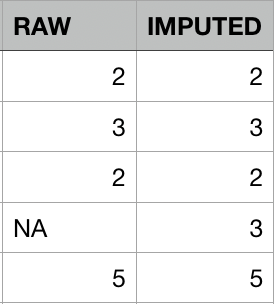
Gemiddelde-imputatie
Omgaan met missende data met imputaties in R

Michal Oleszak
Machine Learning Engineer
Gemiddelde-imputatie
Gemiddelde-imputatie werkt goed voor tijdreeksen die willekeurig schommelen rond een langetermijngemiddelde.
Voor dwarsdoorsnede-data is gemiddelde-imputatie vaak een slechte keuze:
- Tast relaties tussen variabelen aan.
- Geen variantie in de geïmputeerde waarden.
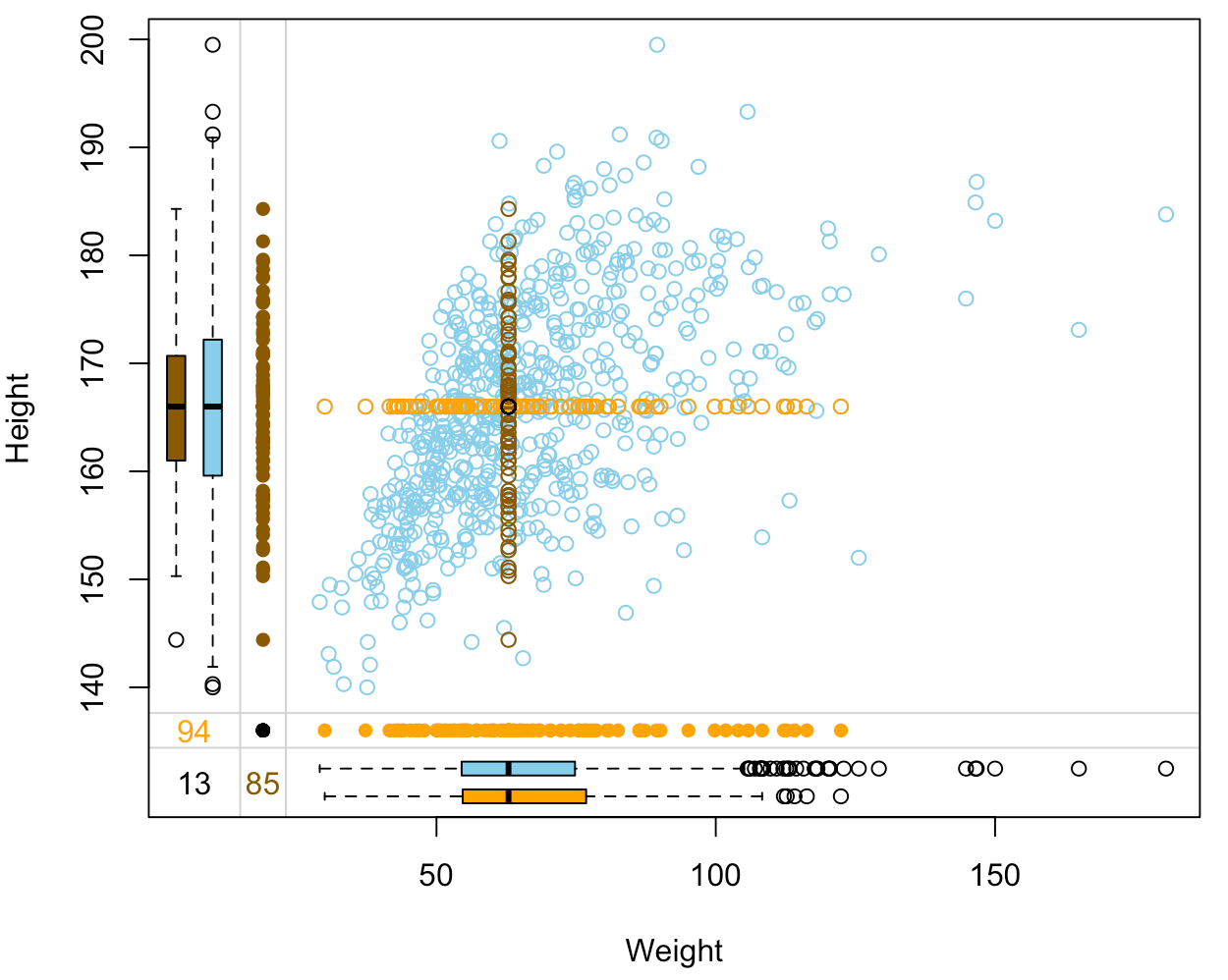
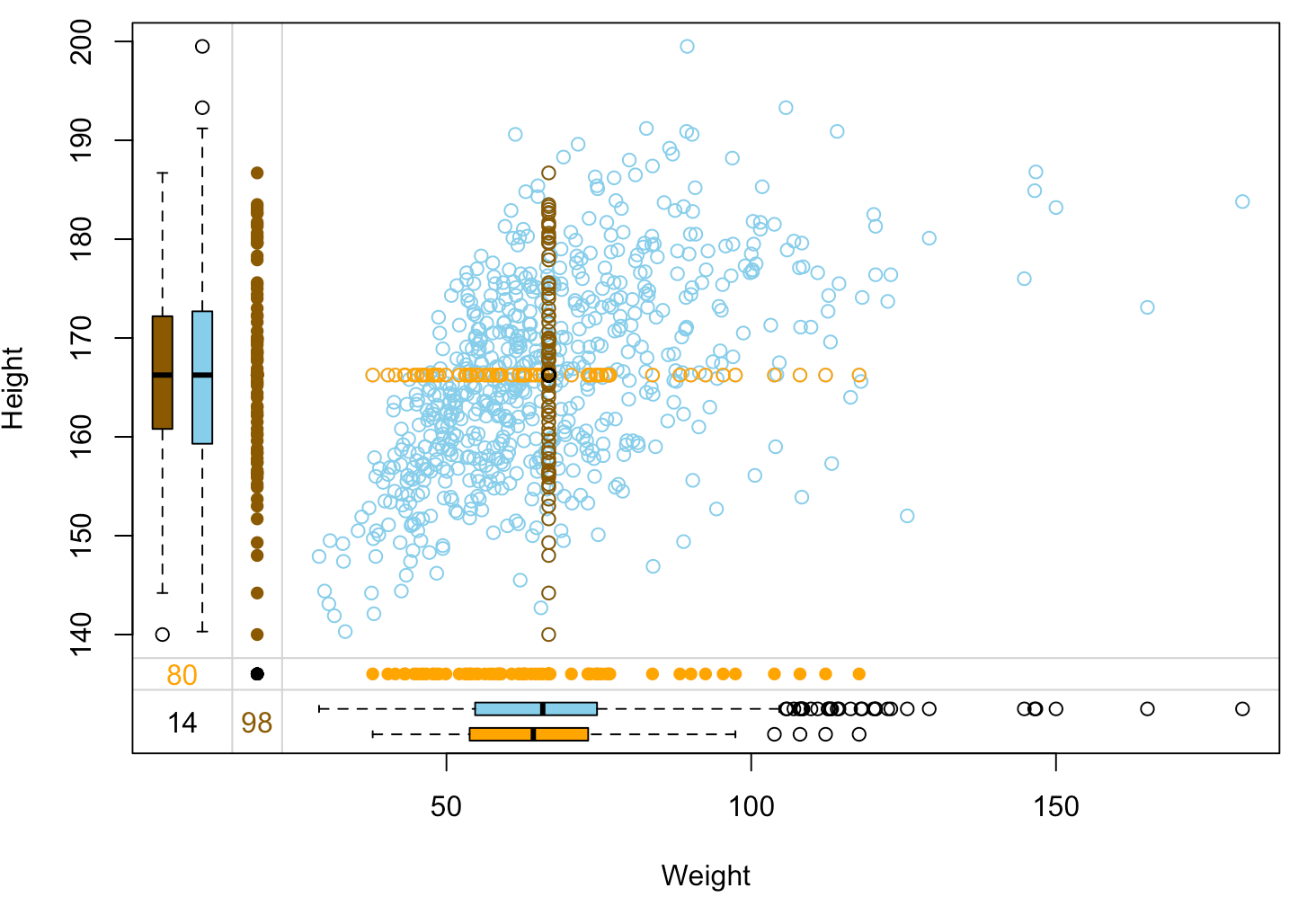
Imputatiekwaliteit beoordelen: margin plot
nhanes_imp %>% select(Weight, Height, Height_imp, Weight_imp) %>% marginplot(delimiter="imp")
Mediaan- en modus-imputatie