Categorische data coderen met supervised learning
Feature engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
Introductie van supervised encoding
Supervised encoding gebruikt de uitkomstwaarden om numerieke features af te leiden uit nominale voorspellers.
Introductie van supervised encoding
Supervised encoding gebruikt de uitkomstwaarden om numerieke features af te leiden uit nominale voorspellers.
Enkele supervised-encodingfuncties in het embed -pakket
| Function | Definition |
|---|---|
| step_lencode_glm() | Gebruikt likelihood-encodings om een nominale voorspeller om te zetten naar één score-set uit een generalized linear model. |
| step_lencode_bayes() | Past Bayesiaanse likelihood-encodings toe om een nominale voorspeller om te zetten naar één score-set uit een generalized linear model geschat met Bayesiaanse analyse. |
| step_lencode_mixed() | Zet nominale voorspellers om naar één score-set uit een generalized linear mixed model. |
Succes van subsidieaanvragen voorspellen
We willen het succes van subsidieaanvragen voorspellen op basis van alleen de sponsorcode.
lr_model <- logistic_reg() # declare model
lr_recipe_glm <- # Set recipe glm
recipe(class ~ sponsor_code,
data = grants_train) %>%
step_lencode_glm(sponsor_code,
# Declare outcome variable
outcome = vars(class))
lr_workflow_glm <- # Create Workflow
workflow() %>%
add_model(lr_model) %>%
add_recipe(lr_recipe_glm)
Workflowoverzicht
lr_workflow_glm
-- Workflow ------------------------------------
Preprocessor: Recipe
Model: logistic_reg()
-- Preprocessor --------------------------------
1 Recipe Step
- step_lencode_glm()
-- Model --------------------------------------
Logistic Regression Model Specification (classification)
Computational engine: glm
Fitten, aanvullen en beoordelen
We fitten en evalueren ons model
lr_fit_glm <- # Fit
lr_workflow_glm %>%
fit(grants_train)
lr_aug_glm <- # Augment
lr_fit_glm %>%
augment(grants_test)
glm_model <- lr_aug_glm %>% # Assess
class_evaluate(truth = class,
estimate = .pred_class,
.pred_successful)
Prestatie-resultaten staan in glm_model
glm_model
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.728
2 roc_auc binary 0.684
Modellen samenvoegen
We bouwen bayes_model en mixed_model om de prestaties van de bijbehorende stappen te vergelijken.
# Define model names
model <- c("glm", "glm",
"bayes","bayes",
"mixed", "mixed")
# Bind models in a tibble
models <-
bind_rows(glm_model,
bayes_model,
mixed_model)%>%
add_column(model = model)%>%
select(-.estimator) %>%
spread(model,.estimate)
Een handige prestatietabel
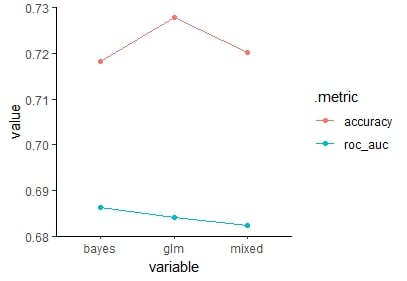
models
# A tibble: 2 × 4
.metric bayes glm mixed
<chr> <dbl> <dbl> <dbl>
1 accuracy 0.718 0.728 0.720
2 roc_auc 0.686 0.684 0.682
Resultaten visualiseren
Visualiseer resultaten in een parallelcoördinaatgrafiek uit het GGally-pakket.
# Libraries
library(GGally)
# Parallel coordinates chart
ggparcoord(models,
columns = 2:4,
groupColumn = 1,
scale="globalminmax",
showPoints = TRUE)
Parallelcoördinaatgrafiek van accuracy en roc_auc voor alle modellen.
Laten we oefenen!
Feature engineering in R

