De voordelen meten
Parallel programmeren in R

Nabeel Imam
Data Scientist
De olifant in de kamer
sqroots <- sqrt(numbers)

Klassieke versie
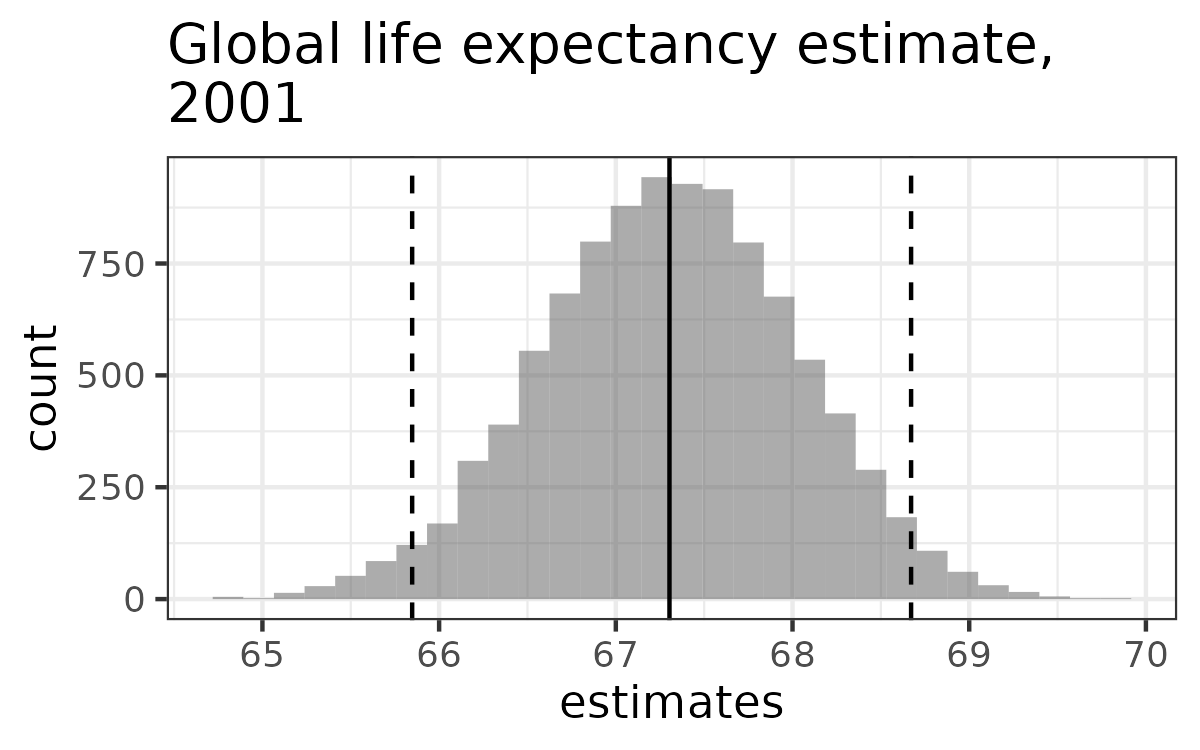
- Betrouwbaarheidsinterval via kwantielen:
quantile(estimates, c(0.025, 0.975))
Parallel programmeren in R
Nabeel Imam
Data Scientist
sqroots <- sqrt(numbers)
quantile(estimates, c(0.025, 0.975))
