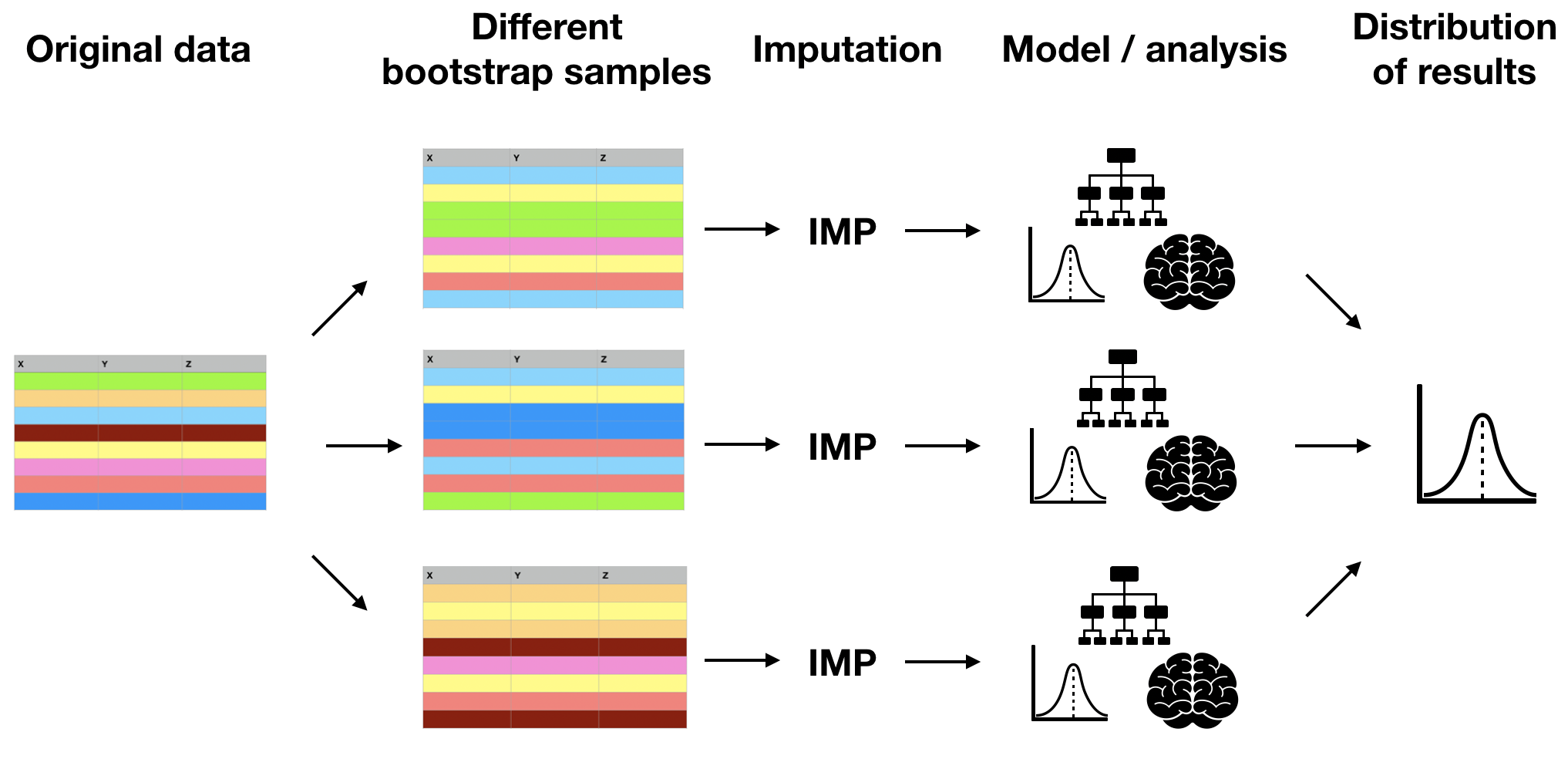
Meervoudige imputatie via bootstrapping
Omgaan met missende data met imputaties in R

Michal Oleszak
Machine Learning Engineer
Onzekerheid door imputatie
- Imputatie is meestal de eerste stap vóór analyse of modelleren.
- Missende waarden worden met onzekerheid geschat.
- Houd rekening met die onzekerheid in alle analyses op geïmputeerde data.

