Pipelines voor supervised learning
Machine Learning-workflows ontwerpen in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
Gelabelde data
- Featurevariabelen (afkorting:
X) - Labels of klasse (afkorting:
y)
credit_scoring.head(4)
checking_status duration ... foreign_worker class
0 '<0' 6 ... yes good
1 '0<=X<200' 48 ... yes bad
2 'no checking' 12 ... yes good
3 '<0' 42 ... yes good
Feature engineering
- De meeste classifiers verwachten numerieke features
- Stringkolommen moeten naar nummers
Preprocess met LabelEncoder uit sklearn.preprocessing:
le = LabelEncoder()
le.fit_transform(credit_scoring['checking_status'])[:4]
array([1, 0, 3, 1])
Model fitten
.fit(features, labels).predict(features)
features, labels = credit_scoring.drop('class', 1), credit_scoring['class']model_nb = GaussianNB() model_nb.fit(features, labels) model_nb.predict(features.head(5))
['good' 'bad' 'good' 'bad' 'good']
60% nauwkeurigheid op de eerste 5 voorbeelden.
Modelselectie
.fit()optimaliseert de parameters van het model- En andere modellen?
AdaBoostClassifier presteert beter dan GaussianNB op de eerste vijf punten:
model_ab = AdaBoostClassifier()
model_ab.fit(features, labels)
model_ab.predict(features.head(5))
numpy.array(labels[0:5])
['good' 'bad' 'good' 'good' 'bad']
['good' 'bad' 'good' 'good' 'bad']
Prestatiebeoordeling
Grotere steekproeven → betere schattingen van nauwkeurigheid:
from sklearn.metrics import accuracy_score
accuracy_score(labels, model_nb.predict(features)) # naive bayes
0.706
accuracy_score(labels, model_ab.predict(features)) # adaboost
0.802
Wat is hier mis mee?
Overfitting en data splitsen
Overfitting: een model presteert altijd beter op z’n trainingsdata dan op nieuwe data.
Train op X_train, y_train, beoordeel nauwkeurigheid op X_test, y_test:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)GaussianNB().fit(X_train, y_train).predict(X_test)
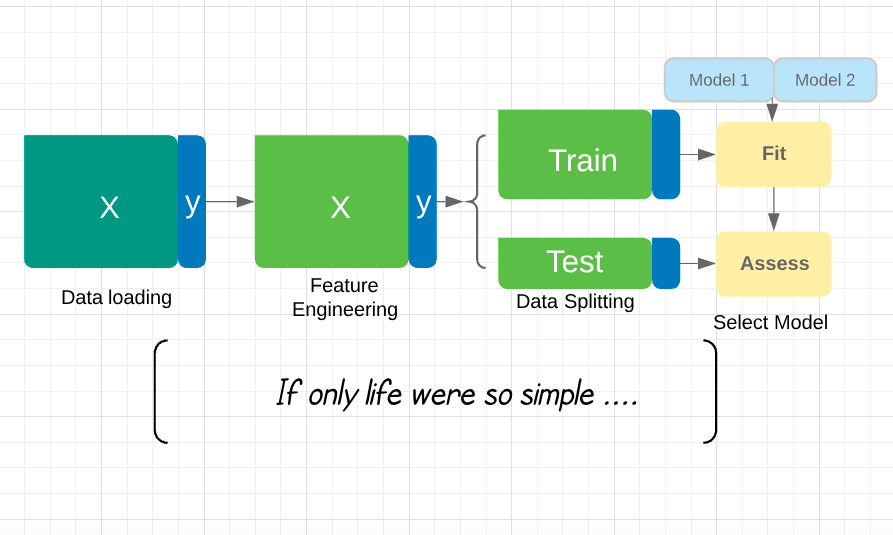
Waar gaat deze cursus over?
- Schaalbaar je pipeline tunen.
- Zorgen dat voorspellingen relevant zijn met domeinexperts.
- Borgen dat je model goed blijft presteren in de tijd.
- Modellen fitten met te weinig labels.
Had je de hypotheekcrisis kunnen voorkomen?
Machine Learning-workflows ontwerpen in Python

