Clustering en clustermodellen
Discrete Event Simulation in Python

Diogo Costa (PhD, MSc)
Adjunct Professor, University of Saskatchewan, Canada & CEO of ImpactBLUE-Scientific
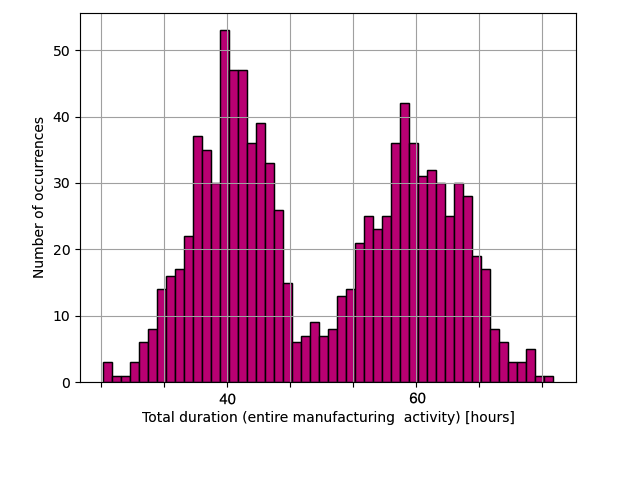
Histogrammen van modelresultaten
Gebruik: Maak een histogram van dataset data met 50 bins
plt.hist(data, bins=50)
Clusteranalyse en toepassing op modellen
- Toepassingen
- Patronen herkennen (bv. modelresultaten)
- Beeldanalyse

- Datacompressie
- Computergraphics
Machine learning

In discrete-eventmodellen
- Herken patronen in modeluitvoer
- Meer bruikbare inzichten
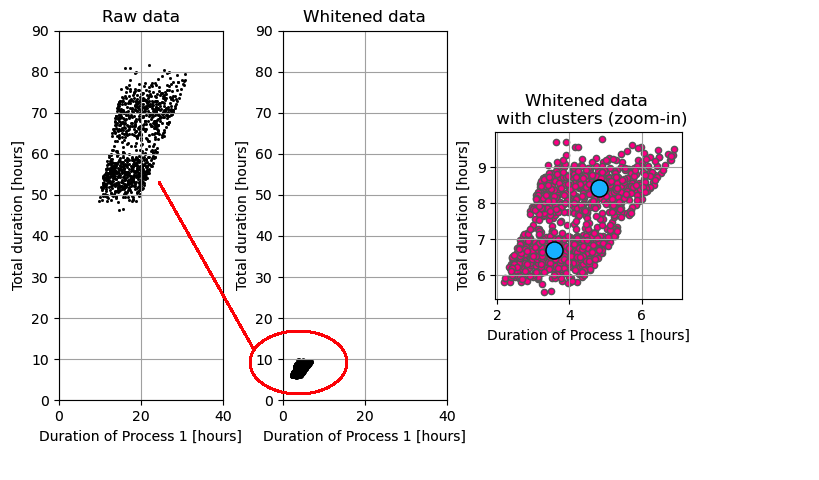
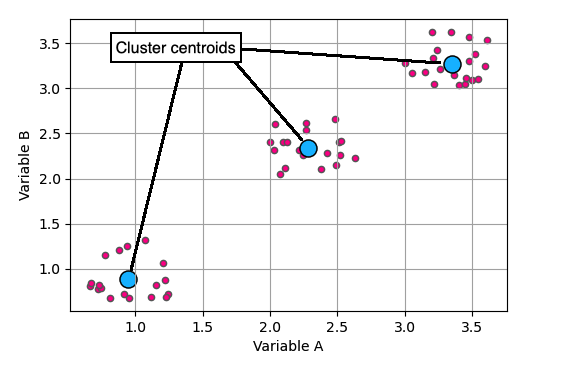
k-means-clustering
Observaties en clustercentra
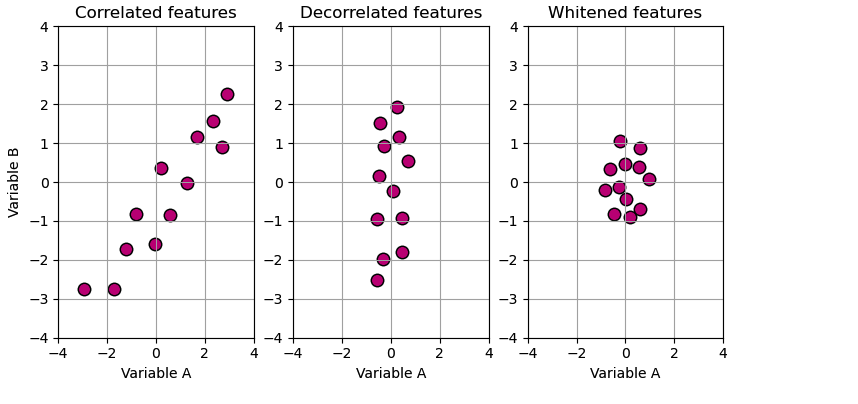
Data whitening: decorrelatie en rescaling
Voor k-means: Data whitening
- Decorreleer
obs - Reschaal elke dimensie van
obsmet z'n std-dev
Voorbeeld van whitening en k-means
- Productie-activiteit met meerdere processen
- Bekijk de impact van
Process 1