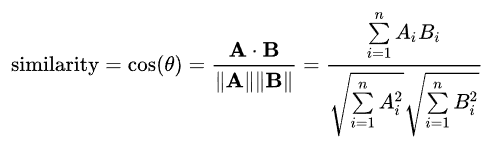Cosinusovereenkomst
Introductie tot Natural Language Processing in R

Kasey Jones
Research Data Scientist
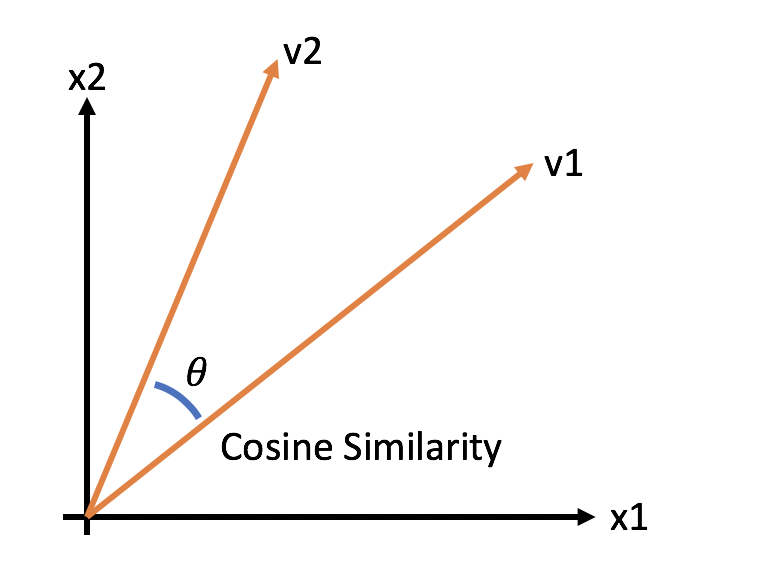
Cosinusovereenkomst
- een maat voor overeenkomst tussen twee vectoren
- bepaald door de hoek tussen de twee vectoren
1 https://en.wikipedia.org/wiki/Cosine_similarity
Formule voor cosinusovereenkomst
- overeenkomst wordt berekend als het inwendig product van twee vectoren