Categorische data anonimiseren
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Instructor
Generalisatie
Age Gender Department Condition
0 30 F Finance Anxiety disorders
1 42 M Production Bronchitis
2 35 F Marketing Dysthymia
3 39 F Production Dysthymia
4 40 M Marketing Flu
Age Gender Department Condition
0 <40 F Finance Anxiety disorders
1 >=40 M Production Bronquitis
2 <40 F Finance Dysthymia
3 <40 F Production Dysthymia
4 >=40 M Marketing Flu
Generalisatie van categorische data
# Bekijk de dataset
hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Life Sciences 2
2 37 Travel_Rarely Research & Development Other 4
3 33 Travel_Frequently Research & Development Life Sciences 5
4 27 Travel_Rarely Research & Development Medical 7
Categorische data
Beperkt of vast aantal mogelijke waarden.
- ras
- gender
- woonplaats
- leeftijdsgroep
- opleidingsniveau
- films en voorkeuren
Categorische data anonimiseren
Categorische data anonimiseren
Department EducationField
0 Sales Life Sciences
1 Research & Development Life Sciences
2 Research & Development Other
3 Research & Development Life Sciences
4 Research & Development Medical
Originele dataset
Department EducationField
0 Sales Medical
1 Research & Development Marketing
2 Research & Development Life Sciences
3 Research & Development Other
4 Research & Development Life Sciences
Resultaat na sampling uit de kansverdeling van de kolom educationField in de originele dataset.
Steekproeven uit data
Het U.S. Census publiceert steekproeven van data die ze over burgers verzamelen.
Maakt grootschalige statistiek mogelijk:
- gemiddelden
- varianties
- clusters
Verken de verdeling
# Toon de absolute frequenties van elke unieke waarde
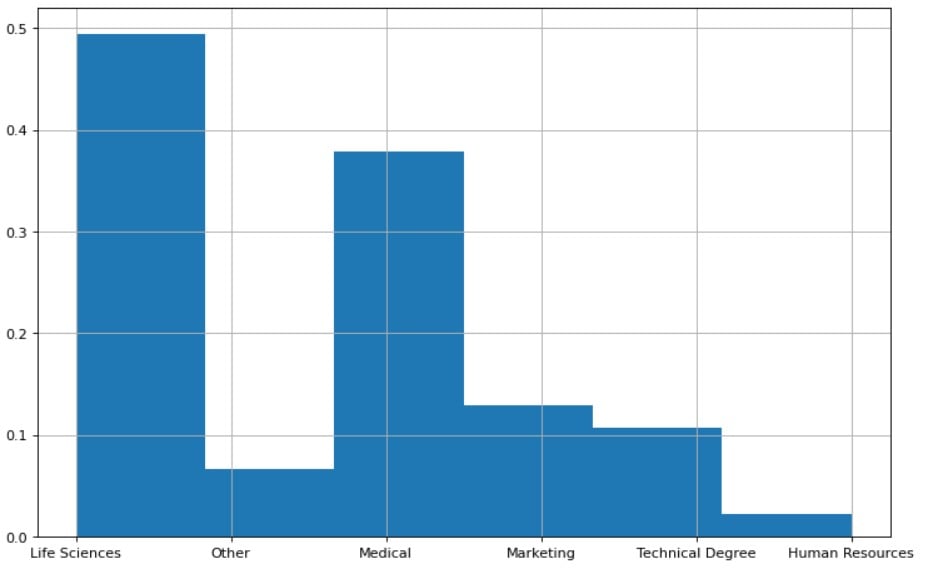
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
Verken de verdeling
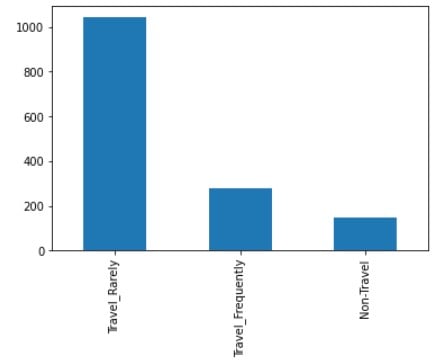
# Genereer een staafdiagram voor de categorieën
df['BusinessTravel'].value_counts().plot(kind='bar')
Verken de verdeling
# Verkrijg de absolute frequenties van elke unieke waarde
counts = hr['EducationField'].value_counts()
# Print de lijst met indexen
print(counts.index)
Index(['Life Sciences', 'Medical', 'Marketing',
'Technical Degree', 'Other', 'Human Resources'],
dtype='object')
Verken de verdeling
# Kansverdeling van elke unieke waarde
counts = df['EducationField'].value_counts(normalize=True)
Life Sciences 0.412245
Medical 0.315646
Marketing 0.108163
Technical Degree 0.089796
Other 0.055782
Human Resources 0.018367
Name: EducationField, dtype: float64
Verken de verdeling
# Waarden van de frequenties van elke unieke waarde
df['EducationField'].value_counts(normalize=True).values
array([0.4122449 , 0.31564626, 0.10816327, 0.08979592, 0.05578231,
0.01836735])
Sampling uit dezelfde verdeling
# Sample uit een kansverdeling hr_sample['EducationField']= np.random.choice(counts.index, p=counts.values, size=len(hr))# Bekijk de resulterende dataset hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Medical 2
2 37 Travel_Rarely Research & Development Marketing 4
3 33 Travel_Frequently Research & Development Technical Degree 5
4 27 Travel_Rarely Research & Development Medical 7
Sampling uit dezelfde verdeling
# Toon de absolute frequenties van elke categorie
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
# Toon de frequenties van de resulterende kolom
hr_sample['EducationField'].value_counts()
Life Sciences 604
Medical 493
Marketing 158
Technical Degree 120
Other 61
Human Resources 34
Name: EducationField, dtype: int64
Laten we oefenen!
Dataprivacy en anonimisering in Python

