Tekst opschonen en preprocessen
Text mining met bag-of-words in R

Ted Kwartler
Instructor
Veelgebruikte preprocessing-functies
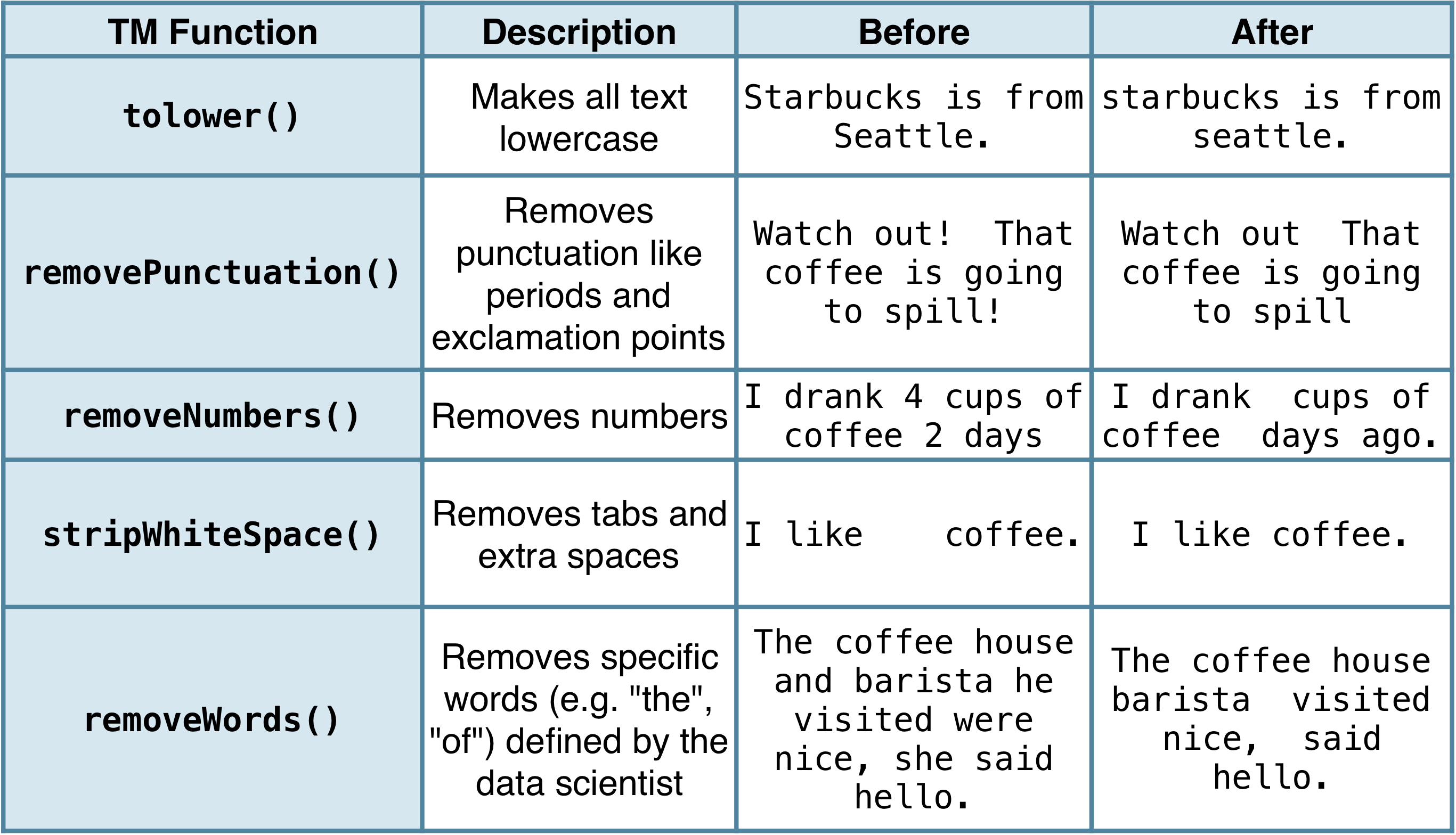
Preprocessing in de praktijk
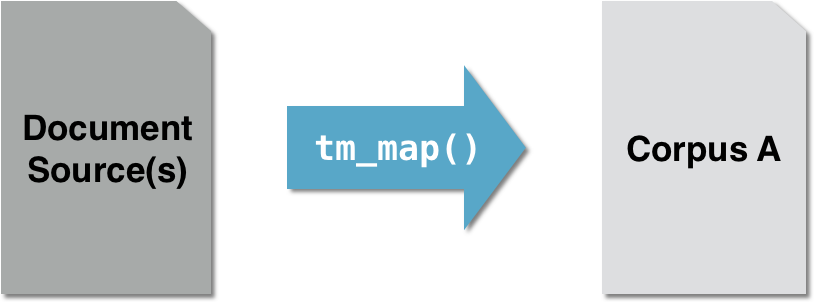
# Make a vector source: coffee_source coffee_source <- VectorSource(coffee_tweets)# Make a volatile corpus: coffee_corpus coffee_corpus <- VCorpus(coffee_source)# Apply various preprocessing functions tm_map(coffee_corpus, removeNumbers) tm_map(coffee_corpus, removePunctuation)tm_map(coffee_corpus, content_transformer(replace_abbreviation))

