Alles samenbrengen
Feature engineering in R

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
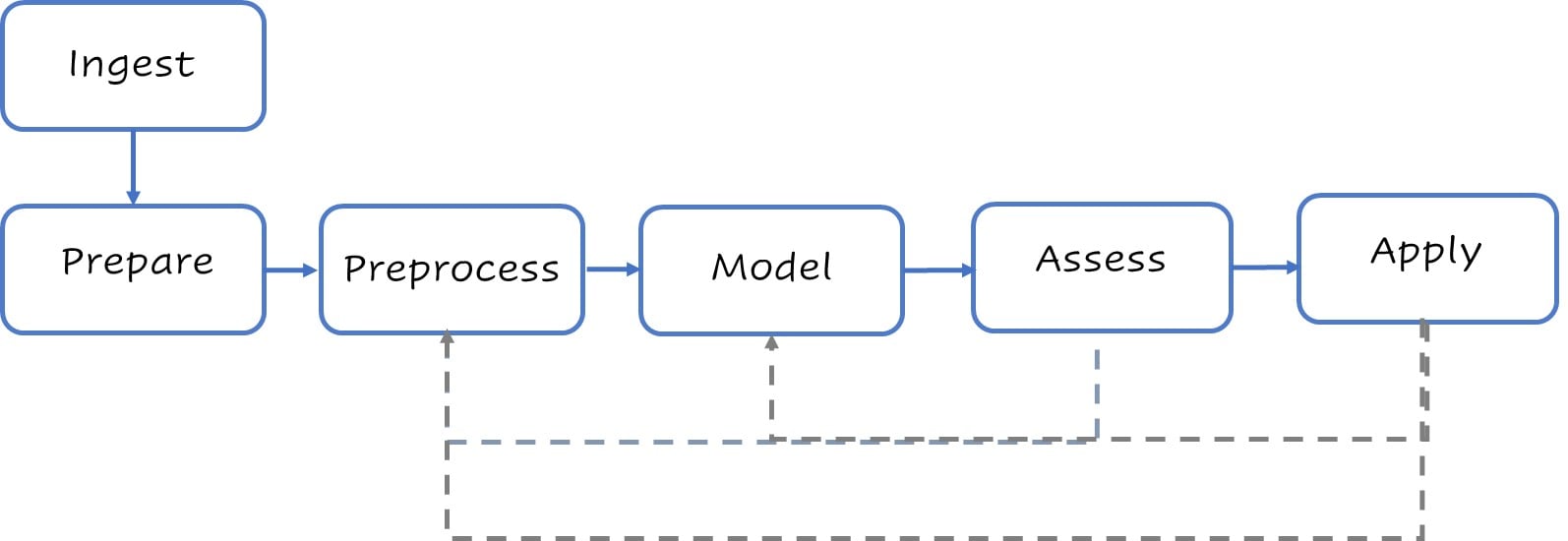
Een gestileerde modelleringflow
Typische stappen op hoog niveau voor modelleren.
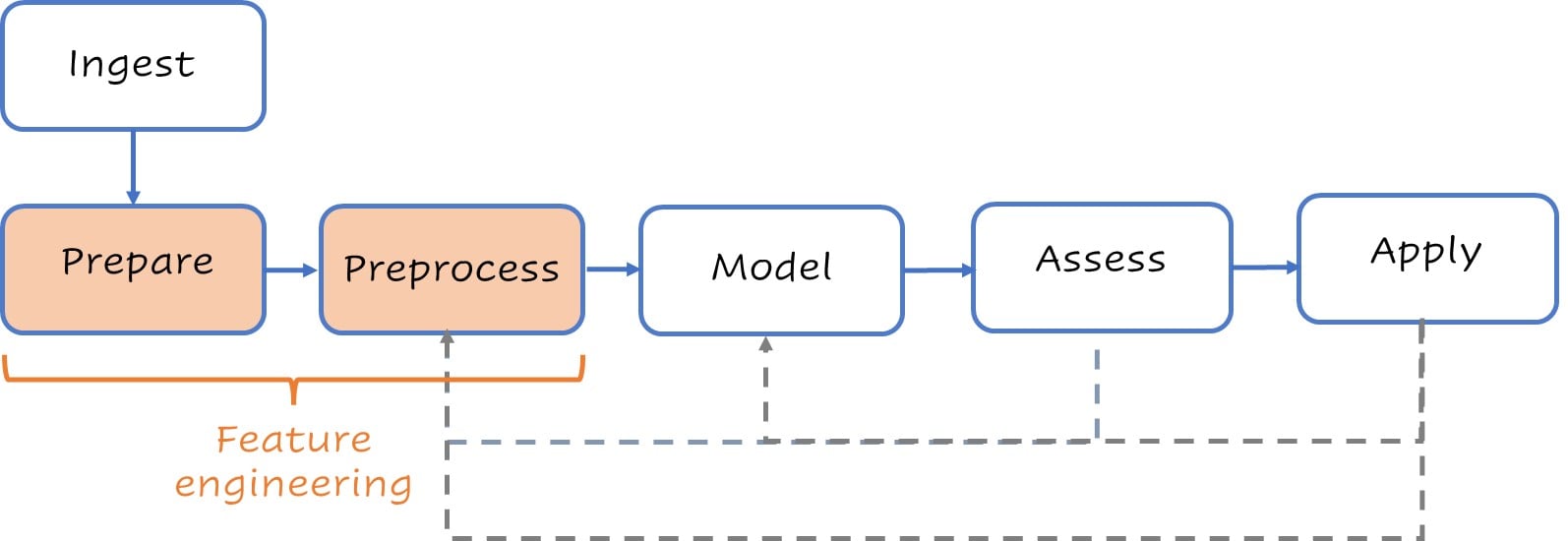
Een gestileerde modelleringflow
Typische stappen op hoog niveau voor modelleren.
Beoordelen
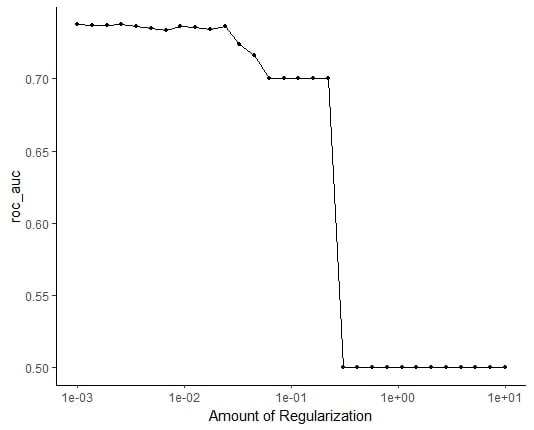
ROC_AUC vs. regularisatie