Segregatie meten: de dissimilariteitsindex
US Census-gegevens analyseren in Python

Lee Hachadoorian
Asst. Professor of Instruction, Temple University
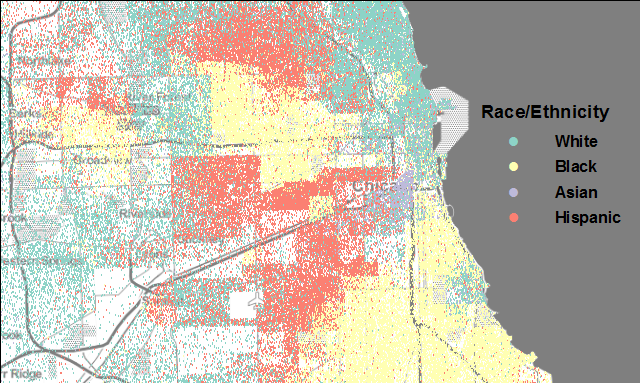
Wat is segregatie?
Formule dissimilariteitsindex
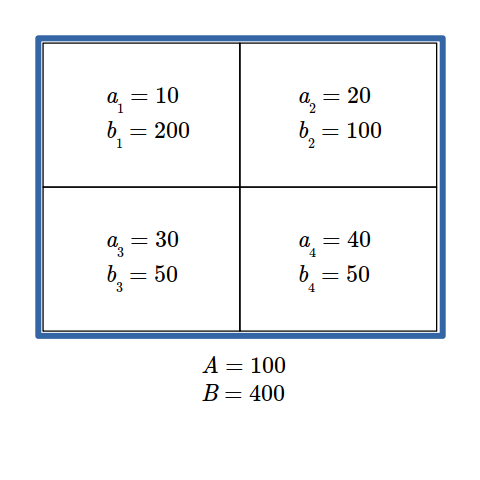
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex
Formule dissimilariteitsindex

