Werkgelegenheid en beroepsbevolking
US Census-gegevens analyseren in Python

Lee Hachadoorian
Asst. Professor of Instruction, Temple University
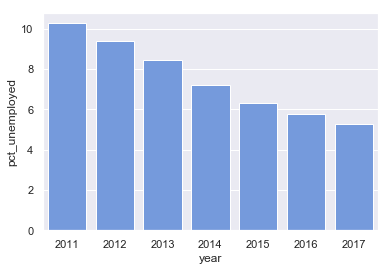
Een staafdiagram maken
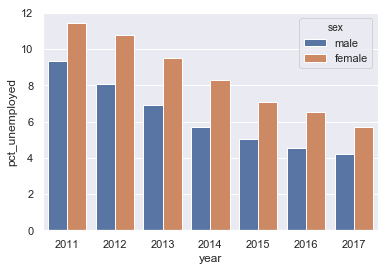
Gegroepeerd staafdiagram maken
sns.barplot(x = "year", y = "pct_unemployed", hue = "sex",
data = tidy_unemp)