Twitter-tekst verwerken
Socialemediagegevens analyseren in R

Vivek Vijayaraghavan
Data Science Coach
Stappen in tekstverwerking

Stappen in tekstverwerking

Stappen in tekstverwerking
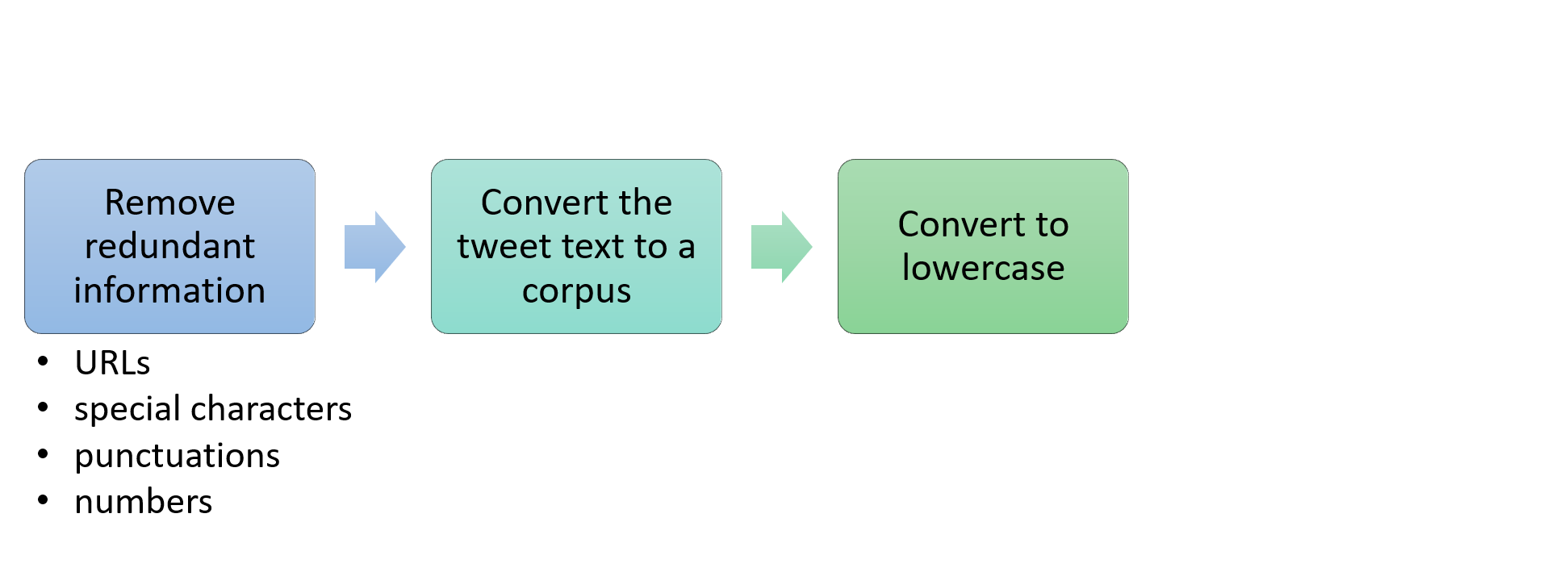
Stappen in tekstverwerking
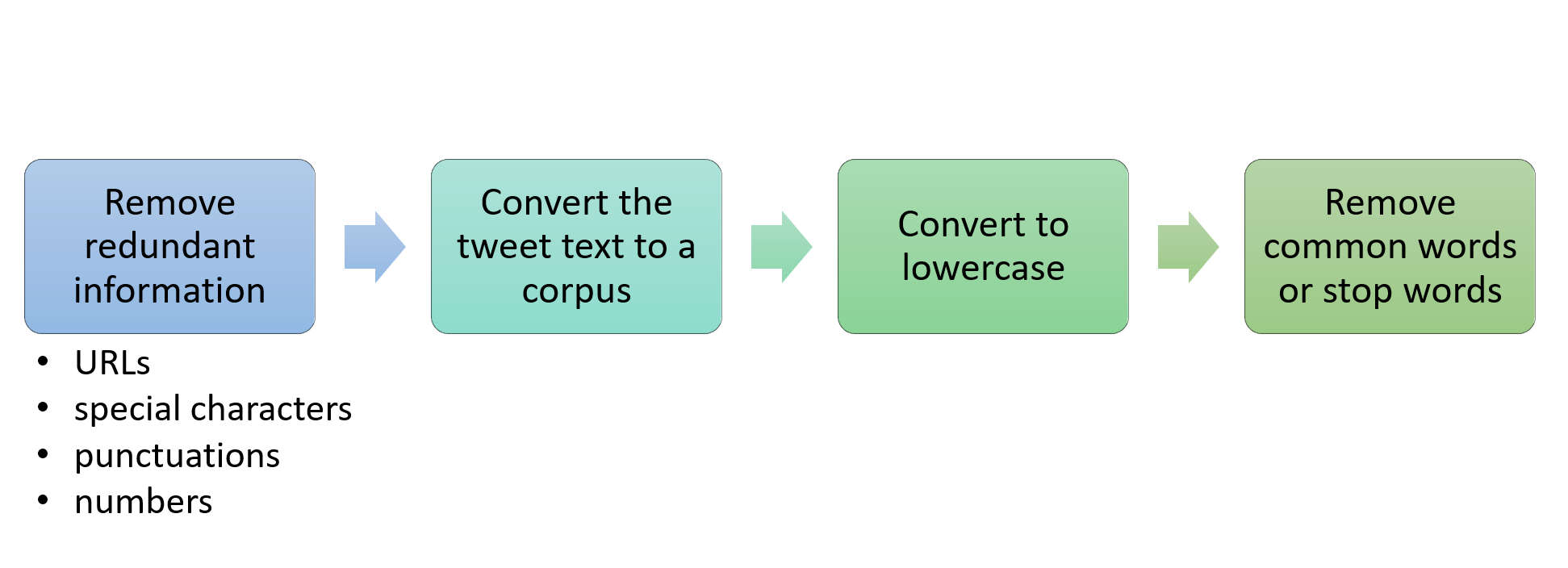
Wat zijn stopwoorden?
- Stopwoorden zijn veelvoorkomende woorden zoals a, an, and, but
# Common stop words in English
stopwords("english")


