Synthetische datasets maken met scikit-learn
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Data engineer
Datasets genereren met Scikit-learn
We kunnen datasets maken die samplen uit kansverdelingen
Zoals de normale verdeling
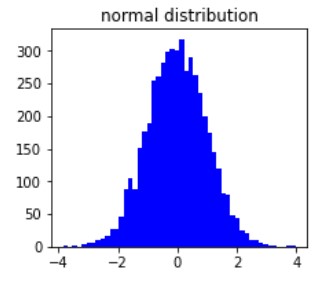
Normale verdeling
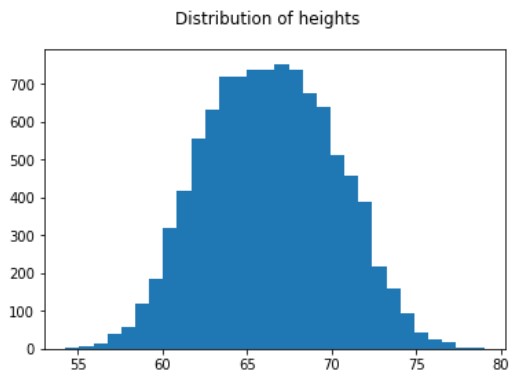
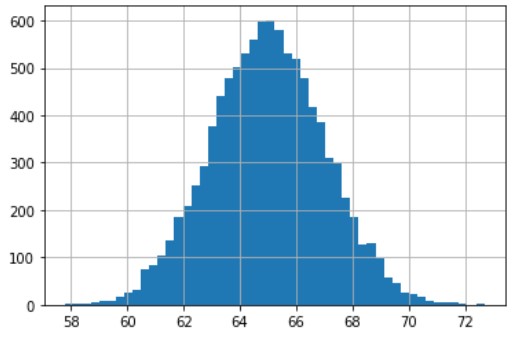
Steekproef uit een normale verdeling
# Draw histogram to see the resulting heights distribution
new_measures['Height'].hist(bins=50)
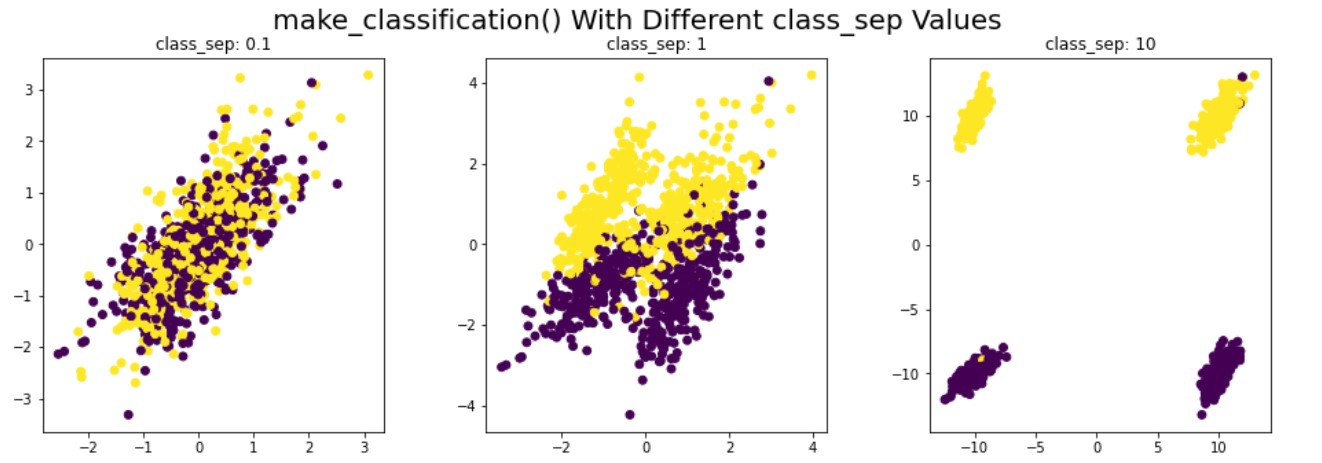
Synthetische data voor classificatie
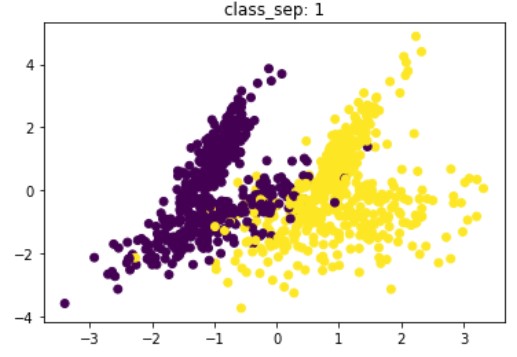
Synthetische data voor classificatie
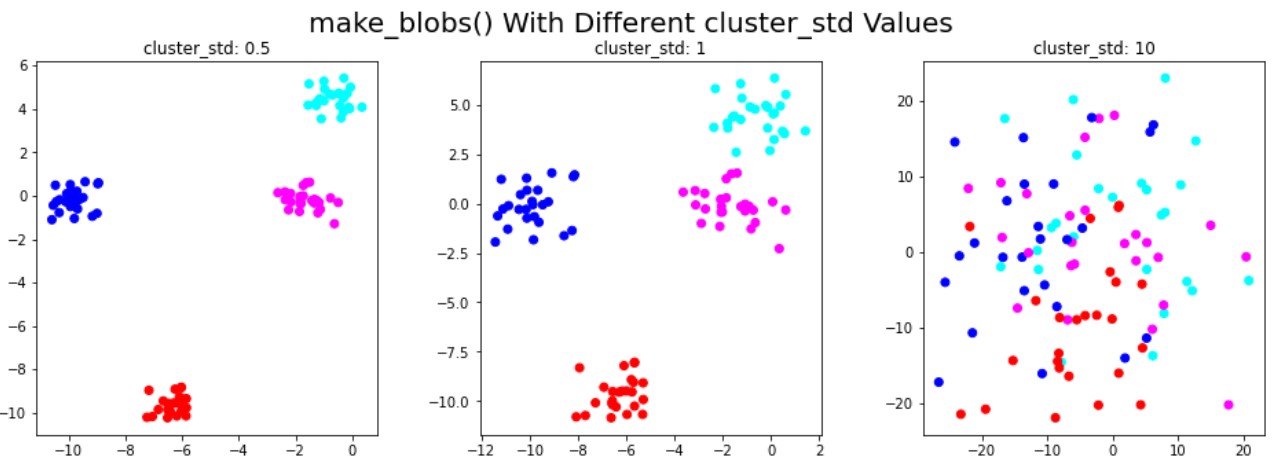
Synthetische data voor clustering
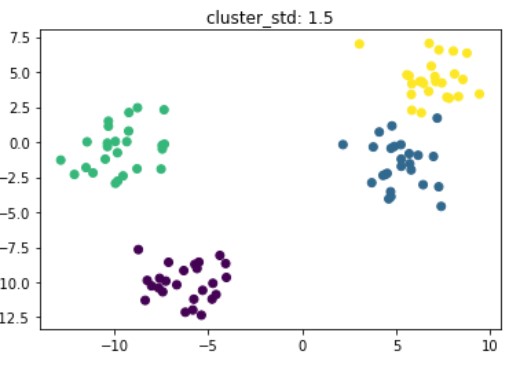
Synthetische data voor clustering