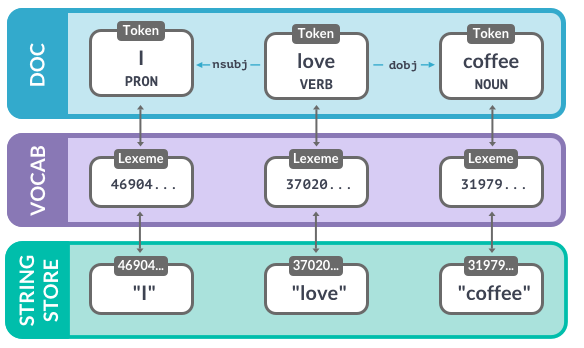
Gedeelde vocab en StringStore (1)
Vocab: slaat data op die gedeeld wordt door meerdere documenten- Om geheugen te sparen, codeert spaCy alle strings als hashwaarden
- Strings worden maar één keer opgeslagen in de
StringStore via nlp.vocab.strings
- StringStore: tweerichtings-lookup-tabel
coffee_hash = nlp.vocab.strings['coffee']
coffee_string = nlp.vocab.strings[coffee_hash]
- Hashes zijn niet omkeerbaar – daarom heb je de gedeelde vocab nodig
# Geeft een error als we de string nog niet eerder hebben gezien
string = nlp.vocab.strings[3197928453018144401]