Dimensies verminderen
Feature engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
Kenmerken met nulvariantie
Principal Component Analysis (PCA)
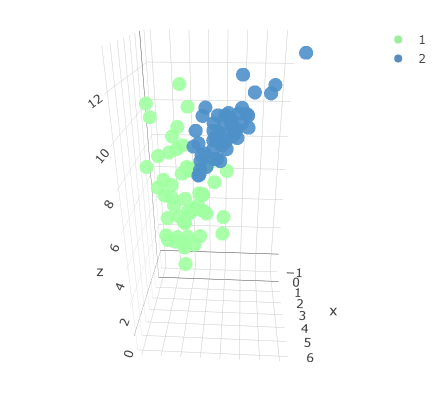
Oorspronkelijke driedimensionale dataset met twee klassen.
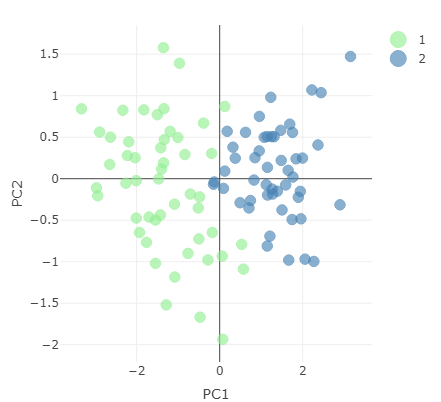
Gereduceerde dataset met de eerste twee hoofdcomponenten.
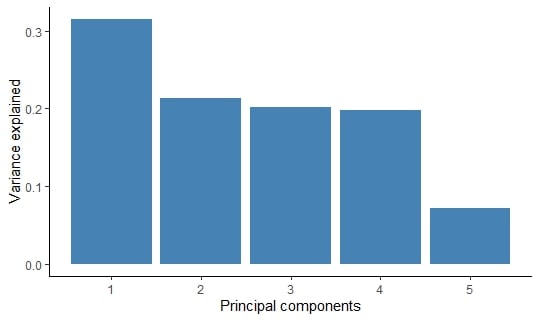
Verklaarde variantie visualiseren
Verklaarde variantie per hoofdcomponent.