Waarom bestaande features transformeren?
Feature engineering in R

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
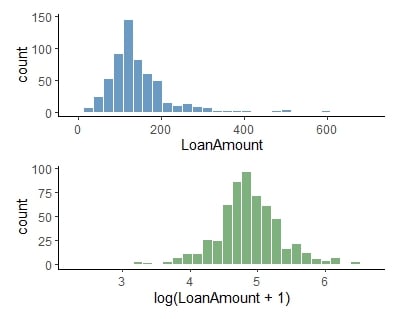
Logtransformatie
log-getransformeerde leenbedragen
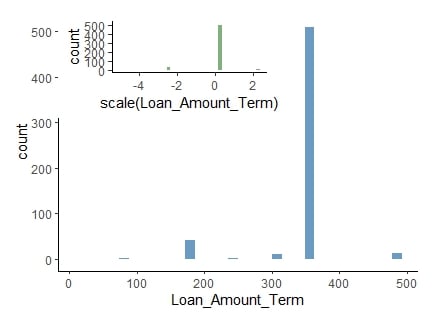
Normalisatie
Bijv. leenlooptijden variëren sterk
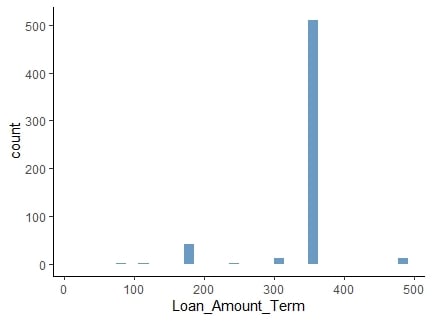
Normalisatie
Genormaliseerde waarden behouden de verdeling, maar bevatten variatie.