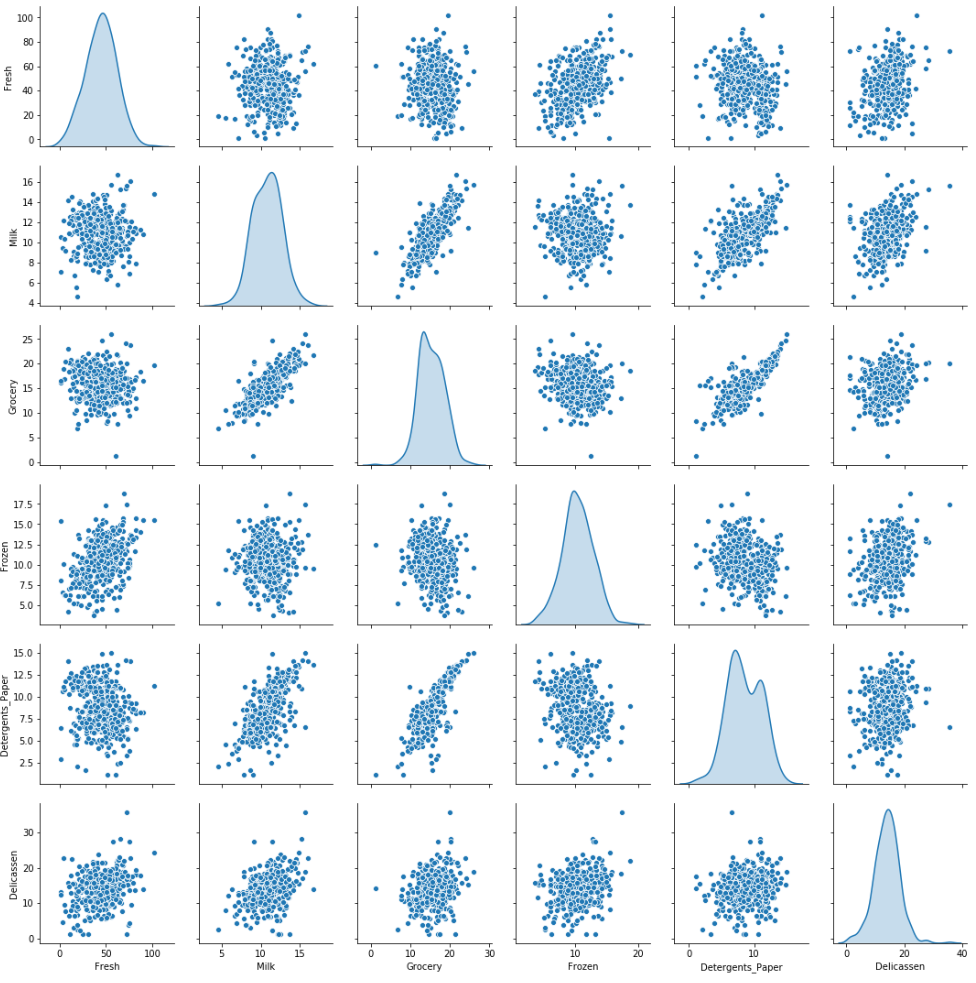
Verken log-getransformeerde data
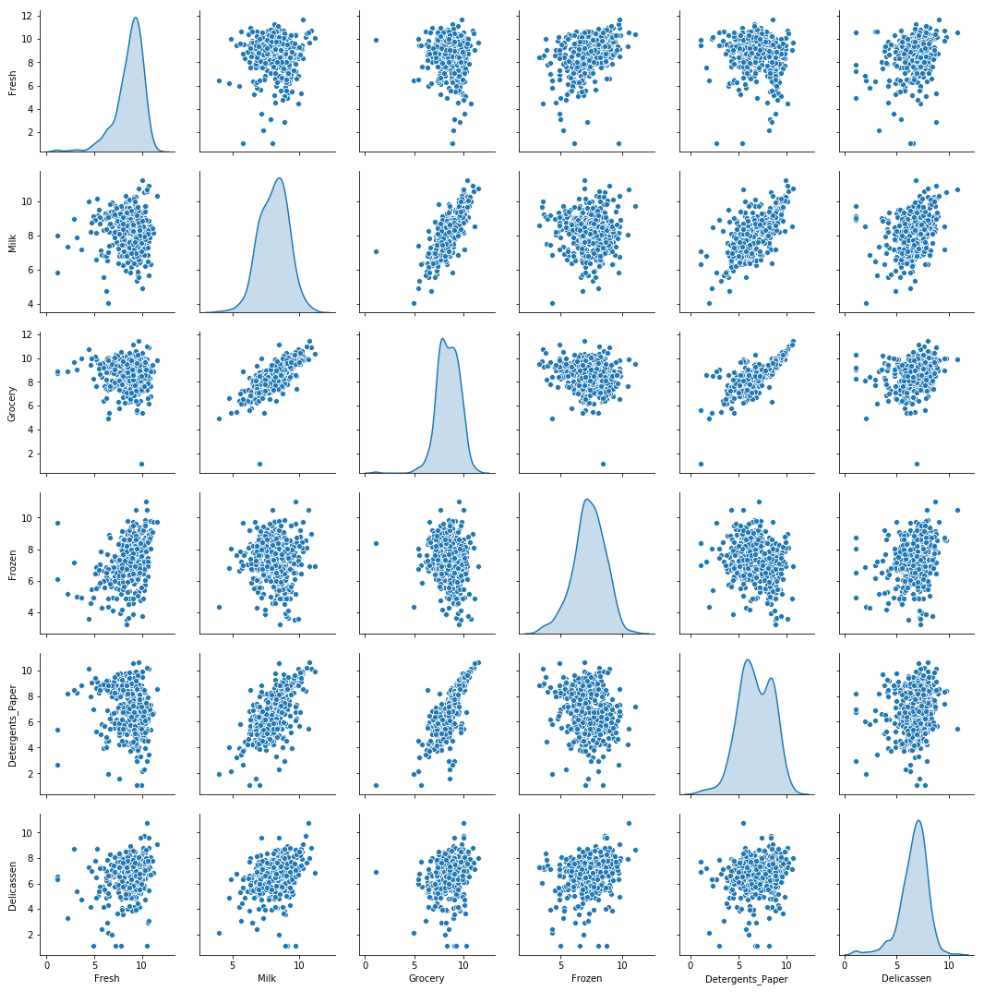
Verken Box-Cox-getransformeerde data
Machine Learning voor marketing in Python
Karolis Urbonas
Head of Analytics & Science, Amazon

