# Create an nlp object
from spacy.lang.en import English
nlp = English()
# Import the Doc class
from spacy.tokens import Doc
# The words and spaces to create the doc from
words = ['Hello', 'world', '!']
spaces = [True, False, False]
# Create a doc manually
doc = Doc(nlp.vocab, words=words, spaces=spaces)
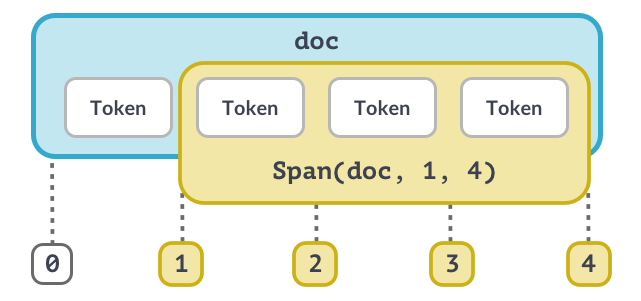
Het Span-object (1)
Het Span-object (2)
# Import the Doc and Span classes
from spacy.tokens import Doc, Span
# The words and spaces to create the doc from
words = ['Hello', 'world', '!']
spaces = [True, False, False]
# Create a doc manually
doc = Doc(nlp.vocab, words=words, spaces=spaces)
# Create a span manually
span = Span(doc, 0, 2)
# Create a span with a label
span_with_label = Span(doc, 0, 2, label="GREETING")
# Add span to the doc.ents
doc.ents = [span_with_label]
Best practices
Doc en Span zijn krachtig en bewaren verwijzingen en relaties van woorden en zinnen
Zet resultaten zo laat mogelijk om naar strings
Gebruik tokenattributen als die bestaan – bijv. token.i voor de tokenindex