De informatie-inhoud van ruwe data vergroten
Feature engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
Werken met ruwe data
Een typisch dataset met missende waarden
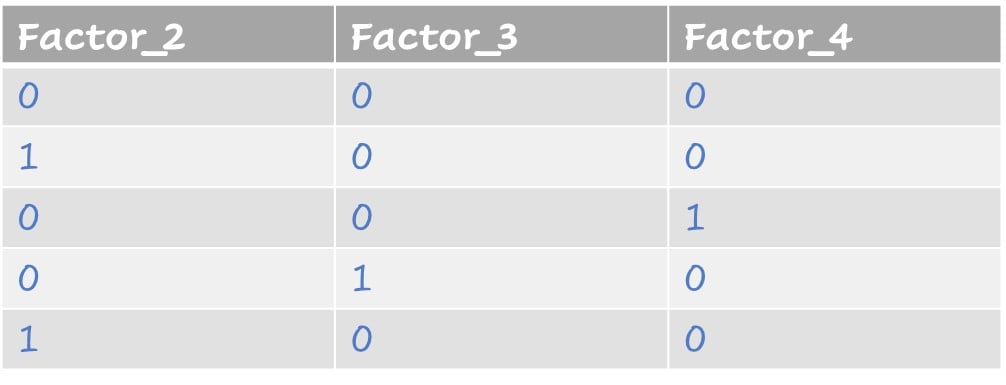
Waarden als factoren

Werken met ruwe data
Dataset met geïmputeerde waarden
Factoren weergegeven als dummyvariabelen
Missende waarden
We kunnen missende waarden in loans visueel herkennen met vis_miss(loans) uit het pakket naniar.
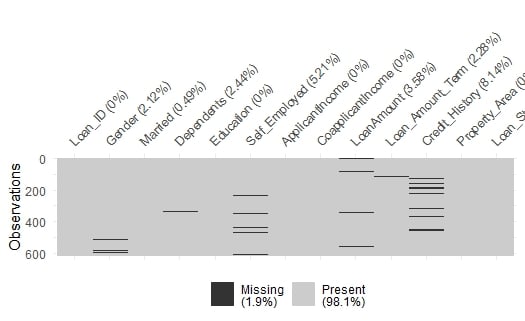
Missende waarden
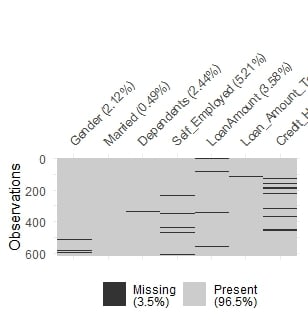
Een nadere blik op missende waarden
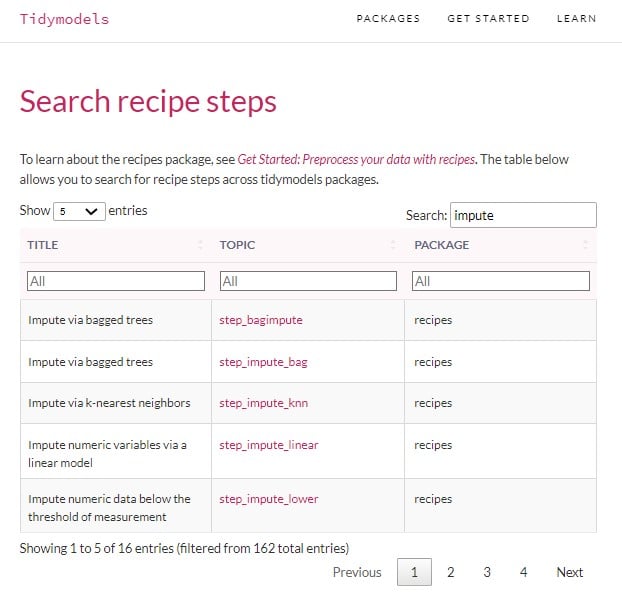
De juiste recipe-stap vinden
Andere imputatiemethoden en alle recipe-stappen vind je in de tidymodels-documentatie op www.tidymodels.org/find/recipes
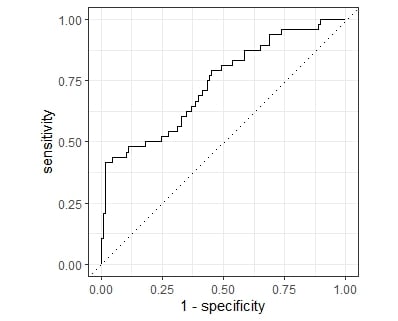
Ons model fitten en beoordelen
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.738
2 accuracy binary 0.792