Het aantal features van het model verminderen
Feature engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
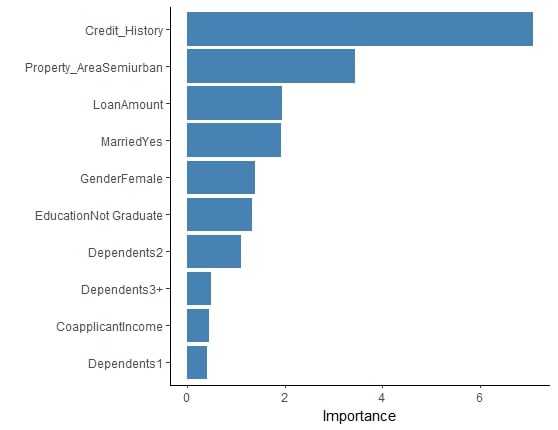
Data filteren met variabelenbelang
vip van variabelen plotten
lr_fit_full %>%
extract_fit_parsnip() %>%
vip(aesthetics = list(fill = "steelblue"))
Belang van variabelen