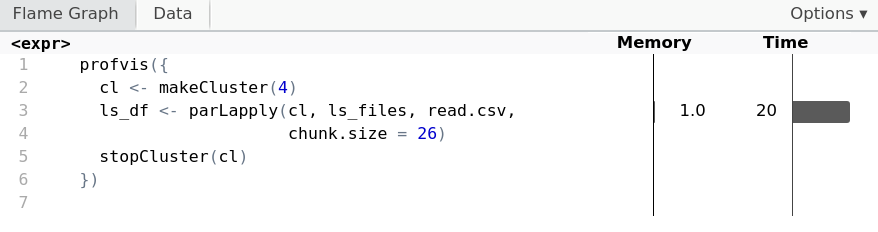
Geheugen monitoren en beheren
Parallel programmeren in R

Nabeel Imam
Data Scientist
De rij en de ruimte

De parallelle flow

De parallelle flow

Profilen met twee workers

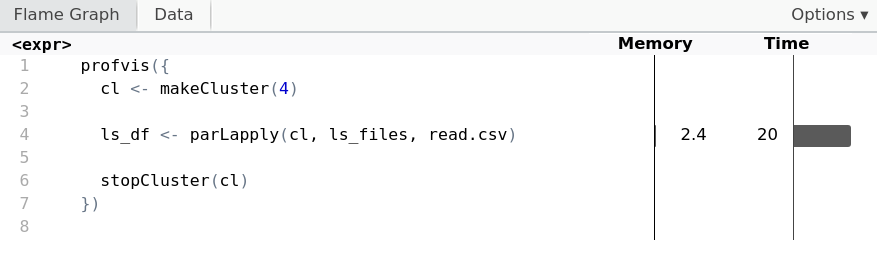
Profilen met vier workers
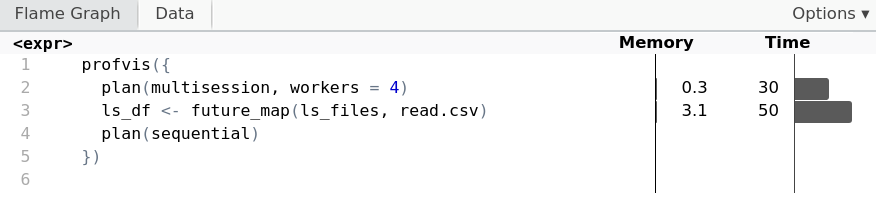
Achter de schermen
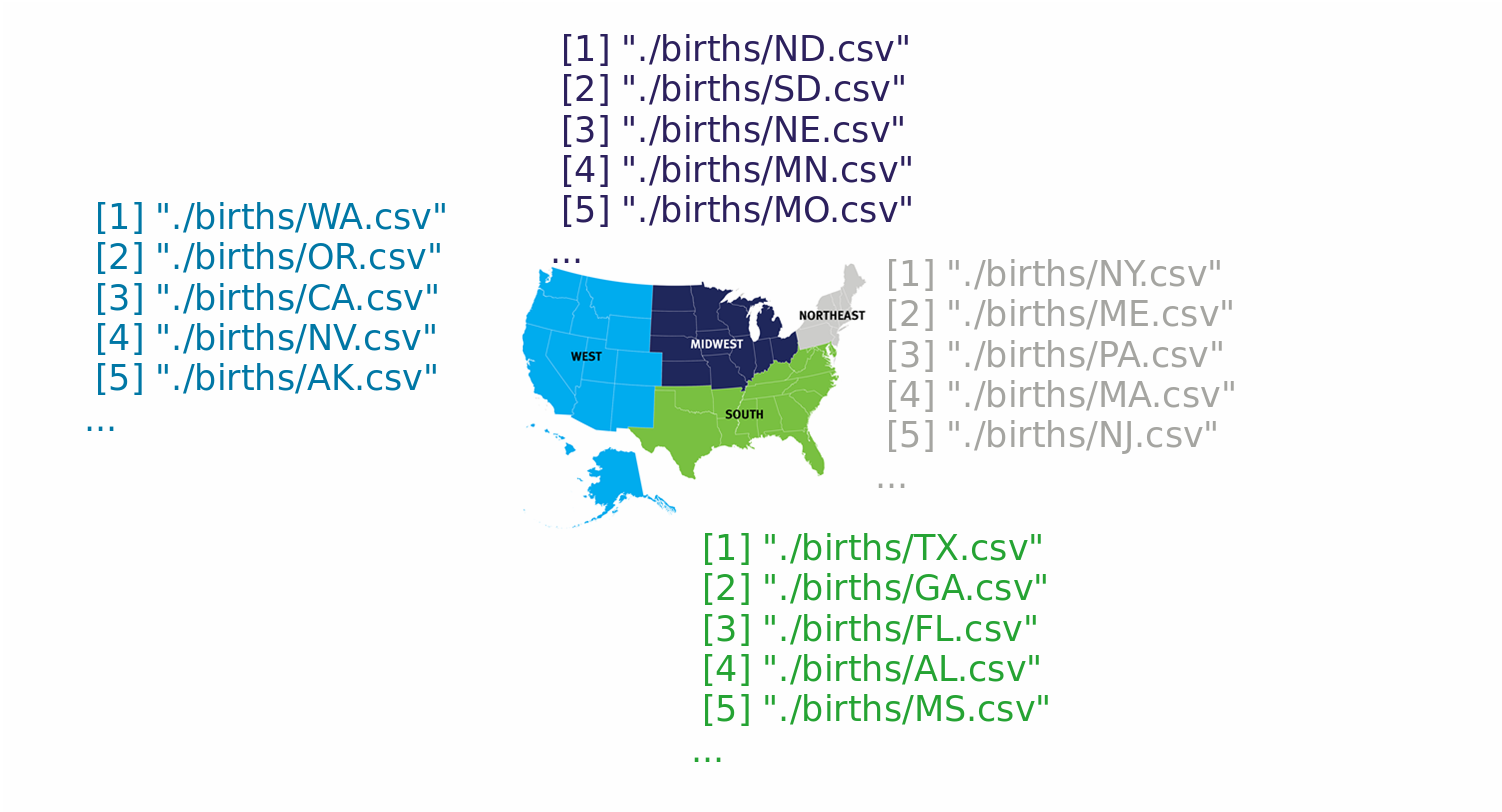
Geheugen beheren met chunking
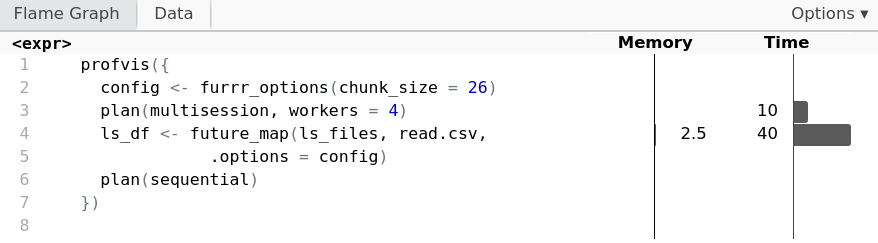
Chunking met parallel
Chunking met parallel
cl <- makeCluster(4) ls_df <- parLapply(cl, ls_files, read.csv,chunk.size = 26)stopCluster(cl)