In bijna de helft van de studies verdwijnen kernresultaten
Bootstrap
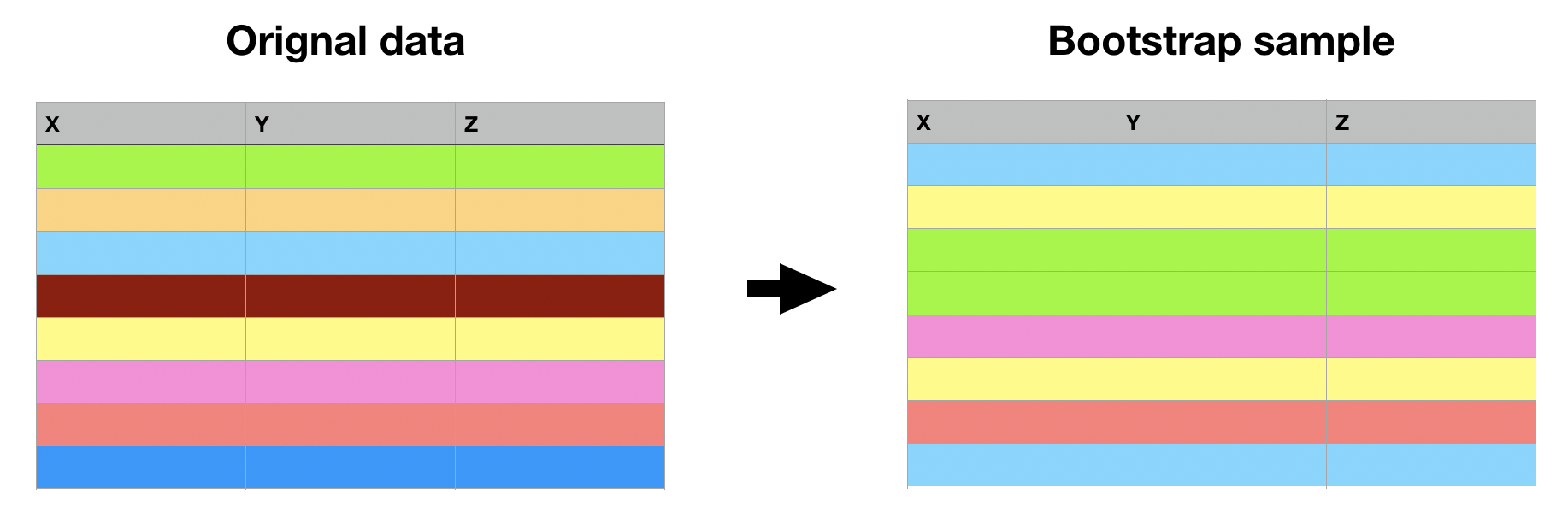
Bootstrapping = rijen trekken met teruglegging tot originele grootte
Meervoudige imputatie via bootstrapping
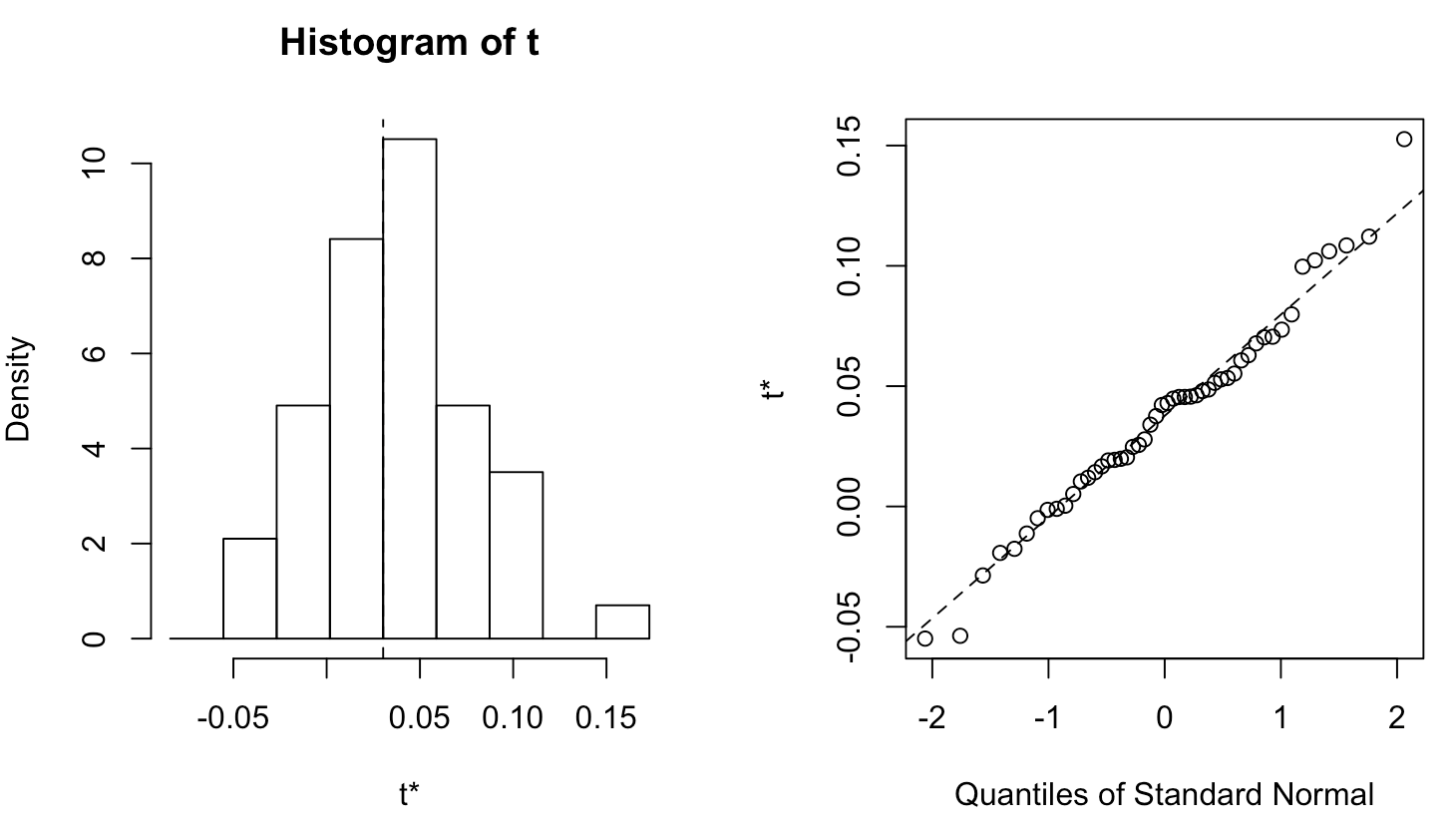
Bootstrapresultaten plotten
plot(boot_results)